 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInteractEdit: Zero-Shot Editing of Human-Object Interactions in Images
Mar 12, 2025

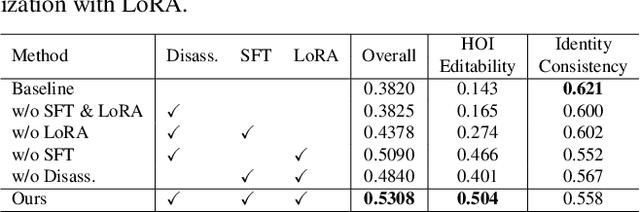

This paper presents InteractEdit, a novel framework for zero-shot Human-Object Interaction (HOI) editing, addressing the challenging task of transforming an existing interaction in an image into a new, desired interaction while preserving the identities of the subject and object. Unlike simpler image editing scenarios such as attribute manipulation, object replacement or style transfer, HOI editing involves complex spatial, contextual, and relational dependencies inherent in humans-objects interactions. Existing methods often overfit to the source image structure, limiting their ability to adapt to the substantial structural modifications demanded by new interactions. To address this, InteractEdit decomposes each scene into subject, object, and background components, then employs Low-Rank Adaptation (LoRA) and selective fine-tuning to preserve pretrained interaction priors while learning the visual identity of the source image. This regularization strategy effectively balances interaction edits with identity consistency. We further introduce IEBench, the most comprehensive benchmark for HOI editing, which evaluates both interaction editing and identity preservation. Our extensive experiments show that InteractEdit significantly outperforms existing methods, establishing a strong baseline for future HOI editing research and unlocking new possibilities for creative and practical applications. Code will be released upon publication.
InteractDiffusion: Interaction Control in Text-to-Image Diffusion Models
Dec 10, 2023



Large-scale text-to-image (T2I) diffusion models have showcased incredible capabilities in generating coherent images based on textual descriptions, enabling vast applications in content generation. While recent advancements have introduced control over factors such as object localization, posture, and image contours, a crucial gap remains in our ability to control the interactions between objects in the generated content. Well-controlling interactions in generated images could yield meaningful applications, such as creating realistic scenes with interacting characters. In this work, we study the problems of conditioning T2I diffusion models with Human-Object Interaction (HOI) information, consisting of a triplet label (person, action, object) and corresponding bounding boxes. We propose a pluggable interaction control model, called InteractDiffusion that extends existing pre-trained T2I diffusion models to enable them being better conditioned on interactions. Specifically, we tokenize the HOI information and learn their relationships via interaction embeddings. A conditioning self-attention layer is trained to map HOI tokens to visual tokens, thereby conditioning the visual tokens better in existing T2I diffusion models. Our model attains the ability to control the interaction and location on existing T2I diffusion models, which outperforms existing baselines by a large margin in HOI detection score, as well as fidelity in FID and KID. Project page: https://jiuntian.github.io/interactdiffusion.
Unsupervised Hashing via Similarity Distribution Calibration
Feb 15, 2023Existing unsupervised hashing methods typically adopt a feature similarity preservation paradigm. As a result, they overlook the intrinsic similarity capacity discrepancy between the continuous feature and discrete hash code spaces. Specifically, since the feature similarity distribution is intrinsically biased (e.g., moderately positive similarity scores on negative pairs), the hash code similarities of positive and negative pairs often become inseparable (i.e., the similarity collapse problem). To solve this problem, in this paper a novel Similarity Distribution Calibration (SDC) method is introduced. Instead of matching individual pairwise similarity scores, SDC aligns the hash code similarity distribution towards a calibration distribution (e.g., beta distribution) with sufficient spread across the entire similarity capacity/range, to alleviate the similarity collapse problem. Extensive experiments show that our SDC outperforms the state-of-the-art alternatives on both coarse category-level and instance-level image retrieval tasks, often by a large margin. Code is available at https://github.com/kamwoh/sdc.
One Loss for All: Deep Hashing with a Single Cosine Similarity based Learning Objective
Sep 29, 2021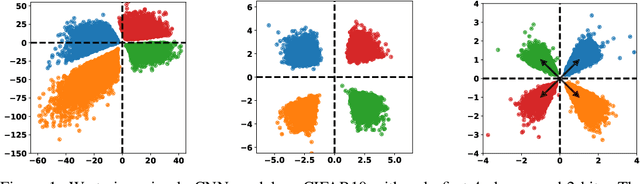
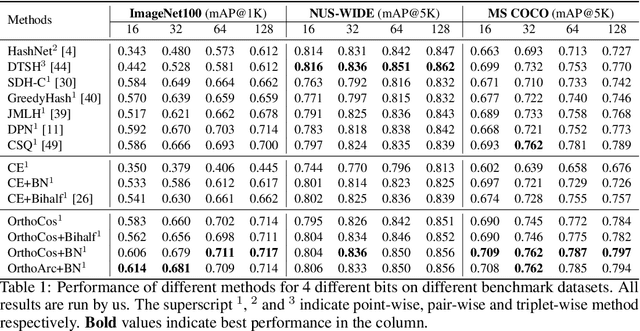
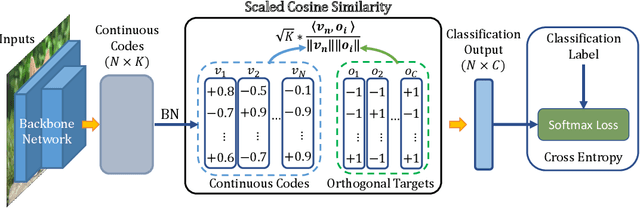
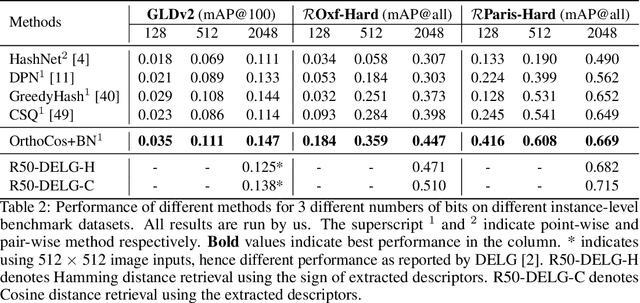
A deep hashing model typically has two main learning objectives: to make the learned binary hash codes discriminative and to minimize a quantization error. With further constraints such as bit balance and code orthogonality, it is not uncommon for existing models to employ a large number (>4) of losses. This leads to difficulties in model training and subsequently impedes their effectiveness. In this work, we propose a novel deep hashing model with only a single learning objective. Specifically, we show that maximizing the cosine similarity between the continuous codes and their corresponding binary orthogonal codes can ensure both hash code discriminativeness and quantization error minimization. Further, with this learning objective, code balancing can be achieved by simply using a Batch Normalization (BN) layer and multi-label classification is also straightforward with label smoothing. The result is an one-loss deep hashing model that removes all the hassles of tuning the weights of various losses. Importantly, extensive experiments show that our model is highly effective, outperforming the state-of-the-art multi-loss hashing models on three large-scale instance retrieval benchmarks, often by significant margins. Code is available at https://github.com/kamwoh/orthohash