 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVAGNet: Grounding 3D Affordance from Human-Object Interactions in Videos
Feb 24, 20263D object affordance grounding aims to identify regions on 3D objects that support human-object interaction (HOI), a capability essential to embodied visual reasoning. However, most existing approaches rely on static visual or textual cues, neglecting that affordances are inherently defined by dynamic actions. As a result, they often struggle to localize the true contact regions involved in real interactions. We take a different perspective. Humans learn how to use objects by observing and imitating actions, not just by examining shapes. Motivated by this intuition, we introduce video-guided 3D affordance grounding, which leverages dynamic interaction sequences to provide functional supervision. To achieve this, we propose VAGNet, a framework that aligns video-derived interaction cues with 3D structure to resolve ambiguities that static cues cannot address. To support this new setting, we introduce PVAD, the first HOI video-3D pairing affordance dataset, providing functional supervision unavailable in prior works. Extensive experiments on PVAD show that VAGNet achieves state-of-the-art performance, significantly outperforming static-based baselines. The code and dataset will be open publicly.
Stratify: Rethinking Federated Learning for Non-IID Data through Balanced Sampling
Apr 18, 2025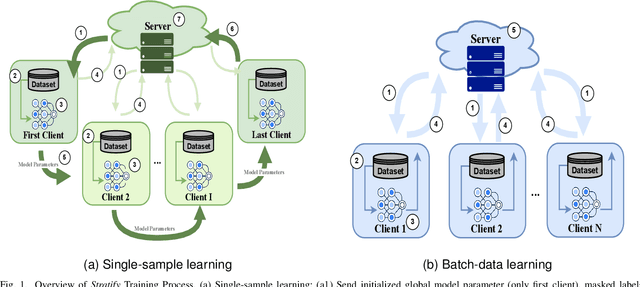
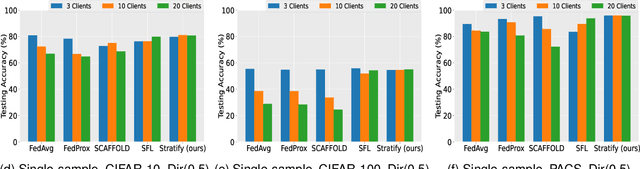
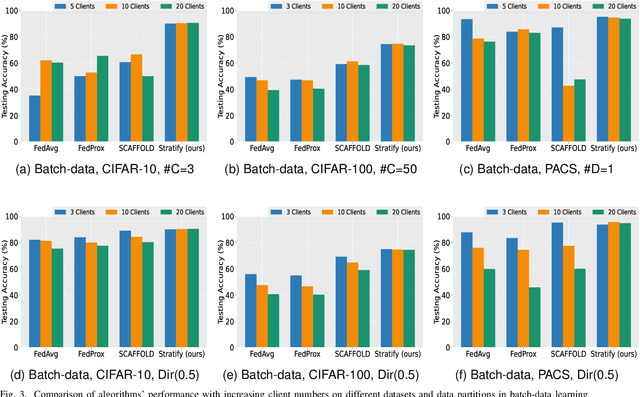
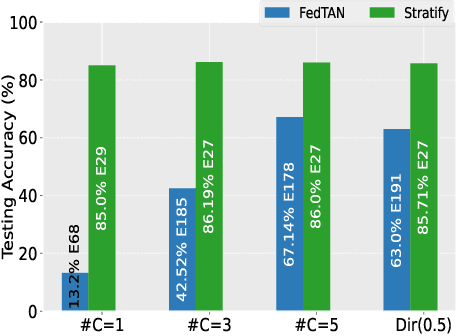
Federated Learning (FL) on non-independently and identically distributed (non-IID) data remains a critical challenge, as existing approaches struggle with severe data heterogeneity. Current methods primarily address symptoms of non-IID by applying incremental adjustments to Federated Averaging (FedAvg), rather than directly resolving its inherent design limitations. Consequently, performance significantly deteriorates under highly heterogeneous conditions, as the fundamental issue of imbalanced exposure to diverse class and feature distributions remains unresolved. This paper introduces Stratify, a novel FL framework designed to systematically manage class and feature distributions throughout training, effectively tackling the root cause of non-IID challenges. Inspired by classical stratified sampling, our approach employs a Stratified Label Schedule (SLS) to ensure balanced exposure across labels, significantly reducing bias and variance in aggregated gradients. Complementing SLS, we propose a label-aware client selection strategy, restricting participation exclusively to clients possessing data relevant to scheduled labels. Additionally, Stratify incorporates a fine-grained, high-frequency update scheme, accelerating convergence and further mitigating data heterogeneity. To uphold privacy, we implement a secure client selection protocol leveraging homomorphic encryption, enabling precise global label statistics without disclosing sensitive client information. Extensive evaluations on MNIST, CIFAR-10, CIFAR-100, Tiny-ImageNet, COVTYPE, PACS, and Digits-DG demonstrate that Stratify attains performance comparable to IID baselines, accelerates convergence, and reduces client-side computation compared to state-of-the-art methods, underscoring its practical effectiveness in realistic federated learning scenarios.
InteractEdit: Zero-Shot Editing of Human-Object Interactions in Images
Mar 12, 2025

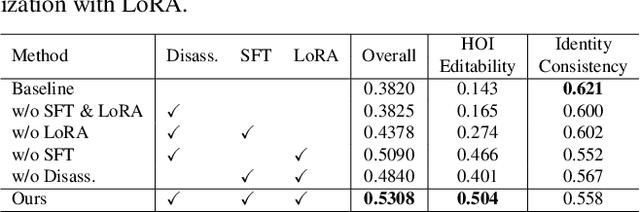

This paper presents InteractEdit, a novel framework for zero-shot Human-Object Interaction (HOI) editing, addressing the challenging task of transforming an existing interaction in an image into a new, desired interaction while preserving the identities of the subject and object. Unlike simpler image editing scenarios such as attribute manipulation, object replacement or style transfer, HOI editing involves complex spatial, contextual, and relational dependencies inherent in humans-objects interactions. Existing methods often overfit to the source image structure, limiting their ability to adapt to the substantial structural modifications demanded by new interactions. To address this, InteractEdit decomposes each scene into subject, object, and background components, then employs Low-Rank Adaptation (LoRA) and selective fine-tuning to preserve pretrained interaction priors while learning the visual identity of the source image. This regularization strategy effectively balances interaction edits with identity consistency. We further introduce IEBench, the most comprehensive benchmark for HOI editing, which evaluates both interaction editing and identity preservation. Our extensive experiments show that InteractEdit significantly outperforms existing methods, establishing a strong baseline for future HOI editing research and unlocking new possibilities for creative and practical applications. Code will be released upon publication.
Yuan: Yielding Unblemished Aesthetics Through A Unified Network for Visual Imperfections Removal in Generated Images
Jan 15, 2025



Generative AI presents transformative potential across various domains, from creative arts to scientific visualization. However, the utility of AI-generated imagery is often compromised by visual flaws, including anatomical inaccuracies, improper object placements, and misplaced textual elements. These imperfections pose significant challenges for practical applications. To overcome these limitations, we introduce \textit{Yuan}, a novel framework that autonomously corrects visual imperfections in text-to-image synthesis. \textit{Yuan} uniquely conditions on both the textual prompt and the segmented image, generating precise masks that identify areas in need of refinement without requiring manual intervention -- a common constraint in previous methodologies. Following the automated masking process, an advanced inpainting module seamlessly integrates contextually coherent content into the identified regions, preserving the integrity and fidelity of the original image and associated text prompts. Through extensive experimentation on publicly available datasets such as ImageNet100 and Stanford Dogs, along with a custom-generated dataset, \textit{Yuan} demonstrated superior performance in eliminating visual imperfections. Our approach consistently achieved higher scores in quantitative metrics, including NIQE, BRISQUE, and PI, alongside favorable qualitative evaluations. These results underscore \textit{Yuan}'s potential to significantly enhance the quality and applicability of AI-generated images across diverse fields.
Chirpy3D: Continuous Part Latents for Creative 3D Bird Generation
Jan 07, 2025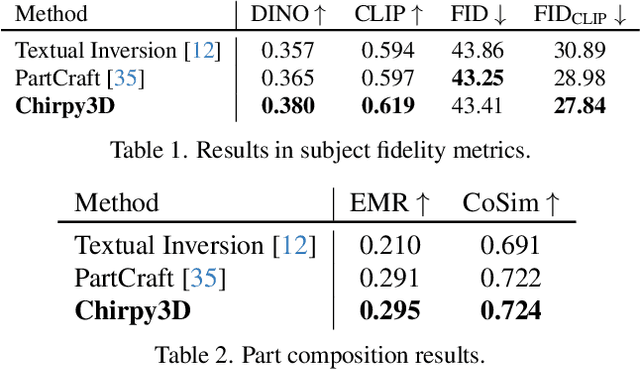
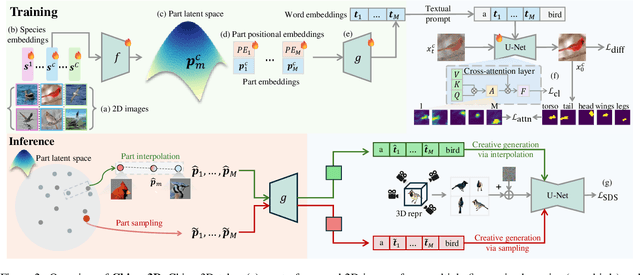
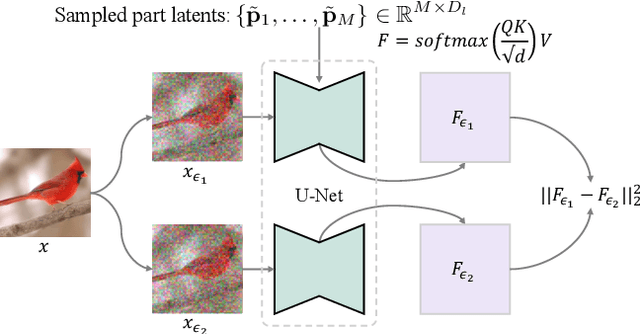
In this paper, we push the boundaries of fine-grained 3D generation into truly creative territory. Current methods either lack intricate details or simply mimic existing objects -- we enable both. By lifting 2D fine-grained understanding into 3D through multi-view diffusion and modeling part latents as continuous distributions, we unlock the ability to generate entirely new, yet plausible parts through interpolation and sampling. A self-supervised feature consistency loss further ensures stable generation of these unseen parts. The result is the first system capable of creating novel 3D objects with species-specific details that transcend existing examples. While we demonstrate our approach on birds, the underlying framework extends beyond things that can chirp! Code will be released at https://github.com/kamwoh/chirpy3d.
Protégé: Learn and Generate Basic Makeup Styles with Generative Adversarial Networks (GANs)
Dec 29, 2024



Makeup is no longer confined to physical application; people now use mobile apps to digitally apply makeup to their photos, which they then share on social media. However, while this shift has made makeup more accessible, designing diverse makeup styles tailored to individual faces remains a challenge. This challenge currently must still be done manually by humans. Existing systems, such as makeup recommendation engines and makeup transfer techniques, offer limitations in creating innovative makeups for different individuals "intuitively" -- significant user effort and knowledge needed and limited makeup options available in app. Our motivation is to address this challenge by proposing Prot\'eg\'e, a new makeup application, leveraging recent generative model -- GANs to learn and automatically generate makeup styles. This is a task that existing makeup applications (i.e., makeup recommendation systems using expert system and makeup transfer methods) are unable to perform. Extensive experiments has been conducted to demonstrate the capability of Prot\'eg\'e in learning and creating diverse makeups, providing a convenient and intuitive way, marking a significant leap in digital makeup technology!
A few-shot Label Unlearning in Vertical Federated Learning
Oct 14, 2024



This paper addresses the critical challenge of unlearning in Vertical Federated Learning (VFL), an area that has received limited attention compared to horizontal federated learning. We introduce the first approach specifically designed to tackle label unlearning in VFL, focusing on scenarios where the active party aims to mitigate the risk of label leakage. Our method leverages a limited amount of labeled data, utilizing manifold mixup to augment the forward embedding of insufficient data, followed by gradient ascent on the augmented embeddings to erase label information from the models. This combination of augmentation and gradient ascent enables high unlearning effectiveness while maintaining efficiency, completing the unlearning procedure within seconds. Extensive experiments conducted on diverse datasets, including MNIST, CIFAR10, CIFAR100, and ModelNet, validate the efficacy and scalability of our approach. This work represents a significant advancement in federated learning, addressing the unique challenges of unlearning in VFL while preserving both privacy and computational efficiency.
Ferrari: Federated Feature Unlearning via Optimizing Feature Sensitivity
May 29, 2024The advent of Federated Learning (FL) highlights the practical necessity for the 'right to be forgotten' for all clients, allowing them to request data deletion from the machine learning model's service provider. This necessity has spurred a growing demand for Federated Unlearning (FU). Feature unlearning has gained considerable attention due to its applications in unlearning sensitive features, backdoor features, and bias features. Existing methods employ the influence function to achieve feature unlearning, which is impractical for FL as it necessitates the participation of other clients in the unlearning process. Furthermore, current research lacks an evaluation of the effectiveness of feature unlearning. To address these limitations, we define feature sensitivity in the evaluation of feature unlearning according to Lipschitz continuity. This metric characterizes the rate of change or sensitivity of the model output to perturbations in the input feature. We then propose an effective federated feature unlearning framework called Ferrari, which minimizes feature sensitivity. Extensive experimental results and theoretical analysis demonstrate the effectiveness of Ferrari across various feature unlearning scenarios, including sensitive, backdoor, and biased features.
Text in the Dark: Extremely Low-Light Text Image Enhancement
Apr 22, 2024



Extremely low-light text images are common in natural scenes, making scene text detection and recognition challenging. One solution is to enhance these images using low-light image enhancement methods before text extraction. However, previous methods often do not try to particularly address the significance of low-level features, which are crucial for optimal performance on downstream scene text tasks. Further research is also hindered by the lack of extremely low-light text datasets. To address these limitations, we propose a novel encoder-decoder framework with an edge-aware attention module to focus on scene text regions during enhancement. Our proposed method uses novel text detection and edge reconstruction losses to emphasize low-level scene text features, leading to successful text extraction. Additionally, we present a Supervised Deep Curve Estimation (Supervised-DCE) model to synthesize extremely low-light images based on publicly available scene text datasets such as ICDAR15 (IC15). We also labeled texts in the extremely low-light See In the Dark (SID) and ordinary LOw-Light (LOL) datasets to allow for objective assessment of extremely low-light image enhancement through scene text tasks. Extensive experiments show that our model outperforms state-of-the-art methods in terms of both image quality and scene text metrics on the widely-used LOL, SID, and synthetic IC15 datasets. Code and dataset will be released publicly at https://github.com/chunchet-ng/Text-in-the-Dark.
Gorgeous: Create Your Desired Character Facial Makeup from Any Ideas
Apr 22, 2024



Contemporary makeup transfer methods primarily focus on replicating makeup from one face to another, considerably limiting their use in creating diverse and creative character makeup essential for visual storytelling. Such methods typically fail to address the need for uniqueness and contextual relevance, specifically aligning with character and story settings as they depend heavily on existing facial makeup in reference images. This approach also presents a significant challenge when attempting to source a perfectly matched facial makeup style, further complicating the creation of makeup designs inspired by various story elements, such as theme, background, and props that do not necessarily feature faces. To address these limitations, we introduce $Gorgeous$, a novel diffusion-based makeup application method that goes beyond simple transfer by innovatively crafting unique and thematic facial makeup. Unlike traditional methods, $Gorgeous$ does not require the presence of a face in the reference images. Instead, it draws artistic inspiration from a minimal set of three to five images, which can be of any type, and transforms these elements into practical makeup applications directly on the face. Our comprehensive experiments demonstrate that $Gorgeous$ can effectively generate distinctive character facial makeup inspired by the chosen thematic reference images. This approach opens up new possibilities for integrating broader story elements into character makeup, thereby enhancing the narrative depth and visual impact in storytelling.