 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeText in the Dark: Extremely Low-Light Text Image Enhancement
Apr 22, 2024



Extremely low-light text images are common in natural scenes, making scene text detection and recognition challenging. One solution is to enhance these images using low-light image enhancement methods before text extraction. However, previous methods often do not try to particularly address the significance of low-level features, which are crucial for optimal performance on downstream scene text tasks. Further research is also hindered by the lack of extremely low-light text datasets. To address these limitations, we propose a novel encoder-decoder framework with an edge-aware attention module to focus on scene text regions during enhancement. Our proposed method uses novel text detection and edge reconstruction losses to emphasize low-level scene text features, leading to successful text extraction. Additionally, we present a Supervised Deep Curve Estimation (Supervised-DCE) model to synthesize extremely low-light images based on publicly available scene text datasets such as ICDAR15 (IC15). We also labeled texts in the extremely low-light See In the Dark (SID) and ordinary LOw-Light (LOL) datasets to allow for objective assessment of extremely low-light image enhancement through scene text tasks. Extensive experiments show that our model outperforms state-of-the-art methods in terms of both image quality and scene text metrics on the widely-used LOL, SID, and synthetic IC15 datasets. Code and dataset will be released publicly at https://github.com/chunchet-ng/Text-in-the-Dark.
Extremely Low-light Image Enhancement with Scene Text Restoration
Apr 01, 2022
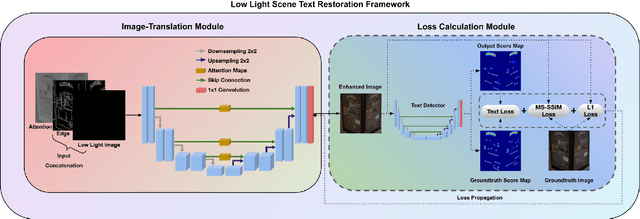


Deep learning-based methods have made impressive progress in enhancing extremely low-light images - the image quality of the reconstructed images has generally improved. However, we found out that most of these methods could not sufficiently recover the image details, for instance, the texts in the scene. In this paper, a novel image enhancement framework is proposed to precisely restore the scene texts, as well as the overall quality of the image simultaneously under extremely low-light images conditions. Mainly, we employed a self-regularised attention map, an edge map, and a novel text detection loss. In addition, leveraging synthetic low-light images is beneficial for image enhancement on the genuine ones in terms of text detection. The quantitative and qualitative experimental results have shown that the proposed model outperforms state-of-the-art methods in image restoration, text detection, and text spotting on See In the Dark and ICDAR15 datasets.