 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMAEB: Massive Audio Embedding Benchmark
Feb 17, 2026We introduce the Massive Audio Embedding Benchmark (MAEB), a large-scale benchmark covering 30 tasks across speech, music, environmental sounds, and cross-modal audio-text reasoning in 100+ languages. We evaluate 50+ models and find that no single model dominates across all tasks: contrastive audio-text models excel at environmental sound classification (e.g., ESC50) but score near random on multilingual speech tasks (e.g., SIB-FLEURS), while speech-pretrained models show the opposite pattern. Clustering remains challenging for all models, with even the best-performing model achieving only modest results. We observe that models excelling on acoustic understanding often perform poorly on linguistic tasks, and vice versa. We also show that the performance of audio encoders on MAEB correlates highly with their performance when used in audio large language models. MAEB is derived from MAEB+, a collection of 98 tasks. MAEB is designed to maintain task diversity while reducing evaluation cost, and it integrates into the MTEB ecosystem for unified evaluation across text, image, and audio modalities. We release MAEB and all 98 tasks along with code and a leaderboard at https://github.com/embeddings-benchmark/mteb.
Is Sentiment Banana-Shaped? Exploring the Geometry and Portability of Sentiment Concept Vectors
Jan 12, 2026Use cases of sentiment analysis in the humanities often require contextualized, continuous scores. Concept Vector Projections (CVP) offer a recent solution: by modeling sentiment as a direction in embedding space, they produce continuous, multilingual scores that align closely with human judgments. Yet the method's portability across domains and underlying assumptions remain underexplored. We evaluate CVP across genres, historical periods, languages, and affective dimensions, finding that concept vectors trained on one corpus transfer well to others with minimal performance loss. To understand the patterns of generalization, we further examine the linearity assumption underlying CVP. Our findings suggest that while CVP is a portable approach that effectively captures generalizable patterns, its linearity assumption is approximate, pointing to potential for further development.
Continuous sentiment scores for literary and multilingual contexts
Aug 20, 2025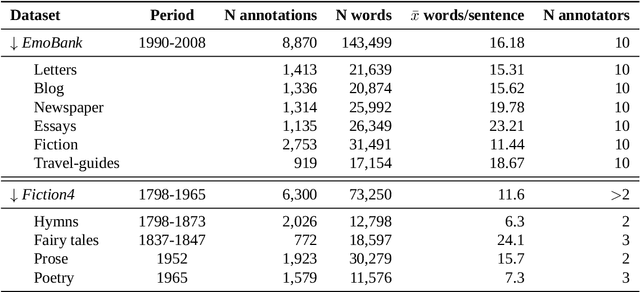
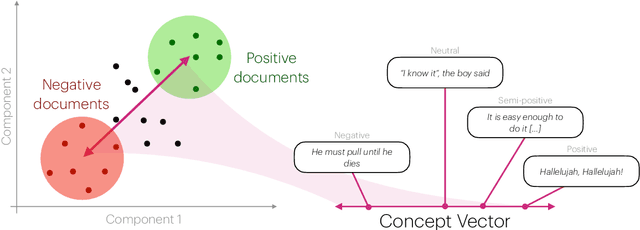
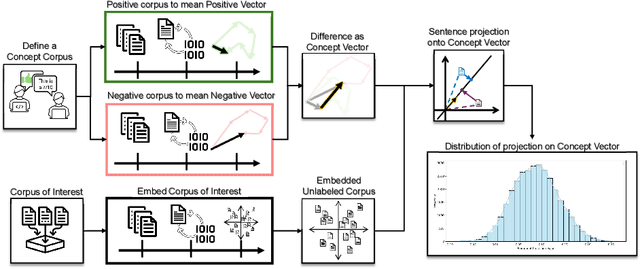
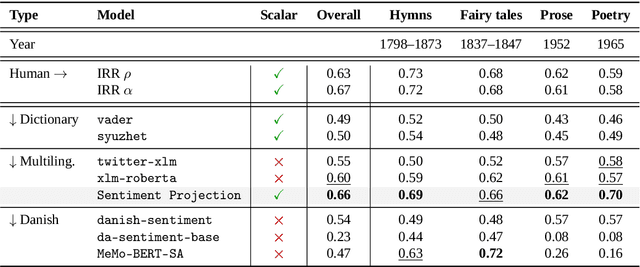
Sentiment Analysis is widely used to quantify sentiment in text, but its application to literary texts poses unique challenges due to figurative language, stylistic ambiguity, as well as sentiment evocation strategies. Traditional dictionary-based tools often underperform, especially for low-resource languages, and transformer models, while promising, typically output coarse categorical labels that limit fine-grained analysis. We introduce a novel continuous sentiment scoring method based on concept vector projection, trained on multilingual literary data, which more effectively captures nuanced sentiment expressions across genres, languages, and historical periods. Our approach outperforms existing tools on English and Danish texts, producing sentiment scores whose distribution closely matches human ratings, enabling more accurate analysis and sentiment arc modeling in literature.
MIEB: Massive Image Embedding Benchmark
Apr 14, 2025Image representations are often evaluated through disjointed, task-specific protocols, leading to a fragmented understanding of model capabilities. For instance, it is unclear whether an image embedding model adept at clustering images is equally good at retrieving relevant images given a piece of text. We introduce the Massive Image Embedding Benchmark (MIEB) to evaluate the performance of image and image-text embedding models across the broadest spectrum to date. MIEB spans 38 languages across 130 individual tasks, which we group into 8 high-level categories. We benchmark 50 models across our benchmark, finding that no single method dominates across all task categories. We reveal hidden capabilities in advanced vision models such as their accurate visual representation of texts, and their yet limited capabilities in interleaved encodings and matching images and texts in the presence of confounders. We also show that the performance of vision encoders on MIEB correlates highly with their performance when used in multimodal large language models. Our code, dataset, and leaderboard are publicly available at https://github.com/embeddings-benchmark/mteb.
MMTEB: Massive Multilingual Text Embedding Benchmark
Feb 19, 2025Text embeddings are typically evaluated on a limited set of tasks, which are constrained by language, domain, and task diversity. To address these limitations and provide a more comprehensive evaluation, we introduce the Massive Multilingual Text Embedding Benchmark (MMTEB) - a large-scale, community-driven expansion of MTEB, covering over 500 quality-controlled evaluation tasks across 250+ languages. MMTEB includes a diverse set of challenging, novel tasks such as instruction following, long-document retrieval, and code retrieval, representing the largest multilingual collection of evaluation tasks for embedding models to date. Using this collection, we develop several highly multilingual benchmarks, which we use to evaluate a representative set of models. We find that while large language models (LLMs) with billions of parameters can achieve state-of-the-art performance on certain language subsets and task categories, the best-performing publicly available model is multilingual-e5-large-instruct with only 560 million parameters. To facilitate accessibility and reduce computational cost, we introduce a novel downsampling method based on inter-task correlation, ensuring a diverse selection while preserving relative model rankings. Furthermore, we optimize tasks such as retrieval by sampling hard negatives, creating smaller but effective splits. These optimizations allow us to introduce benchmarks that drastically reduce computational demands. For instance, our newly introduced zero-shot English benchmark maintains a ranking order similar to the full-scale version but at a fraction of the computational cost.
Encoder vs Decoder: Comparative Analysis of Encoder and Decoder Language Models on Multilingual NLU Tasks
Jun 19, 2024
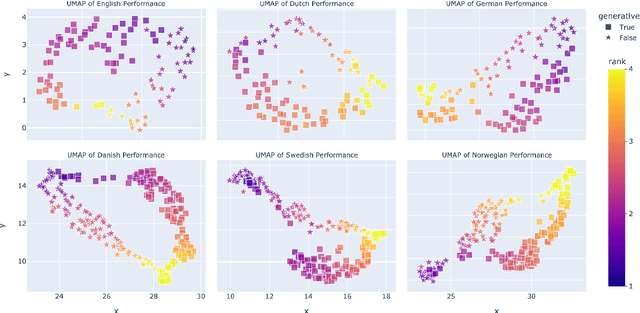

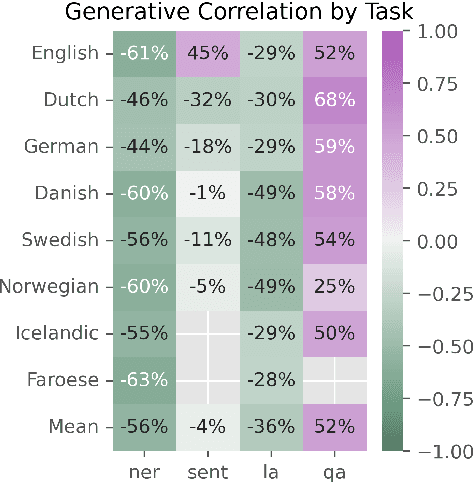
This paper explores the performance of encoder and decoder language models on multilingual Natural Language Understanding (NLU) tasks, with a broad focus on Germanic languages. Building upon the ScandEval benchmark, which initially was restricted to evaluating encoder models, we extend the evaluation framework to include decoder models. We introduce a method for evaluating decoder models on NLU tasks and apply it to the languages Danish, Swedish, Norwegian, Icelandic, Faroese, German, Dutch, and English. Through a series of experiments and analyses, we address key research questions regarding the comparative performance of encoder and decoder models, the impact of NLU task types, and the variation across language resources. Our findings reveal that decoder models can achieve significantly better NLU performance than encoder models, with nuances observed across different tasks and languages. Additionally, we investigate the correlation between decoders and task performance via a UMAP analysis, shedding light on the unique capabilities of decoder and encoder models. This study contributes to a deeper understanding of language model paradigms in NLU tasks and provides valuable insights for model selection and evaluation in multilingual settings.
$S^3$ -- Semantic Signal Separation
Jun 18, 2024



Topic models are useful tools for discovering latent semantic structures in large textual corpora. Topic modeling historically relied on bag-of-words representations of language. This approach makes models sensitive to the presence of stop words and noise, and does not utilize potentially useful contextual information. Recent efforts have been oriented at incorporating contextual neural representations in topic modeling and have been shown to outperform classical topic models. These approaches are, however, typically slow, volatile and still require preprocessing for optimal results. We present Semantic Signal Separation ($S^3$), a theory-driven topic modeling approach in neural embedding spaces. $S^3$ conceptualizes topics as independent axes of semantic space, and uncovers these with blind-source separation. Our approach provides the most diverse, highly coherent topics, requires no preprocessing, and is demonstrated to be the fastest contextually sensitive topic model to date. We offer an implementation of $S^3$, among other approaches, in the Turftopic Python package.
The Scandinavian Embedding Benchmarks: Comprehensive Assessment of Multilingual and Monolingual Text Embedding
Jun 04, 2024The evaluation of English text embeddings has transitioned from evaluating a handful of datasets to broad coverage across many tasks through benchmarks such as MTEB. However, this is not the case for multilingual text embeddings due to a lack of available benchmarks. To address this problem, we introduce the Scandinavian Embedding Benchmark (SEB). SEB is a comprehensive framework that enables text embedding evaluation for Scandinavian languages across 24 tasks, 10 subtasks, and 4 task categories. Building on SEB, we evaluate more than 26 models, uncovering significant performance disparities between public and commercial solutions not previously captured by MTEB. We open-source SEB and integrate it with MTEB, thus bridging the text embedding evaluation gap for Scandinavian languages.
DANSK and DaCy 2.6.0: Domain Generalization of Danish Named Entity Recognition
Feb 28, 2024Named entity recognition is one of the cornerstones of Danish NLP, essential for language technology applications within both industry and research. However, Danish NER is inhibited by a lack of available datasets. As a consequence, no current models are capable of fine-grained named entity recognition, nor have they been evaluated for potential generalizability issues across datasets and domains. To alleviate these limitations, this paper introduces: 1) DANSK: a named entity dataset providing for high-granularity tagging as well as within-domain evaluation of models across a diverse set of domains; 2) DaCy 2.6.0 that includes three generalizable models with fine-grained annotation; and 3) an evaluation of current state-of-the-art models' ability to generalize across domains. The evaluation of existing and new models revealed notable performance discrepancies across domains, which should be addressed within the field. Shortcomings of the annotation quality of the dataset and its impact on model training and evaluation are also discussed. Despite these limitations, we advocate for the use of the new dataset DANSK alongside further work on the generalizability within Danish NER.
Augmenty: A Python Library for Structured Text Augmentation
Dec 09, 2023Augmnety is a Python library for structured text augmentation. It is built on top of spaCy and allows for augmentation of both the text and its annotations. Augmenty provides a wide range of augmenters which can be combined in a flexible manner to create complex augmentation pipelines. It also includes a set of primitives that can be used to create custom augmenters such as word replacement augmenters. This functionality allows for augmentations within a range of applications such as named entity recognition (NER), part-of-speech tagging, and dependency parsing.