 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDoodle Your Keypoints: Sketch-Based Few-Shot Keypoint Detection
Jul 10, 2025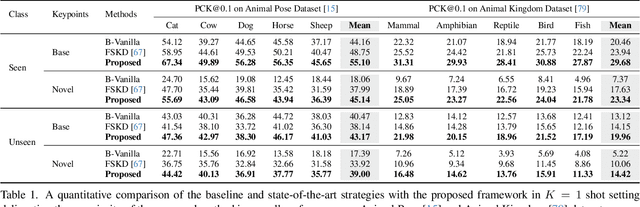
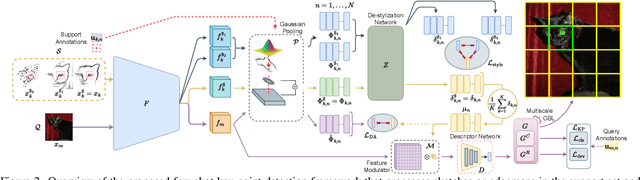
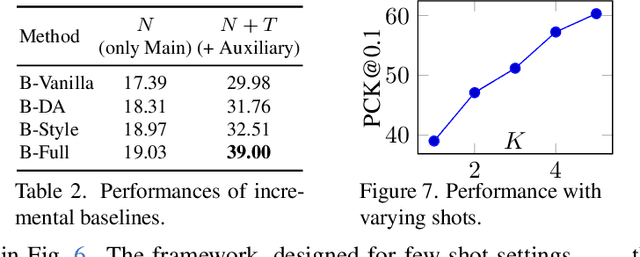
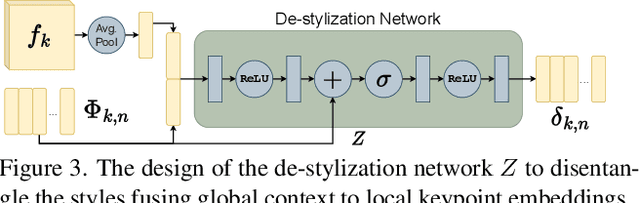
Keypoint detection, integral to modern machine perception, faces challenges in few-shot learning, particularly when source data from the same distribution as the query is unavailable. This gap is addressed by leveraging sketches, a popular form of human expression, providing a source-free alternative. However, challenges arise in mastering cross-modal embeddings and handling user-specific sketch styles. Our proposed framework overcomes these hurdles with a prototypical setup, combined with a grid-based locator and prototypical domain adaptation. We also demonstrate success in few-shot convergence across novel keypoints and classes through extensive experiments.
Sketch Down the FLOPs: Towards Efficient Networks for Human Sketch
May 29, 2025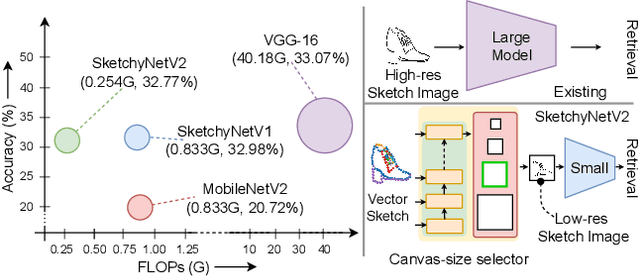
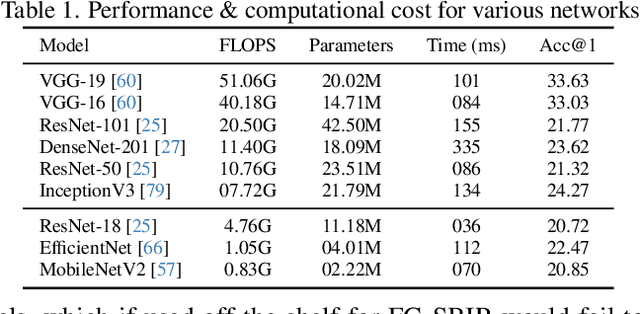
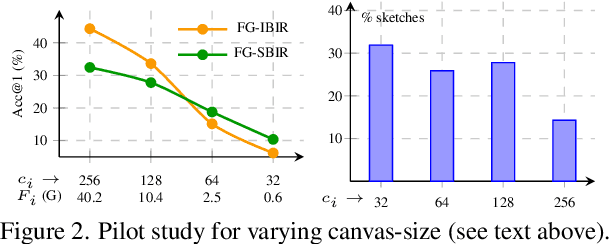
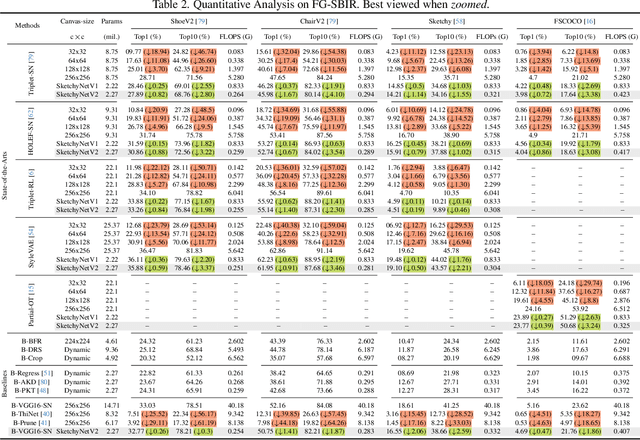
As sketch research has collectively matured over time, its adaptation for at-mass commercialisation emerges on the immediate horizon. Despite an already mature research endeavour for photos, there is no research on the efficient inference specifically designed for sketch data. In this paper, we first demonstrate existing state-of-the-art efficient light-weight models designed for photos do not work on sketches. We then propose two sketch-specific components which work in a plug-n-play manner on any photo efficient network to adapt them to work on sketch data. We specifically chose fine-grained sketch-based image retrieval (FG-SBIR) as a demonstrator as the most recognised sketch problem with immediate commercial value. Technically speaking, we first propose a cross-modal knowledge distillation network to transfer existing photo efficient networks to be compatible with sketch, which brings down number of FLOPs and model parameters by 97.96% percent and 84.89% respectively. We then exploit the abstract trait of sketch to introduce a RL-based canvas selector that dynamically adjusts to the abstraction level which further cuts down number of FLOPs by two thirds. The end result is an overall reduction of 99.37% of FLOPs (from 40.18G to 0.254G) when compared with a full network, while retaining the accuracy (33.03% vs 32.77%) -- finally making an efficient network for the sparse sketch data that exhibit even fewer FLOPs than the best photo counterpart.
Kolmogorov-Arnold Attention: Is Learnable Attention Better For Vision Transformers?
Mar 13, 2025



Kolmogorov-Arnold networks (KANs) are a remarkable innovation consisting of learnable activation functions with the potential to capture more complex relationships from data. Although KANs are useful in finding symbolic representations and continual learning of one-dimensional functions, their effectiveness in diverse machine learning (ML) tasks, such as vision, remains questionable. Presently, KANs are deployed by replacing multilayer perceptrons (MLPs) in deep network architectures, including advanced architectures such as vision Transformers (ViTs). In this paper, we are the first to design a general learnable Kolmogorov-Arnold Attention (KArAt) for vanilla ViTs that can operate on any choice of basis. However, the computing and memory costs of training them motivated us to propose a more modular version, and we designed particular learnable attention, called Fourier-KArAt. Fourier-KArAt and its variants either outperform their ViT counterparts or show comparable performance on CIFAR-10, CIFAR-100, and ImageNet-1K datasets. We dissect these architectures' performance and generalization capacity by analyzing their loss landscapes, weight distributions, optimizer path, attention visualization, and spectral behavior, and contrast them with vanilla ViTs. The goal of this paper is not to produce parameter- and compute-efficient attention, but to encourage the community to explore KANs in conjunction with more advanced architectures that require a careful understanding of learnable activations. Our open-source code and implementation details are available on: https://subhajitmaity.me/KArAt
Fibottention: Inceptive Visual Representation Learning with Diverse Attention Across Heads
Jun 27, 2024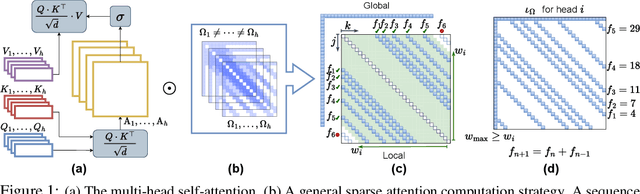


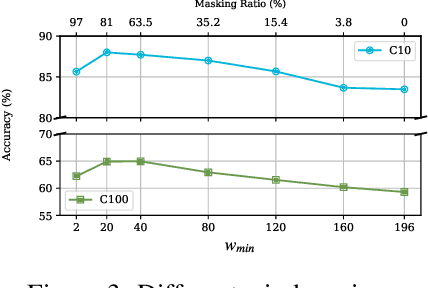
Visual perception tasks are predominantly solved by Vision Transformer (ViT) architectures, which, despite their effectiveness, encounter a computational bottleneck due to the quadratic complexity of computing self-attention. This inefficiency is largely due to the self-attention heads capturing redundant token interactions, reflecting inherent redundancy within visual data. Many works have aimed to reduce the computational complexity of self-attention in ViTs, leading to the development of efficient and sparse transformer architectures. In this paper, viewing through the efficiency lens, we realized that introducing any sparse self-attention strategy in ViTs can keep the computational overhead low. However, these strategies are sub-optimal as they often fail to capture fine-grained visual details. This observation leads us to propose a general, efficient, sparse architecture, named Fibottention, for approximating self-attention with superlinear complexity that is built upon Fibonacci sequences. The key strategies in Fibottention include: it excludes proximate tokens to reduce redundancy, employs structured sparsity by design to decrease computational demands, and incorporates inception-like diversity across attention heads. This diversity ensures the capture of complementary information through non-overlapping token interactions, optimizing both performance and resource utilization in ViTs for visual representation learning. We embed our Fibottention mechanism into multiple state-of-the-art transformer architectures dedicated to visual tasks. Leveraging only 2-6% of the elements in the self-attention heads, Fibottention in conjunction with ViT and its variants, consistently achieves significant performance boosts compared to standard ViTs in nine datasets across three domains $\unicode{x2013}$ image classification, video understanding, and robot learning tasks.
DistilDoc: Knowledge Distillation for Visually-Rich Document Applications
Jun 12, 2024
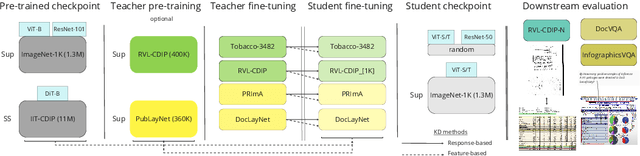
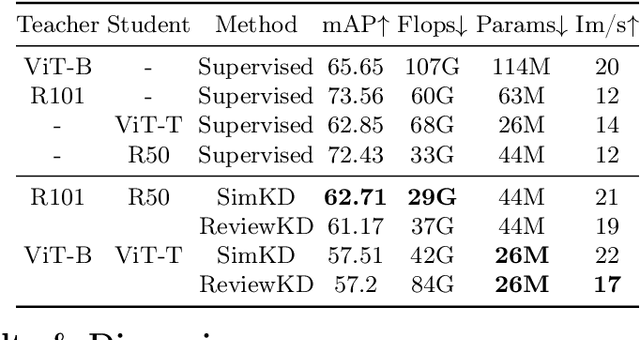
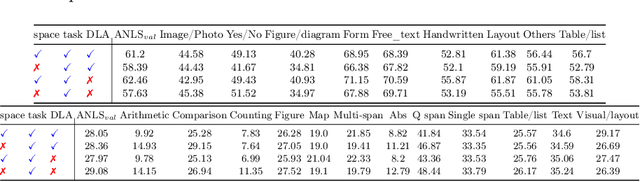
This work explores knowledge distillation (KD) for visually-rich document (VRD) applications such as document layout analysis (DLA) and document image classification (DIC). While VRD research is dependent on increasingly sophisticated and cumbersome models, the field has neglected to study efficiency via model compression. Here, we design a KD experimentation methodology for more lean, performant models on document understanding (DU) tasks that are integral within larger task pipelines. We carefully selected KD strategies (response-based, feature-based) for distilling knowledge to and from backbones with different architectures (ResNet, ViT, DiT) and capacities (base, small, tiny). We study what affects the teacher-student knowledge gap and find that some methods (tuned vanilla KD, MSE, SimKD with an apt projector) can consistently outperform supervised student training. Furthermore, we design downstream task setups to evaluate covariate shift and the robustness of distilled DLA models on zero-shot layout-aware document visual question answering (DocVQA). DLA-KD experiments result in a large mAP knowledge gap, which unpredictably translates to downstream robustness, accentuating the need to further explore how to efficiently obtain more semantic document layout awareness.
Image Hash Minimization for Tamper Detection
May 28, 2023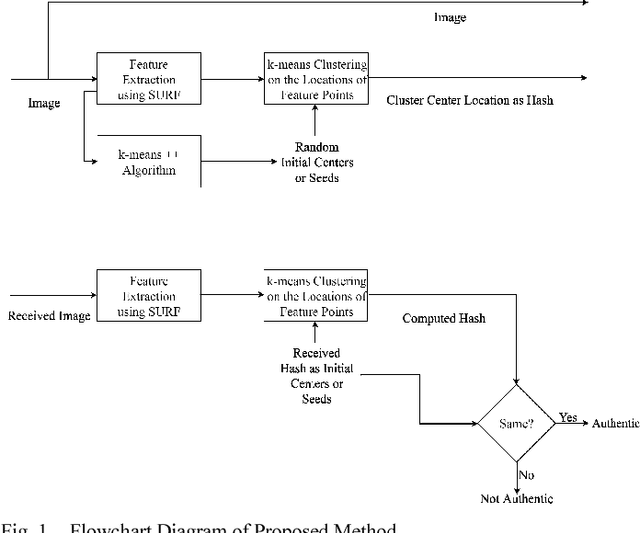

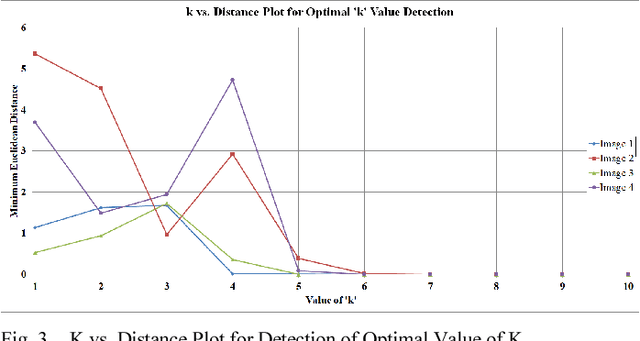
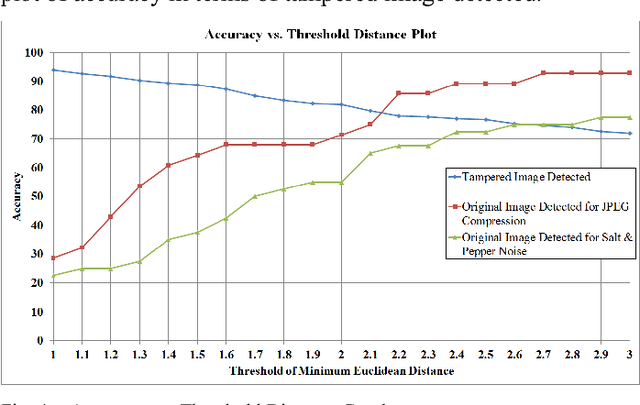
Tamper detection using image hash is a very common problem of modern days. Several research and advancements have already been done to address this problem. However, most of the existing methods lack the accuracy of tamper detection when the tampered area is low, as well as requiring long image hashes. In this paper, we propose a novel method objectively to minimize the hash length while enhancing the performance at low tampered area.
* Published at the 9th International Conference on Advances in Pattern Recognition, 2017
SelfDocSeg: A Self-Supervised vision-based Approach towards Document Segmentation
May 02, 2023Document layout analysis is a known problem to the documents research community and has been vastly explored yielding a multitude of solutions ranging from text mining, and recognition to graph-based representation, visual feature extraction, etc. However, most of the existing works have ignored the crucial fact regarding the scarcity of labeled data. With growing internet connectivity to personal life, an enormous amount of documents had been available in the public domain and thus making data annotation a tedious task. We address this challenge using self-supervision and unlike, the few existing self-supervised document segmentation approaches which use text mining and textual labels, we use a complete vision-based approach in pre-training without any ground-truth label or its derivative. Instead, we generate pseudo-layouts from the document images to pre-train an image encoder to learn the document object representation and localization in a self-supervised framework before fine-tuning it with an object detection model. We show that our pipeline sets a new benchmark in this context and performs at par with the existing methods and the supervised counterparts, if not outperforms. The code is made publicly available at: https://github.com/MaitySubhajit/SelfDocSeg
Fault Area Detection in Leaf Diseases using k-means Clustering
Oct 24, 2018



With increasing population the crisis of food is getting bigger day by day.In this time of crisis,the leaf disease of crops is the biggest problem in the food industry.In this paper, we have addressed that problem and proposed an efficient method to detect leaf disease.Leaf diseases can be detected from sample images of the leaf with the help of image processing and segmentation.Using k-means clustering and Otsu's method the faulty region in a leaf is detected which helps to determine proper course of action to be taken.Further the ratio of normal and faulty region if calculated would be able to predict if the leaf can be cured at all.