 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhen are 1.58 bits enough? A Bottom-up Exploration of BitNet Quantization
Paper and Code

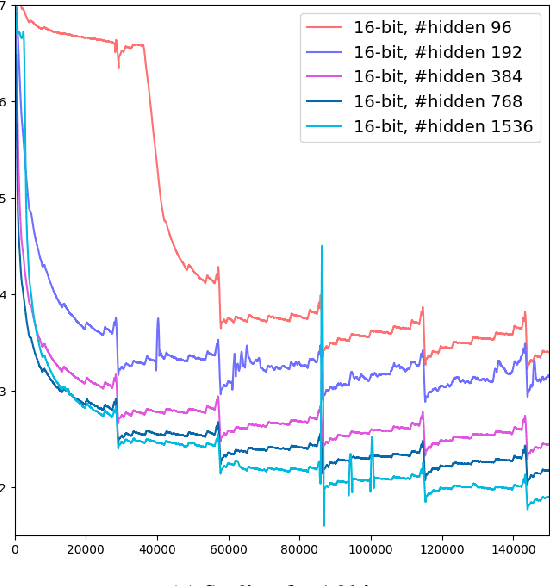
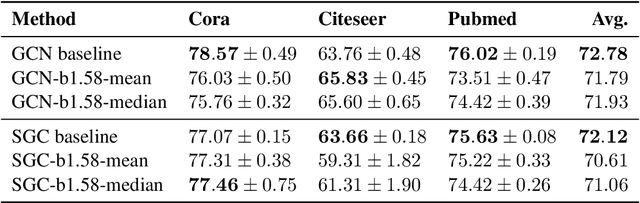
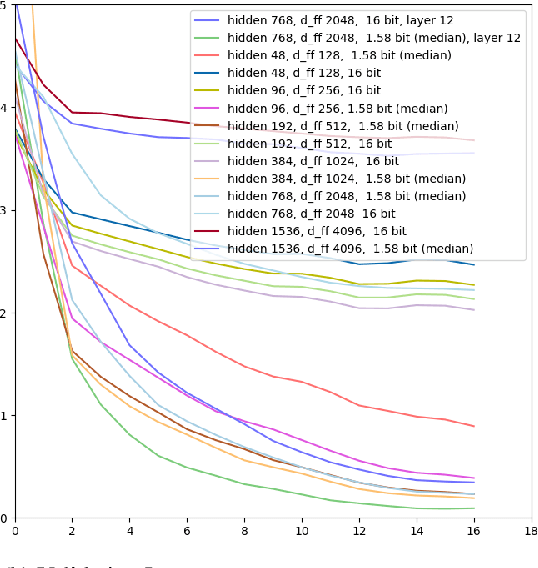
Contemporary machine learning models, such as language models, are powerful, but come with immense resource requirements both at training and inference time. It has been shown that decoder-only language models can be trained to a competitive state with ternary weights (1.58 bits per weight), facilitating efficient inference. Here, we start our exploration with non-transformer model architectures, investigating 1.58-bit training for multi-layer perceptrons and graph neural networks. Then, we explore 1.58-bit training in other transformer-based language models, namely encoder-only and encoder-decoder models. Our results show that in all of these settings, 1.58-bit training is on par with or sometimes even better than the standard 32/16-bit models.