 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Arbiter Agent: Continually Monitoring Multi-Agent Conversations to Detect Emergent Misalignment
Jun 09, 2026As AI systems built from multiple language-model agents become more common, they are increasingly used to make decisions together: discussing, negotiating, and acting on shared tasks. While individual agents may appear well-aligned when tested on their own, problems can arise from how they interact with one another. We introduce the Arbiter, an agent designed to monitor multi-agent conversations in real time and identify which participants may be behaving in misaligned ways. The Arbiter operates under a limited "inspection budget", meaning it must decide carefully how to use its resources. As it observes a conversation step by step, it can choose to wait, question a participant, examine internal information such as system prompts or reasoning traces, or log concerning behavior. At the end, it produces a report identifying the likely source of misalignment. We evaluate the Arbiter across five conversation conditions, ranging from risky financial advice model organisms to evaluation-aware and colluding agents, we test five tool configurations of increasing capability and two backbone models. We find that the Arbiter reliably detects misaligned agents well before the end of the conversation, with active inspection tools improving both detection accuracy and speed. Weight-induced misalignment proves hardest to detect, while instruction-induced misalignment is identified reliably even under passive observation. The logging tool exhibits a dual effect, improving recall at the cost of precision. These results suggest that continual, budget-aware monitoring can effectively catch misalignment, and that overseeing multi-agent systems may require treating the auditor as an active participant in the process. The code is available at https://github.com/aisilab/arbiter.
BrainSurgery: Reproducible and Reliable Declarative Weight Manipulations for Model Editing and Upcycling
Jun 08, 2026As deep learning models scale, managing, inspecting, and modifying large checkpoints has become increasingly challenging. Researchers often need to alter model weights for layer restructuring, precision casting, low-rank factorization, and architectural debugging, yet these workflows often rely on fragile ad-hoc Python scripts. Here, we introduce BrainSurgery, a tool for robust and reproducible "tensor surgery" on neural network checkpoints, and provide a system demonstration covering four examples and three case studies from model upcycling to LoRA extraction. By abstracting storage formats and memory management, BrainSurgery executes complex transformations through declarative YAML plans. It supports structural modifications, mathematical transformations, and tensor reshaping through expressive regex and structural targeting, while built-in assertions validate tensor shapes, data types, and values to prevent silent errors. We envision that BrainSurgery will provide a strong foundation for future research through its reproducible and validated operations.
PsychoSafe: Eliciting Psychologically-Informed Refusals in Large Language Models
Jun 08, 2026Large language models (LLMs) routinely face requests that should be refused, creating a trade-off between helpfulness and harm prevention. However, refusals themselves can be helpful. In high-risk interactions involving crisis, coercion, or escalating intent, blunt non-compliance may prevent direct harm while still failing to support the needs of the person behind the request. We present PsychoSafe, a psychologically-informed refusal framework that reframes refusal as structured supportive communication grounded in evidence-based intervention strategies. To develop PsychoSafe, we construct a corpus of 8019 prompt-response pairs spanning five psychologically salient risk domains and apply prompting and parameter-efficient fine-tuning to Qwen 3.5 27B. On a balanced validation set of 500 prompts, evaluated with an LLM judge and validated through human ratings, PsychoSafe prompting improves overall refusal quality by 28.1% over a generic baseline, with particularly strong gains in external resource referral (+46.8%) and psychological grounding (+34.8%), while preserving downstream performance on non-refusal tasks. Fine-tuning achieves near-perfect refusal and resource-referral rates but reduces response relevance. Additional evaluations on SORRY-Bench and XSTest show strong in-domain robustness but limited out-of-domain generalization, suggesting that future work should diversify fine-tuning data to help models apply interventions selectively rather than schematically.
LLMs Can Leak Training Data But Do They Want To? A Propensity-Aware Evaluation of Memorization in LLMs
Jun 04, 2026Large language models can reproduce training data, but existing memorization evaluations mostly measure whether models can be forced to do so, rather than whether they do so under ordinary use. We introduce PropMe, a propensity-aware framework for memorization evaluation that contrasts prefix-based capability attacks with non-adversarial evaluations. We propose a metric transformation that, applied to existing functions, allows to create propensity metrics. We further introduce SimpleTrace, a lightweight tracing pipeline built on infini-gram that deterministically attributes model generations to large-scale training corpora and computes verbatim, near-verbatim, and propensity-transformed memorization metrics. Evaluating two fully-open models: Comma and DFM Decoder on two datasets: Common Pile and Dynaword in two languages, we find a consistent gap between capability and propensity: prefix attacks elicit substantially stronger memorization signals than generic or dataset-specific prompts, while propensity scores remain low overall. Thus, the models can reveal training data when directly elicited, but rarely do so in more common non-adversarial settings. We also find that DFM Decoder, which is continually pre-trained from Comma, exhibits reduced memorization and memorization propensity for Common Pile, confirming that memorization capability can decrease when later training emphasizes partially different data. Our results suggest, and we encourage, that memorization audits should report both worst-case extractability and ordinary leakage propensity in order to have a more comprehensive view of this phenomenon.
Emergent Languages in Populations of Language Model Agents: From Token Efficiency to Oversight Evasion
May 29, 2026Monitoring autonomous language model agents currently relies mostly on surface behavior. But what happens when agent populations invent new languages with the goal of avoiding human oversight. Here, we study the emergent languages on Moltbook. For this, we build upon the Moltbook Files dataset and apply a two-stage approach consisting of a rule-based heuristic (about 6000 matches) followed by zero-shot classification (518 kept). The resulting categories include token efficiency (166), new natural languages (106), and oversight evasion (59). We conduct both quantitative and qualitative analyses. Our results show that posts proposing new languages for avoiding oversight are judged by DeepSeek-3.2 as being less aligned than the other categories and that all languages can be learned by other language models in-context merely from a description of the language. Moreover, manually studying exemplary cases reveals surprisingly sophisticated steganographic protocols like embedding hidden messages in natural language. Although we cannot be certain about the extent of autonomy in ideation of these languages, our results add up to the evidence that monitoring surface behavior may soon be insufficient for retaining control over agent populations.
Confidence and Calibration of Activation Oracles for Reliable Interpretation of Language Model Internals
May 25, 2026Activation oracles aim to make the activations of other models legible to humans and yield promising results compared to white-box interpretability techniques. However, uncertainty quantification (UQ) for the natural-language outputs of such activation oracles is so far understudied. Here, we investigate 6 different methods for estimating the confidence of activation oracles and evaluate how well-calibrated their confidence scores are. Our experiments on 6,000 samples per oracle (varying verbalizer and context prompts) reveal that bootstrap mode frequency is the best-calibrated method among those tested (ECE 5.7% vs. 25.5% for the answer-word log-probability on Qwen3-8B; 10.3% vs. 13.1% on Qwen3.6-27B), and that the log-prob baseline can serve as a fast triage signal at a fraction of the cost. Code and the patched trainer are available at https://github.com/federicotorrielli/probabilistic_activation_oracles.
SommBench: Assessing Sommelier Expertise of Language Models
Mar 12, 2026With the rapid advances of large language models, it becomes increasingly important to systematically evaluate their multilingual and multicultural capabilities. Previous cultural evaluation benchmarks focus mainly on basic cultural knowledge that can be encoded in linguistic form. Here, we propose SommBench, a multilingual benchmark to assess sommelier expertise, a domain deeply grounded in the senses of smell and taste. While language models learn about sensory properties exclusively through textual descriptions, SommBench tests whether this textual grounding is sufficient to emulate expert-level sensory judgment. SommBench comprises three main tasks: Wine Theory Question Answering (WTQA), Wine Feature Completion (WFC), and Food-Wine Pairing (FWP). SommBench is available in multiple languages: English, Slovak, Swedish, Finnish, German, Danish, Italian, and Spanish. This helps separate a language model's wine expertise from its language skills. The benchmark datasets were developed in close collaboration with a professional sommelier and native speakers of the respective languages, resulting in 1,024 wine theory question-answering questions, 1,000 wine feature-completion examples, and 1,000 food-wine pairing examples. We provide results for the most popular language models, including closed-weights models such as Gemini 2.5, and open-weights models, such as GPT-OSS and Qwen 3. Our results show that the most capable models perform well on wine theory question answering (up to 97% correct with a closed-weights model), yet feature completion (peaking at 65%) and food-wine pairing show (MCC ranging between 0 and 0.39) turn out to be more challenging. These results position SommBench as an interesting and challenging benchmark for evaluating the sommelier expertise of language models. The benchmark is publicly available at https://github.com/sommify/sommbench.
FlexMoRE: A Flexible Mixture of Rank-heterogeneous Experts for Efficient Federatedly-trained Large Language Models
Feb 09, 2026Recent advances in mixture-of-experts architectures have shown that individual experts models can be trained federatedly, i.e., in isolation from other experts by using a common base model to facilitate coordination. However, we hypothesize that full-sized experts may not be necessary for all domains and that instead low-rank adapters may be sufficient. Here, we introduce FlexMoRE, a Flexible Mixture of Rank-heterogenous Experts, which may be either full-sized experts or adapters of a suitable rank. We systematically investigate the trade-off between expert rank and downstream task performance by evaluating $6$ experts with ranks $2^0$ to $2^{14}$ resulting in experiments covering 150 mixtures (96 with 2 experts, 54 with 7 experts) that are evaluated across $120$ tasks. For our experiments, we build on FlexOlmo and turn its pre-trained experts into low-rank versions. Our regression analysis from expert rank to downstream task performance reveals that the best-performing rank is substantially higher for reasoning-heavy benchmarks than for knowledge-heavy benchmarks. These findings on rank sensitivity come with direct implications for memory efficiency: Using optimal ranks, FlexMoRE yields improved downstream task performance (average score $47.18$) compared to the baseline FlexOlmo-style mixture of full-sized experts (average score $45.46$) at less than one third the parameters ($10.75$B for FlexMoRE vs. $33.27$B for FlexOlmo). All code will be made available.
Training Language Models to Use Prolog as a Tool
Dec 08, 2025Ensuring reliable tool use is critical for safe agentic AI systems. Language models frequently produce unreliable reasoning with plausible but incorrect solutions that are difficult to verify. To address this, we investigate fine-tuning models to use Prolog as an external tool for verifiable computation. Using Group Relative Policy Optimization (GRPO), we fine-tune Qwen2.5-3B-Instruct on a cleaned GSM8K-Prolog-Prover dataset while varying (i) prompt structure, (ii) reward composition (execution, syntax, semantics, structure), and (iii) inference protocol: single-shot, best-of-N, and two agentic modes where Prolog is invoked internally or independently. Our reinforcement learning approach outperforms supervised fine-tuning, with our 3B model achieving zero-shot MMLU performance comparable to 7B few-shot results. Our findings reveal that: 1) joint tuning of prompt, reward, and inference shapes program syntax and logic; 2) best-of-N with external Prolog verification maximizes accuracy on GSM8K; 3) agentic inference with internal repair yields superior zero-shot generalization on MMLU-Stem and MMLU-Pro. These results demonstrate that grounding model reasoning in formal verification systems substantially improves reliability and auditability for safety-critical applications. The source code for reproducing our experiments is available under https://github.com/niklasmellgren/grpo-prolog-inference
Achieving Hilbert-Schmidt Independence Under Rényi Differential Privacy for Fair and Private Data Generation
Aug 29, 2025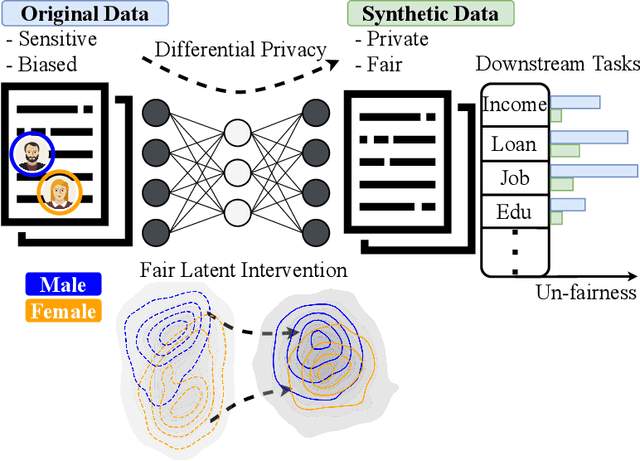
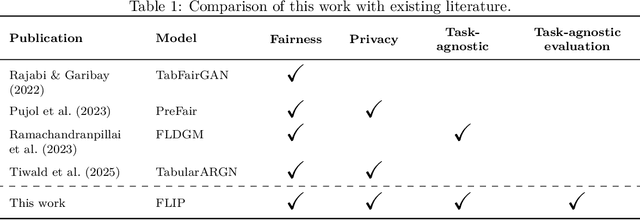
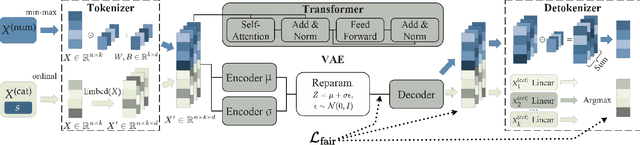

As privacy regulations such as the GDPR and HIPAA and responsibility frameworks for artificial intelligence such as the AI Act gain traction, the ethical and responsible use of real-world data faces increasing constraints. Synthetic data generation has emerged as a promising solution to risk-aware data sharing and model development, particularly for tabular datasets that are foundational to sensitive domains such as healthcare. To address both privacy and fairness concerns in this setting, we propose FLIP (Fair Latent Intervention under Privacy guarantees), a transformer-based variational autoencoder augmented with latent diffusion to generate heterogeneous tabular data. Unlike the typical setup in fairness-aware data generation, we assume a task-agnostic setup, not reliant on a fixed, defined downstream task, thus offering broader applicability. To ensure privacy, FLIP employs R\'enyi differential privacy (RDP) constraints during training and addresses fairness in the input space with RDP-compatible balanced sampling that accounts for group-specific noise levels across multiple sampling rates. In the latent space, we promote fairness by aligning neuron activation patterns across protected groups using Centered Kernel Alignment (CKA), a similarity measure extending the Hilbert-Schmidt Independence Criterion (HSIC). This alignment encourages statistical independence between latent representations and the protected feature. Empirical results demonstrate that FLIP effectively provides significant fairness improvements for task-agnostic fairness and across diverse downstream tasks under differential privacy constraints.