 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGeometrically Consistent Multi-View Scene Generation from Freehand Sketches
Apr 15, 2026We tackle a new problem: generating geometrically consistent multi-view scenes from a single freehand sketch. Freehand sketches are the most geometrically impoverished input one could offer a multi-view generator. They convey scene intent through abstract strokes while introducing spatial distortions that actively conflict with any consistent 3D interpretation. No prior method attempts this; existing multi-view approaches require photographs or text, while sketch-to-3D methods need multiple views or costly per-scene optimisation. We address three compounding challenges; absent training data, the need for geometric reasoning from distorted 2D input, and cross-view consistency, through three mutually reinforcing contributions: (i) a curated dataset of $\sim$9k sketch-to-multiview samples, constructed via an automated generation and filtering pipeline; (ii) Parallel Camera-Aware Attention Adapters (CA3) that inject geometric inductive biases into the video transformer; and (iii) a Sparse Correspondence Supervision Loss (CSL) derived from Structure-from-Motion reconstructions. Our framework synthesizes all views in a single denoising process without requiring reference images, iterative refinement, or per-scene optimization. Our approach significantly outperforms state-of-the-art two-stage baselines, improving realism (FID) by over 60% and geometric consistency (Corr-Acc) by 23%, while providing up to a 3.7$\times$ inference speedup.
PerfGuard: A Performance-Aware Agent for Visual Content Generation
Jan 30, 2026The advancement of Large Language Model (LLM)-powered agents has enabled automated task processing through reasoning and tool invocation capabilities. However, existing frameworks often operate under the idealized assumption that tool executions are invariably successful, relying solely on textual descriptions that fail to distinguish precise performance boundaries and cannot adapt to iterative tool updates. This gap introduces uncertainty in planning and execution, particularly in domains like visual content generation (AIGC), where nuanced tool performance significantly impacts outcomes. To address this, we propose PerfGuard, a performance-aware agent framework for visual content generation that systematically models tool performance boundaries and integrates them into task planning and scheduling. Our framework introduces three core mechanisms: (1) Performance-Aware Selection Modeling (PASM), which replaces generic tool descriptions with a multi-dimensional scoring system based on fine-grained performance evaluations; (2) Adaptive Preference Update (APU), which dynamically optimizes tool selection by comparing theoretical rankings with actual execution rankings; and (3) Capability-Aligned Planning Optimization (CAPO), which guides the planner to generate subtasks aligned with performance-aware strategies. Experimental comparisons against state-of-the-art methods demonstrate PerfGuard's advantages in tool selection accuracy, execution reliability, and alignment with user intent, validating its robustness and practical utility for complex AIGC tasks. The project code is available at https://github.com/FelixChan9527/PerfGuard.
SynMind: Reducing Semantic Hallucination in fMRI-Based Image Reconstruction
Jan 25, 2026Recent advances in fMRI-based image reconstruction have achieved remarkable photo-realistic fidelity. Yet, a persistent limitation remains: while reconstructed images often appear naturalistic and holistically similar to the target stimuli, they frequently suffer from severe semantic misalignment -- salient objects are often replaced or hallucinated despite high visual quality. In this work, we address this limitation by rethinking the role of explicit semantic interpretation in fMRI decoding. We argue that existing methods rely too heavily on entangled visual embeddings which prioritize low-level appearance cues -- such as texture and global gist -- over explicit semantic identity. To overcome this, we parse fMRI signals into rich, sentence-level semantic descriptions that mirror the hierarchical and compositional nature of human visual understanding. We achieve this by leveraging grounded VLMs to generate synthetic, human-like, multi-granularity textual representations that capture object identities and spatial organization. Built upon this foundation, we propose SynMind, a framework that integrates these explicit semantic encodings with visual priors to condition a pretrained diffusion model. Extensive experiments demonstrate that SynMind outperforms state-of-the-art methods across most quantitative metrics. Notably, by offloading semantic reasoning to our text-alignment module, SynMind surpasses competing methods based on SDXL while using the much smaller Stable Diffusion 1.4 and a single consumer GPU. Large-scale human evaluations further confirm that SynMind produces reconstructions more consistent with human visual perception. Neurovisualization analyses reveal that SynMind engages broader and more semantically relevant brain regions, mitigating the over-reliance on high-level visual areas.
Amadeus: Autoregressive Model with Bidirectional Attribute Modelling for Symbolic Music
Aug 28, 2025Existing state-of-the-art symbolic music generation models predominantly adopt autoregressive or hierarchical autoregressive architectures, modelling symbolic music as a sequence of attribute tokens with unidirectional temporal dependencies, under the assumption of a fixed, strict dependency structure among these attributes. However, we observe that using different attributes as the initial token in these models leads to comparable performance. This suggests that the attributes of a musical note are, in essence, a concurrent and unordered set, rather than a temporally dependent sequence. Based on this insight, we introduce Amadeus, a novel symbolic music generation framework. Amadeus adopts a two-level architecture: an autoregressive model for note sequences and a bidirectional discrete diffusion model for attributes. To enhance performance, we propose Music Latent Space Discriminability Enhancement Strategy(MLSDES), incorporating contrastive learning constraints that amplify discriminability of intermediate music representations. The Conditional Information Enhancement Module (CIEM) simultaneously strengthens note latent vector representation via attention mechanisms, enabling more precise note decoding. We conduct extensive experiments on unconditional and text-conditioned generation tasks. Amadeus significantly outperforms SOTA models across multiple metrics while achieving at least 4$\times$ speed-up. Furthermore, we demonstrate training-free, fine-grained note attribute control feasibility using our model. To explore the upper performance bound of the Amadeus architecture, we compile the largest open-source symbolic music dataset to date, AMD (Amadeus MIDI Dataset), supporting both pre-training and fine-tuning.
SketchAnimator: Animate Sketch via Motion Customization of Text-to-Video Diffusion Models
Aug 10, 2025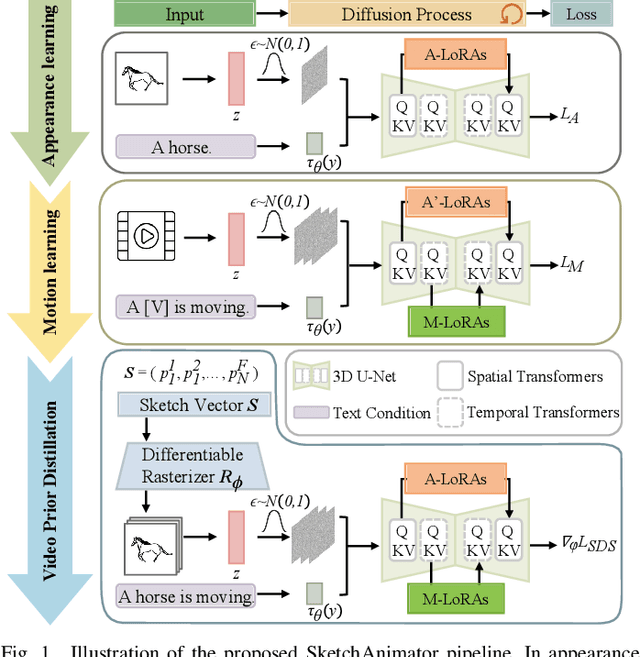
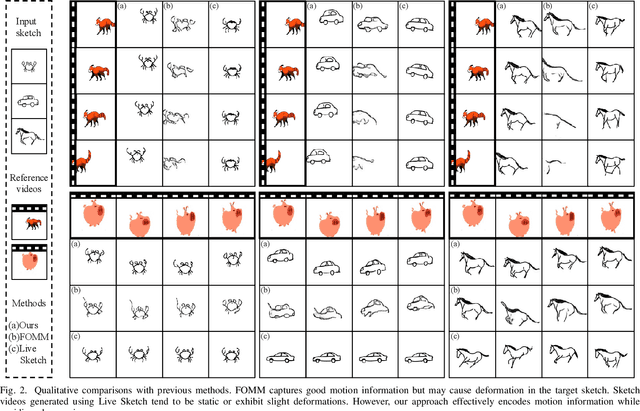
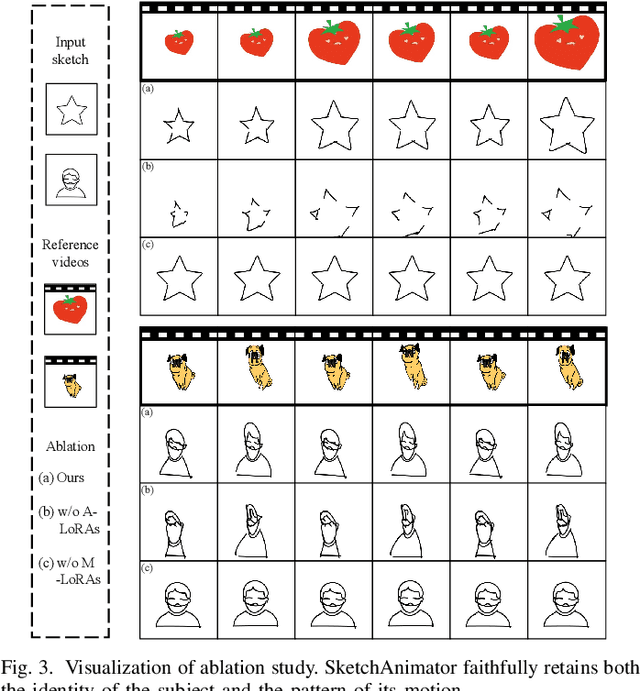
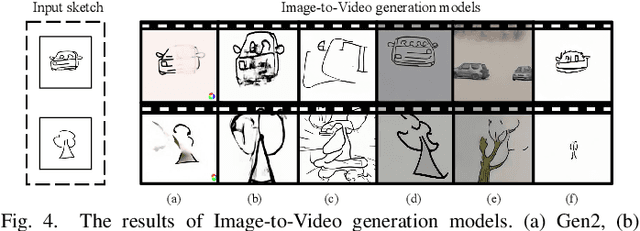
Sketching is a uniquely human tool for expressing ideas and creativity. The animation of sketches infuses life into these static drawings, opening a new dimension for designers. Animating sketches is a time-consuming process that demands professional skills and extensive experience, often proving daunting for amateurs. In this paper, we propose a novel sketch animation model SketchAnimator, which enables adding creative motion to a given sketch, like "a jumping car''. Namely, given an input sketch and a reference video, we divide the sketch animation into three stages: Appearance Learning, Motion Learning and Video Prior Distillation. In stages 1 and 2, we utilize LoRA to integrate sketch appearance information and motion dynamics from the reference video into the pre-trained T2V model. In the third stage, we utilize Score Distillation Sampling (SDS) to update the parameters of the Bezier curves in each sketch frame according to the acquired motion information. Consequently, our model produces a sketch video that not only retains the original appearance of the sketch but also mirrors the dynamic movements of the reference video. We compare our method with alternative approaches and demonstrate that it generates the desired sketch video under the challenge of one-shot motion customization.
Annotation-Free Human Sketch Quality Assessment
Jul 28, 2025As lovely as bunnies are, your sketched version would probably not do them justice (Fig.~\ref{fig:intro}). This paper recognises this very problem and studies sketch quality assessment for the first time -- letting you find these badly drawn ones. Our key discovery lies in exploiting the magnitude ($L_2$ norm) of a sketch feature as a quantitative quality metric. We propose Geometry-Aware Classification Layer (GACL), a generic method that makes feature-magnitude-as-quality-metric possible and importantly does it without the need for specific quality annotations from humans. GACL sees feature magnitude and recognisability learning as a dual task, which can be simultaneously optimised under a neat cross-entropy classification loss with theoretic guarantee. This gives GACL a nice geometric interpretation (the better the quality, the easier the recognition), and makes it agnostic to both network architecture changes and the underlying sketch representation. Through a large scale human study of 160,000 \doublecheck{trials}, we confirm the agreement between our GACL-induced metric and human quality perception. We further demonstrate how such a quality assessment capability can for the first time enable three practical sketch applications. Interestingly, we show GACL not only works on abstract visual representations such as sketch but also extends well to natural images on the problem of image quality assessment (IQA). Last but not least, we spell out the general properties of GACL as general-purpose data re-weighting strategy and demonstrate its applications in vertical problems such as noisy label cleansing. Code will be made publicly available at github.com/yanglan0225/SketchX-Quantifying-Sketch-Quality.
Doodle Your Keypoints: Sketch-Based Few-Shot Keypoint Detection
Jul 10, 2025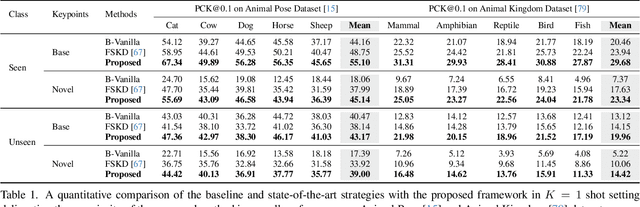
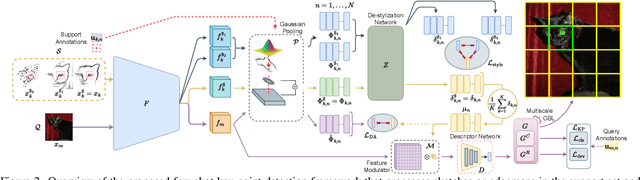
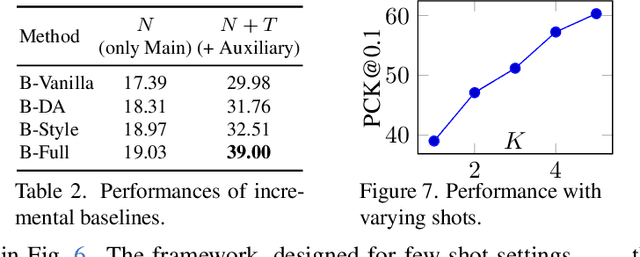
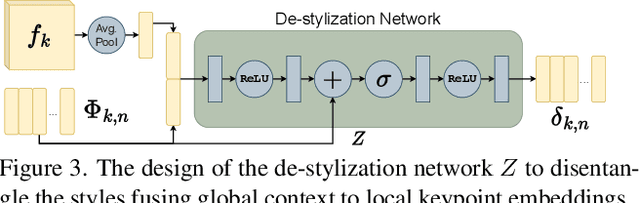
Keypoint detection, integral to modern machine perception, faces challenges in few-shot learning, particularly when source data from the same distribution as the query is unavailable. This gap is addressed by leveraging sketches, a popular form of human expression, providing a source-free alternative. However, challenges arise in mastering cross-modal embeddings and handling user-specific sketch styles. Our proposed framework overcomes these hurdles with a prototypical setup, combined with a grid-based locator and prototypical domain adaptation. We also demonstrate success in few-shot convergence across novel keypoints and classes through extensive experiments.
Sketch Down the FLOPs: Towards Efficient Networks for Human Sketch
May 29, 2025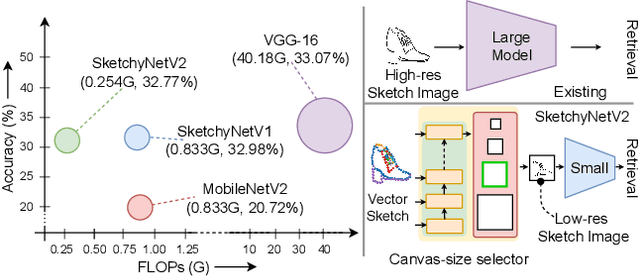
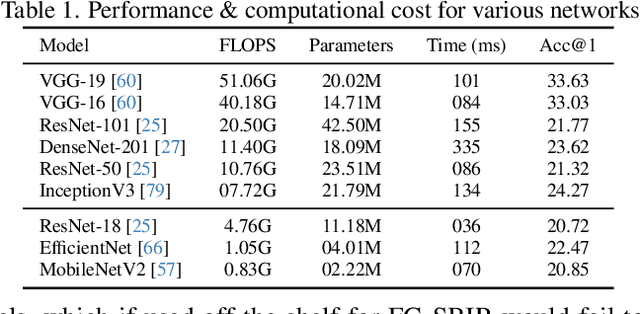
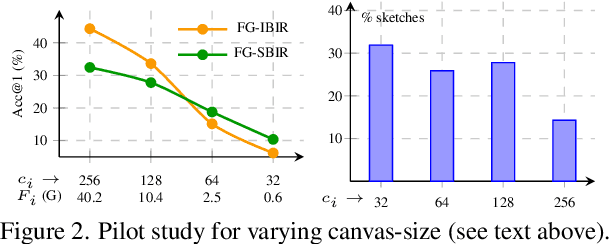
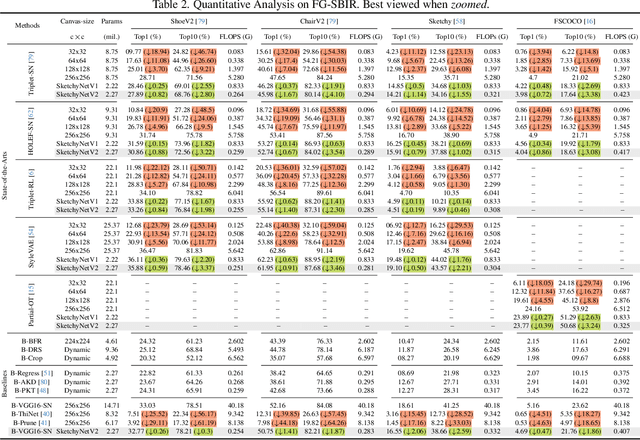
As sketch research has collectively matured over time, its adaptation for at-mass commercialisation emerges on the immediate horizon. Despite an already mature research endeavour for photos, there is no research on the efficient inference specifically designed for sketch data. In this paper, we first demonstrate existing state-of-the-art efficient light-weight models designed for photos do not work on sketches. We then propose two sketch-specific components which work in a plug-n-play manner on any photo efficient network to adapt them to work on sketch data. We specifically chose fine-grained sketch-based image retrieval (FG-SBIR) as a demonstrator as the most recognised sketch problem with immediate commercial value. Technically speaking, we first propose a cross-modal knowledge distillation network to transfer existing photo efficient networks to be compatible with sketch, which brings down number of FLOPs and model parameters by 97.96% percent and 84.89% respectively. We then exploit the abstract trait of sketch to introduce a RL-based canvas selector that dynamically adjusts to the abstraction level which further cuts down number of FLOPs by two thirds. The end result is an overall reduction of 99.37% of FLOPs (from 40.18G to 0.254G) when compared with a full network, while retaining the accuracy (33.03% vs 32.77%) -- finally making an efficient network for the sparse sketch data that exhibit even fewer FLOPs than the best photo counterpart.
Normalized Attention Guidance: Universal Negative Guidance for Diffusion Model
May 27, 2025Negative guidance -- explicitly suppressing unwanted attributes -- remains a fundamental challenge in diffusion models, particularly in few-step sampling regimes. While Classifier-Free Guidance (CFG) works well in standard settings, it fails under aggressive sampling step compression due to divergent predictions between positive and negative branches. We present Normalized Attention Guidance (NAG), an efficient, training-free mechanism that applies extrapolation in attention space with L1-based normalization and refinement. NAG restores effective negative guidance where CFG collapses while maintaining fidelity. Unlike existing approaches, NAG generalizes across architectures (UNet, DiT), sampling regimes (few-step, multi-step), and modalities (image, video), functioning as a \textit{universal} plug-in with minimal computational overhead. Through extensive experimentation, we demonstrate consistent improvements in text alignment (CLIP Score), fidelity (FID, PFID), and human-perceived quality (ImageReward). Our ablation studies validate each design component, while user studies confirm significant preference for NAG-guided outputs. As a model-agnostic inference-time approach requiring no retraining, NAG provides effortless negative guidance for all modern diffusion frameworks -- pseudocode in the Appendix!
SketchFusion: Learning Universal Sketch Features through Fusing Foundation Models
Mar 18, 2025While foundation models have revolutionised computer vision, their effectiveness for sketch understanding remains limited by the unique challenges of abstract, sparse visual inputs. Through systematic analysis, we uncover two fundamental limitations: Stable Diffusion (SD) struggles to extract meaningful features from abstract sketches (unlike its success with photos), and exhibits a pronounced frequency-domain bias that suppresses essential low-frequency components needed for sketch understanding. Rather than costly retraining, we address these limitations by strategically combining SD with CLIP, whose strong semantic understanding naturally compensates for SD's spatial-frequency biases. By dynamically injecting CLIP features into SD's denoising process and adaptively aggregating features across semantic levels, our method achieves state-of-the-art performance in sketch retrieval (+3.35%), recognition (+1.06%), segmentation (+29.42%), and correspondence learning (+21.22%), demonstrating the first truly universal sketch feature representation in the era of foundation models.