 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContinual Quantization-Aware Pre-Training: When to transition from 16-bit to 1.58-bit pre-training for BitNet language models?
Feb 17, 2025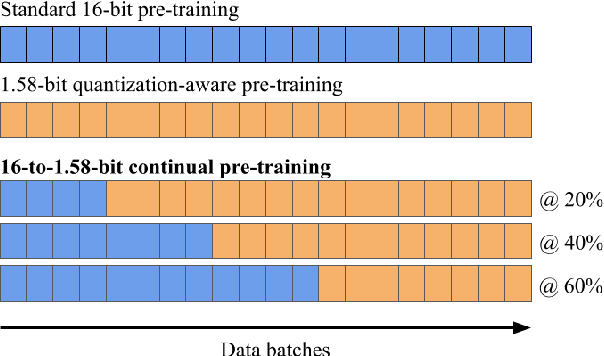
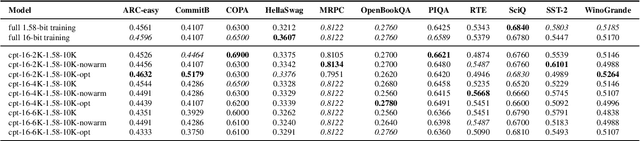
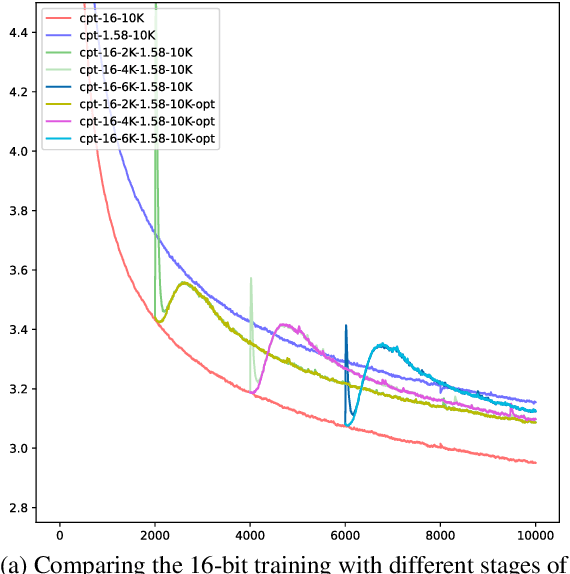
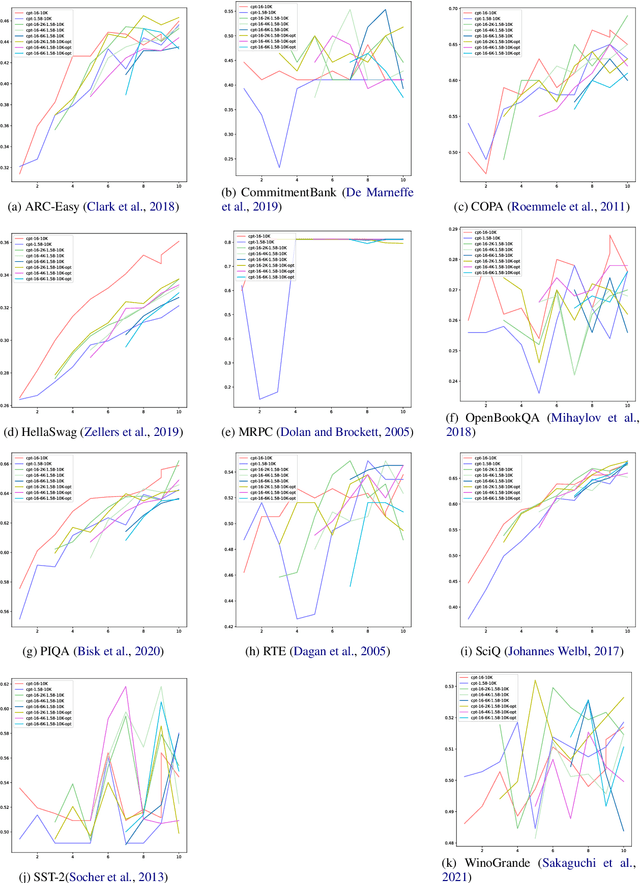
Large language models (LLMs) require immense resources for training and inference. Quantization, a technique that reduces the precision of model parameters, offers a promising solution for improving LLM efficiency and sustainability. While post-training quantization methods typically achieve 4-8 bits per parameter, recent research suggests that training LLMs with 1.58 bits per weight parameter from scratch can maintain model accuracy while greatly reducing memory requirements and energy consumption at inference time. Here, we investigate a training strategy for quantization-aware pre-training, where the models are first trained with 16-bit precision and then transition into 1.58-bit quantization-aware training. Our results on 11 downstream tasks show that this 16-to-1.58-bit training strategy is preferable over full 1.58-bit training and leaves models closer to those which have undergone 16-bit training. We further investigate the effects of retaining the optimizer state at the transition point and gradually phasing in quantization strength -- finding that both techniques alleviate the magnitude of loss spikes, but also that these effects can be compensated through further training.
FlexDeMo: Decoupled Momentum Optimization for Fully and Hybrid Sharded Training
Feb 10, 2025Training large neural network models requires extensive computational resources, often distributed across several nodes and accelerators. Recent findings suggest that it may be sufficient to only exchange the fast moving components of the gradients, while accumulating momentum locally (Decoupled Momentum, or DeMo). However, when considering larger models that do not fit on a single accelerate, the exchange of gradient information and the integration of DeMo needs to be reconsidered. Here, we propose employing a hybrid strategy, FlexDeMo, whereby nodes fully synchronize locally between different GPUs and inter-node communication is improved through only using the fast-moving components. This effectively combines previous hybrid sharding strategies with the advantages of decoupled momentum. Our experimental results show that FlexDeMo is on par with AdamW in terms of validation loss, demonstrating its viability.
When are 1.58 bits enough? A Bottom-up Exploration of BitNet Quantization
Nov 08, 2024
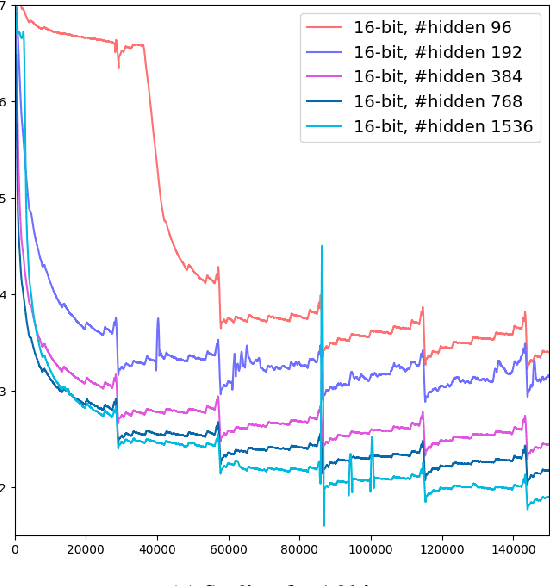
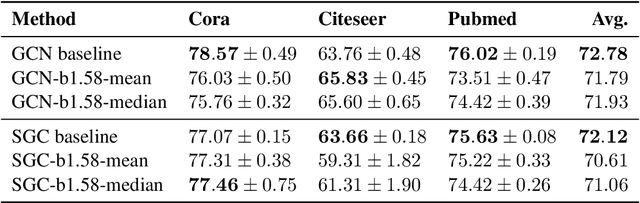
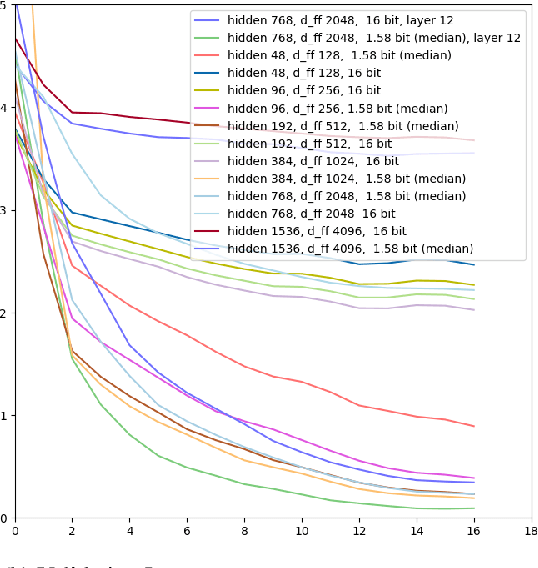
Contemporary machine learning models, such as language models, are powerful, but come with immense resource requirements both at training and inference time. It has been shown that decoder-only language models can be trained to a competitive state with ternary weights (1.58 bits per weight), facilitating efficient inference. Here, we start our exploration with non-transformer model architectures, investigating 1.58-bit training for multi-layer perceptrons and graph neural networks. Then, we explore 1.58-bit training in other transformer-based language models, namely encoder-only and encoder-decoder models. Our results show that in all of these settings, 1.58-bit training is on par with or sometimes even better than the standard 32/16-bit models.
Multiview Aerial Visual Recognition (MAVREC): Can Multi-view Improve Aerial Visual Perception?
Dec 07, 2023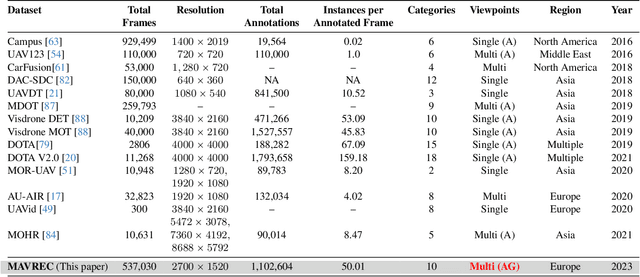
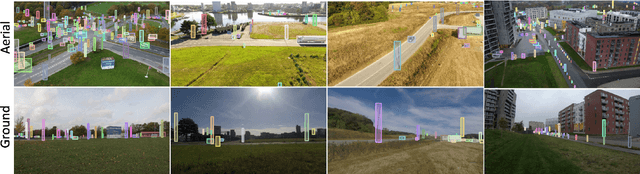
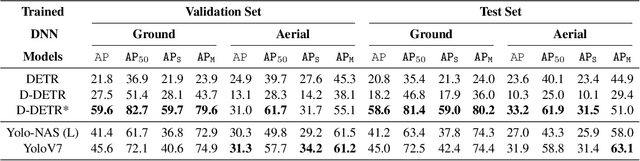
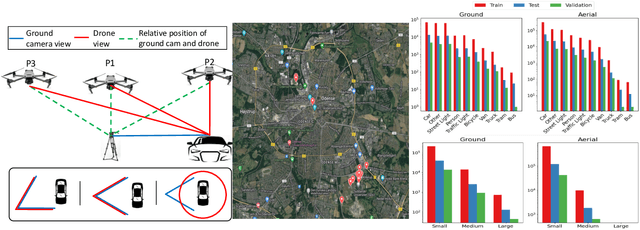
Despite the commercial abundance of UAVs, aerial data acquisition remains challenging, and the existing Asia and North America-centric open-source UAV datasets are small-scale or low-resolution and lack diversity in scene contextuality. Additionally, the color content of the scenes, solar-zenith angle, and population density of different geographies influence the data diversity. These two factors conjointly render suboptimal aerial-visual perception of the deep neural network (DNN) models trained primarily on the ground-view data, including the open-world foundational models. To pave the way for a transformative era of aerial detection, we present Multiview Aerial Visual RECognition or MAVREC, a video dataset where we record synchronized scenes from different perspectives -- ground camera and drone-mounted camera. MAVREC consists of around 2.5 hours of industry-standard 2.7K resolution video sequences, more than 0.5 million frames, and 1.1 million annotated bounding boxes. This makes MAVREC the largest ground and aerial-view dataset, and the fourth largest among all drone-based datasets across all modalities and tasks. Through our extensive benchmarking on MAVREC, we recognize that augmenting object detectors with ground-view images from the corresponding geographical location is a superior pre-training strategy for aerial detection. Building on this strategy, we benchmark MAVREC with a curriculum-based semi-supervised object detection approach that leverages labeled (ground and aerial) and unlabeled (only aerial) images to enhance the aerial detection. We publicly release the MAVREC dataset: https://mavrec.github.io.