 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUniLACT: Depth-Aware RGB Latent Action Learning for Vision-Language-Action Models
Feb 23, 2026Latent action representations learned from unlabeled videos have recently emerged as a promising paradigm for pretraining vision-language-action (VLA) models without explicit robot action supervision. However, latent actions derived solely from RGB observations primarily encode appearance-driven dynamics and lack explicit 3D geometric structure, which is essential for precise and contact-rich manipulation. To address this limitation, we introduce UniLACT, a transformer-based VLA model that incorporates geometric structure through depth-aware latent pretraining, enabling downstream policies to inherit stronger spatial priors. To facilitate this process, we propose UniLARN, a unified latent action learning framework based on inverse and forward dynamics objectives that learns a shared embedding space for RGB and depth while explicitly modeling their cross-modal interactions. This formulation produces modality-specific and unified latent action representations that serve as pseudo-labels for the depth-aware pretraining of UniLACT. Extensive experiments in both simulation and real-world settings demonstrate the effectiveness of depth-aware unified latent action representations. UniLACT consistently outperforms RGB-based latent action baselines under in-domain and out-of-domain pretraining regimes, as well as on both seen and unseen manipulation tasks.
SKI Models: Skeleton Induced Vision-Language Embeddings for Understanding Activities of Daily Living
Feb 05, 2025



The introduction of vision-language models like CLIP has enabled the development of foundational video models capable of generalizing to unseen videos and human actions. However, these models are typically trained on web videos, which often fail to capture the challenges present in Activities of Daily Living (ADL) videos. Existing works address ADL-specific challenges, such as similar appearances, subtle motion patterns, and multiple viewpoints, by combining 3D skeletons and RGB videos. However, these approaches are not integrated with language, limiting their ability to generalize to unseen action classes. In this paper, we introduce SKI models, which integrate 3D skeletons into the vision-language embedding space. SKI models leverage a skeleton-language model, SkeletonCLIP, to infuse skeleton information into Vision Language Models (VLMs) and Large Vision Language Models (LVLMs) through collaborative training. Notably, SKI models do not require skeleton data during inference, enhancing their robustness for real-world applications. The effectiveness of SKI models is validated on three popular ADL datasets for zero-shot action recognition and video caption generation tasks.
From My View to Yours: Ego-Augmented Learning in Large Vision Language Models for Understanding Exocentric Daily Living Activities
Jan 10, 2025



Large Vision Language Models (LVLMs) have demonstrated impressive capabilities in video understanding, yet their adoption for Activities of Daily Living (ADL) remains limited by their inability to capture fine-grained interactions and spatial relationships. This limitation is particularly evident in ADL tasks, where understanding detailed human-object interaction and human-centric motion is crucial for applications such as elderly monitoring and cognitive assessment. To address this, we aim to leverage the complementary nature of egocentric views to enhance LVLM's understanding of exocentric ADL videos. Consequently, we propose an online ego2exo distillation approach to learn ego-augmented exo representations in LVLMs. While effective, this approach requires paired ego-exo training data, which is impractical to collect for real-world ADL scenarios. Consequently, we develop EgoMimic, a skeleton-guided method that can generate mimicked ego views from exocentric videos. We find that the exo representations of our ego-augmented LVLMs successfully learn to extract ego-perspective cues, demonstrated through comprehensive evaluation on six ADL benchmarks and our proposed EgoPerceptionMCQ benchmark designed specifically to assess egocentric understanding from exocentric videos. Code, models, and data will be open-sourced at https://github.com/dominickrei/EgoExo4ADL.
Introducing Gating and Context into Temporal Action Detection
Sep 06, 2024Temporal Action Detection (TAD), the task of localizing and classifying actions in untrimmed video, remains challenging due to action overlaps and variable action durations. Recent findings suggest that TAD performance is dependent on the structural design of transformers rather than on the self-attention mechanism. Building on this insight, we propose a refined feature extraction process through lightweight, yet effective operations. First, we employ a local branch that employs parallel convolutions with varying window sizes to capture both fine-grained and coarse-grained temporal features. This branch incorporates a gating mechanism to select the most relevant features. Second, we introduce a context branch that uses boundary frames as key-value pairs to analyze their relationship with the central frame through cross-attention. The proposed method captures temporal dependencies and improves contextual understanding. Evaluations of the gating mechanism and context branch on challenging datasets (THUMOS14 and EPIC-KITCHEN 100) show a consistent improvement over the baseline and existing methods.
Fibottention: Inceptive Visual Representation Learning with Diverse Attention Across Heads
Jun 27, 2024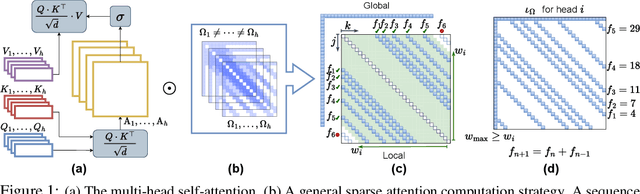


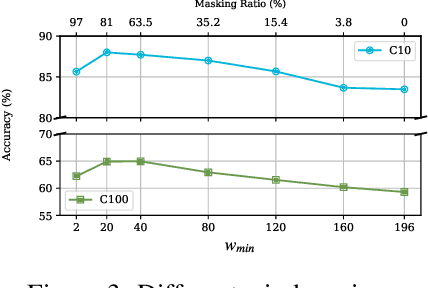
Visual perception tasks are predominantly solved by Vision Transformer (ViT) architectures, which, despite their effectiveness, encounter a computational bottleneck due to the quadratic complexity of computing self-attention. This inefficiency is largely due to the self-attention heads capturing redundant token interactions, reflecting inherent redundancy within visual data. Many works have aimed to reduce the computational complexity of self-attention in ViTs, leading to the development of efficient and sparse transformer architectures. In this paper, viewing through the efficiency lens, we realized that introducing any sparse self-attention strategy in ViTs can keep the computational overhead low. However, these strategies are sub-optimal as they often fail to capture fine-grained visual details. This observation leads us to propose a general, efficient, sparse architecture, named Fibottention, for approximating self-attention with superlinear complexity that is built upon Fibonacci sequences. The key strategies in Fibottention include: it excludes proximate tokens to reduce redundancy, employs structured sparsity by design to decrease computational demands, and incorporates inception-like diversity across attention heads. This diversity ensures the capture of complementary information through non-overlapping token interactions, optimizing both performance and resource utilization in ViTs for visual representation learning. We embed our Fibottention mechanism into multiple state-of-the-art transformer architectures dedicated to visual tasks. Leveraging only 2-6% of the elements in the self-attention heads, Fibottention in conjunction with ViT and its variants, consistently achieves significant performance boosts compared to standard ViTs in nine datasets across three domains $\unicode{x2013}$ image classification, video understanding, and robot learning tasks.
LLAVIDAL: Benchmarking Large Language Vision Models for Daily Activities of Living
Jun 13, 2024Large Language Vision Models (LLVMs) have demonstrated effectiveness in processing internet videos, yet they struggle with the visually perplexing dynamics present in Activities of Daily Living (ADL) due to limited pertinent datasets and models tailored to relevant cues. To this end, we propose a framework for curating ADL multiview datasets to fine-tune LLVMs, resulting in the creation of ADL-X, comprising 100K RGB video-instruction pairs, language descriptions, 3D skeletons, and action-conditioned object trajectories. We introduce LLAVIDAL, an LLVM capable of incorporating 3D poses and relevant object trajectories to understand the intricate spatiotemporal relationships within ADLs. Furthermore, we present a novel benchmark, ADLMCQ, for quantifying LLVM effectiveness in ADL scenarios. When trained on ADL-X, LLAVIDAL consistently achieves state-of-the-art performance across all ADL evaluation metrics. Qualitative analysis reveals LLAVIDAL's temporal reasoning capabilities in understanding ADL. The link to the dataset is provided at: https://adl-x.github.io/
Just Add $π$! Pose Induced Video Transformers for Understanding Activities of Daily Living
Nov 30, 2023Video transformers have become the de facto standard for human action recognition, yet their exclusive reliance on the RGB modality still limits their adoption in certain domains. One such domain is Activities of Daily Living (ADL), where RGB alone is not sufficient to distinguish between visually similar actions, or actions observed from multiple viewpoints. To facilitate the adoption of video transformers for ADL, we hypothesize that the augmentation of RGB with human pose information, known for its sensitivity to fine-grained motion and multiple viewpoints, is essential. Consequently, we introduce the first Pose Induced Video Transformer: PI-ViT (or $\pi$-ViT), a novel approach that augments the RGB representations learned by video transformers with 2D and 3D pose information. The key elements of $\pi$-ViT are two plug-in modules, 2D Skeleton Induction Module and 3D Skeleton Induction Module, that are responsible for inducing 2D and 3D pose information into the RGB representations. These modules operate by performing pose-aware auxiliary tasks, a design choice that allows $\pi$-ViT to discard the modules during inference. Notably, $\pi$-ViT achieves the state-of-the-art performance on three prominent ADL datasets, encompassing both real-world and large-scale RGB-D datasets, without requiring poses or additional computational overhead at inference.
Limited Data, Unlimited Potential: A Study on ViTs Augmented by Masked Autoencoders
Oct 31, 2023



Vision Transformers (ViTs) have become ubiquitous in computer vision. Despite their success, ViTs lack inductive biases, which can make it difficult to train them with limited data. To address this challenge, prior studies suggest training ViTs with self-supervised learning (SSL) and fine-tuning sequentially. However, we observe that jointly optimizing ViTs for the primary task and a Self-Supervised Auxiliary Task (SSAT) is surprisingly beneficial when the amount of training data is limited. We explore the appropriate SSL tasks that can be optimized alongside the primary task, the training schemes for these tasks, and the data scale at which they can be most effective. Our findings reveal that SSAT is a powerful technique that enables ViTs to leverage the unique characteristics of both the self-supervised and primary tasks, achieving better performance than typical ViTs pre-training with SSL and fine-tuning sequentially. Our experiments, conducted on 10 datasets, demonstrate that SSAT significantly improves ViT performance while reducing carbon footprint. We also confirm the effectiveness of SSAT in the video domain for deepfake detection, showcasing its generalizability. Our code is available at https://github.com/dominickrei/Limited-data-vits.
Seeing the Pose in the Pixels: Learning Pose-Aware Representations in Vision Transformers
Jun 15, 2023



Human perception of surroundings is often guided by the various poses present within the environment. Many computer vision tasks, such as human action recognition and robot imitation learning, rely on pose-based entities like human skeletons or robotic arms. However, conventional Vision Transformer (ViT) models uniformly process all patches, neglecting valuable pose priors in input videos. We argue that incorporating poses into RGB data is advantageous for learning fine-grained and viewpoint-agnostic representations. Consequently, we introduce two strategies for learning pose-aware representations in ViTs. The first method, called Pose-aware Attention Block (PAAB), is a plug-and-play ViT block that performs localized attention on pose regions within videos. The second method, dubbed Pose-Aware Auxiliary Task (PAAT), presents an auxiliary pose prediction task optimized jointly with the primary ViT task. Although their functionalities differ, both methods succeed in learning pose-aware representations, enhancing performance in multiple diverse downstream tasks. Our experiments, conducted across seven datasets, reveal the efficacy of both pose-aware methods on three video analysis tasks, with PAAT holding a slight edge over PAAB. Both PAAT and PAAB surpass their respective backbone Transformers by up to 9.8% in real-world action recognition and 21.8% in multi-view robotic video alignment. Code is available at https://github.com/dominickrei/PoseAwareVT.