 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTruthLens:A Training-Free Paradigm for DeepFake Detection
Mar 19, 2025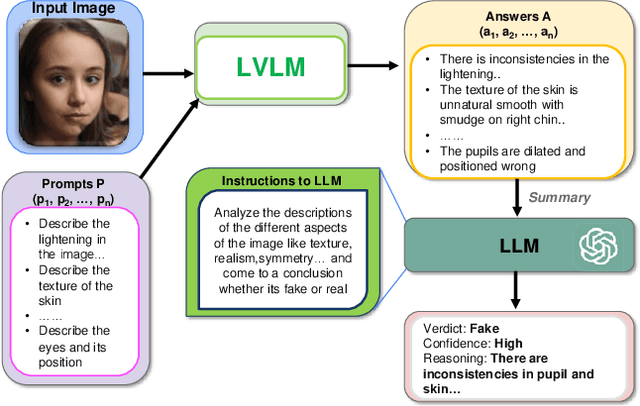
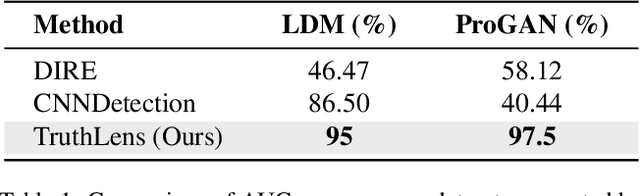

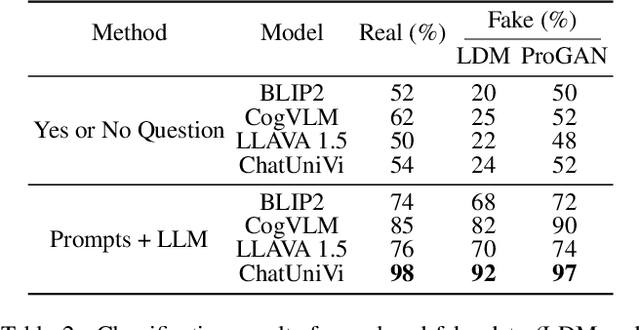
The proliferation of synthetic images generated by advanced AI models poses significant challenges in identifying and understanding manipulated visual content. Current fake image detection methods predominantly rely on binary classification models that focus on accuracy while often neglecting interpretability, leaving users without clear insights into why an image is deemed real or fake. To bridge this gap, we introduce TruthLens, a novel training-free framework that reimagines deepfake detection as a visual question-answering (VQA) task. TruthLens utilizes state-of-the-art large vision-language models (LVLMs) to observe and describe visual artifacts and combines this with the reasoning capabilities of large language models (LLMs) like GPT-4 to analyze and aggregate evidence into informed decisions. By adopting a multimodal approach, TruthLens seamlessly integrates visual and semantic reasoning to not only classify images as real or fake but also provide interpretable explanations for its decisions. This transparency enhances trust and provides valuable insights into the artifacts that signal synthetic content. Extensive evaluations demonstrate that TruthLens outperforms conventional methods, achieving high accuracy on challenging datasets while maintaining a strong emphasis on explainability. By reframing deepfake detection as a reasoning-driven process, TruthLens establishes a new paradigm in combating synthetic media, combining cutting-edge performance with interpretability to address the growing threats of visual disinformation.
LLAVIDAL: Benchmarking Large Language Vision Models for Daily Activities of Living
Jun 13, 2024Large Language Vision Models (LLVMs) have demonstrated effectiveness in processing internet videos, yet they struggle with the visually perplexing dynamics present in Activities of Daily Living (ADL) due to limited pertinent datasets and models tailored to relevant cues. To this end, we propose a framework for curating ADL multiview datasets to fine-tune LLVMs, resulting in the creation of ADL-X, comprising 100K RGB video-instruction pairs, language descriptions, 3D skeletons, and action-conditioned object trajectories. We introduce LLAVIDAL, an LLVM capable of incorporating 3D poses and relevant object trajectories to understand the intricate spatiotemporal relationships within ADLs. Furthermore, we present a novel benchmark, ADLMCQ, for quantifying LLVM effectiveness in ADL scenarios. When trained on ADL-X, LLAVIDAL consistently achieves state-of-the-art performance across all ADL evaluation metrics. Qualitative analysis reveals LLAVIDAL's temporal reasoning capabilities in understanding ADL. The link to the dataset is provided at: https://adl-x.github.io/
Multiview Aerial Visual Recognition (MAVREC): Can Multi-view Improve Aerial Visual Perception?
Dec 07, 2023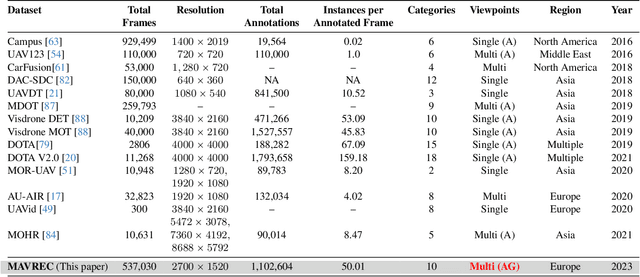
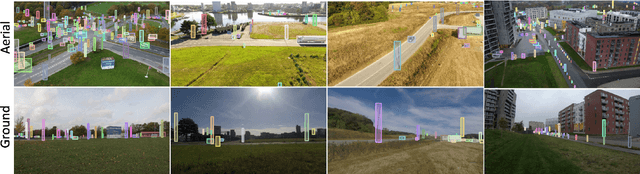
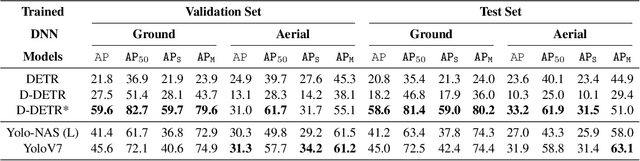
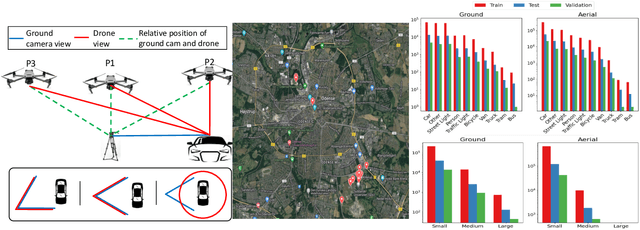
Despite the commercial abundance of UAVs, aerial data acquisition remains challenging, and the existing Asia and North America-centric open-source UAV datasets are small-scale or low-resolution and lack diversity in scene contextuality. Additionally, the color content of the scenes, solar-zenith angle, and population density of different geographies influence the data diversity. These two factors conjointly render suboptimal aerial-visual perception of the deep neural network (DNN) models trained primarily on the ground-view data, including the open-world foundational models. To pave the way for a transformative era of aerial detection, we present Multiview Aerial Visual RECognition or MAVREC, a video dataset where we record synchronized scenes from different perspectives -- ground camera and drone-mounted camera. MAVREC consists of around 2.5 hours of industry-standard 2.7K resolution video sequences, more than 0.5 million frames, and 1.1 million annotated bounding boxes. This makes MAVREC the largest ground and aerial-view dataset, and the fourth largest among all drone-based datasets across all modalities and tasks. Through our extensive benchmarking on MAVREC, we recognize that augmenting object detectors with ground-view images from the corresponding geographical location is a superior pre-training strategy for aerial detection. Building on this strategy, we benchmark MAVREC with a curriculum-based semi-supervised object detection approach that leverages labeled (ground and aerial) and unlabeled (only aerial) images to enhance the aerial detection. We publicly release the MAVREC dataset: https://mavrec.github.io.