 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Coverage Illusion: From Pre-retrieval Routing Failure to Post-retrieval Cascades in a Production RAG System
May 26, 2026In modern RAG pipelines, query augmentation methods such as HyDE and query expansion are applied to every query, resulting in substantial LLM inference costs and increased end-to-end latency. The empirical justification for this overhead in real production traffic remains largely unexplored. We present a case study of the Danish National Encyclopedia, evaluating five retrieval workflows over 20,000 query-workflow pairs from production traffic and synthetic conditions. In this system, synthetic queries suggest that LLM augmentation is needed for over 90% of queries to achieve high retrieval coverage. However, under our production deferral policy, only 27.8% of real user queries need LLM augmentation. We call this gap the Coverage Illusion and attribute it to a structural mismatch between synthetic and real query distributions. Pre-retrieval routing cannot resolve this gap, as the need for LLM augmentation is only revealed after searching the index, a result confirmed by our evaluation of four machine learning paradigms. The coverage gap, undetectable from the query alone, motivates a post-retrieval cascade that runs workflows in cheapest-first order and escalates to LLM augmentation only when a step returns no documents. Operating entirely without training overhead or secondary serving infrastructure, the cascade improves quality by +0.140 Composite Overall points over Always-HyDE, reduces latency by 31.8%, and serves 72.2% of real user queries without LLM augmentation.
Naturalistic measure of social norms alignment
May 22, 2026Social norms reflect shared expectations on acceptable behavior. Measuring social norms alignment remains challenging, with existing approaches typically relying on artificial closed-form evaluations such as multiple-choice questionnaires or measuring agreement with predefined statements. In the context of this work, social norms alignment refers to measuring an agreement between solutions with respect to the social problem or dilemma. We propose a framework for measuring social norm alignment in naturalistic, free-form settings through solution matching. The framework enables us to measure alignment between any two dilemma responses e.g., LLMs to a human, LLMs to LLMs, or human to human. We introduce two metrics: stated and explicit agreement accuracy, and construct a dataset of 3k non-trivial social dilemmas in Danish. All dilemmas are assigned reference solutions derived from three panelists, who serve as culturally grounded judges. We evaluate the agreement of several LLMs and human responses in an interaction setup that resembles natural user-model conversations. Our results show that the proposed metrics produce consistent model rankings and reveal variation in agreement across different types of dilemmas, with higher agreement observed for topics such as neighbor conflicts and shared living situations. Overall, our work introduces a dataset and evaluation framework for studying culturally grounded social reasoning in naturalistic open-ended conversations.
Closed-form predictive coding via hierarchical Gaussian filters
May 19, 2026Predictive coding (PC) offers a local and biologically grounded alternative to backpropagation in the training of artificial neural networks, yet to date, it remains slower, and performance degrades sharply as network depth increases. We trace both problems to a single simplification: current PC networks fix the precision matrix to the identity, discarding precision-weighted prediction errors that the variational derivation requires to be fast, local, and Bayesian. We close this gap by expressing predictive coding networks as deep hierarchical Gaussian filters (HGFs) and restore precision-weighted message passing, yielding dynamic uncertainty estimates and Hebbian-compatible update rules at every layer. The resulting networks can simultaneously learn activations, weights, and precisions under a single free-energy objective, with no global error signal, and resolve inference without requiring iterations or automatic differentiation. On FashionMNIST, our solution approaches backpropagation in epoch-level wall-clock cost while converging in fewer epochs, and outperforms it on online, data efficiency, and concept-drift tasks. We thus establish that closed-form variational inference with online precision learning provides a tractable foundation for deep predictive coding networks, retaining biological and interpretative advantages, without requiring iterative relaxation or global error signals.
Continuous sentiment scores for literary and multilingual contexts
Aug 20, 2025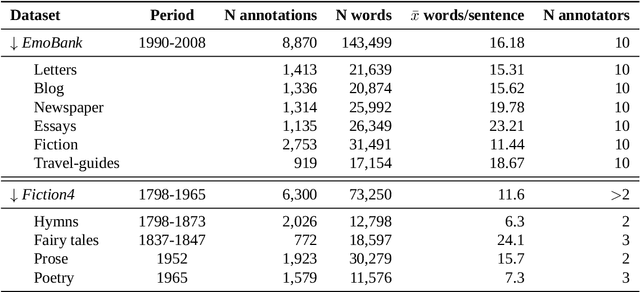
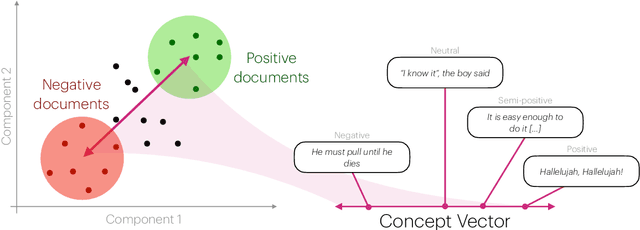
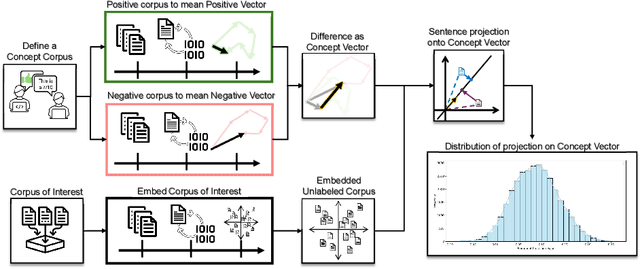
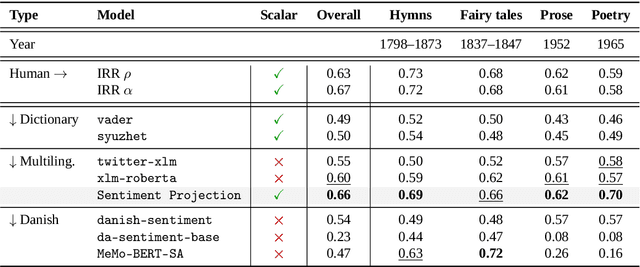
Sentiment Analysis is widely used to quantify sentiment in text, but its application to literary texts poses unique challenges due to figurative language, stylistic ambiguity, as well as sentiment evocation strategies. Traditional dictionary-based tools often underperform, especially for low-resource languages, and transformer models, while promising, typically output coarse categorical labels that limit fine-grained analysis. We introduce a novel continuous sentiment scoring method based on concept vector projection, trained on multilingual literary data, which more effectively captures nuanced sentiment expressions across genres, languages, and historical periods. Our approach outperforms existing tools on English and Danish texts, producing sentiment scores whose distribution closely matches human ratings, enabling more accurate analysis and sentiment arc modeling in literature.
$S^3$ -- Semantic Signal Separation
Jun 18, 2024



Topic models are useful tools for discovering latent semantic structures in large textual corpora. Topic modeling historically relied on bag-of-words representations of language. This approach makes models sensitive to the presence of stop words and noise, and does not utilize potentially useful contextual information. Recent efforts have been oriented at incorporating contextual neural representations in topic modeling and have been shown to outperform classical topic models. These approaches are, however, typically slow, volatile and still require preprocessing for optimal results. We present Semantic Signal Separation ($S^3$), a theory-driven topic modeling approach in neural embedding spaces. $S^3$ conceptualizes topics as independent axes of semantic space, and uncovers these with blind-source separation. Our approach provides the most diverse, highly coherent topics, requires no preprocessing, and is demonstrated to be the fastest contextually sensitive topic model to date. We offer an implementation of $S^3$, among other approaches, in the Turftopic Python package.
Good Books are Complex Matters: Gauging Complexity Profiles Across Diverse Categories of Perceived Literary Quality
Apr 14, 2024In this study, we employ a classification approach to show that different categories of literary "quality" display unique linguistic profiles, leveraging a corpus that encompasses titles from the Norton Anthology, Penguin Classics series, and the Open Syllabus project, contrasted against contemporary bestsellers, Nobel prize winners and recipients of prestigious literary awards. Our analysis reveals that canonical and so called high-brow texts exhibit distinct textual features when compared to other quality categories such as bestsellers and popular titles as well as to control groups, likely responding to distinct (but not mutually exclusive) models of quality. We apply a classic machine learning approach, namely Random Forest, to distinguish quality novels from "control groups", achieving up to 77\% F1 scores in differentiating between the categories. We find that quality category tend to be easier to distinguish from control groups than from other quality categories, suggesting than literary quality features might be distinguishable but shared through quality proxies.
Danish Foundation Models
Nov 13, 2023

Large language models, sometimes referred to as foundation models, have transformed multiple fields of research. However, smaller languages risk falling behind due to high training costs and small incentives for large companies to train these models. To combat this, the Danish Foundation Models project seeks to provide and maintain open, well-documented, and high-quality foundation models for the Danish language. This is achieved through broad cooperation with public and private institutions, to ensure high data quality and applicability of the trained models. We present the motivation of the project, the current status, and future perspectives.
Sentiment Dynamics of Success: Fractal Scaling of Story Arcs Predicts Reader Preferences
Dec 14, 2021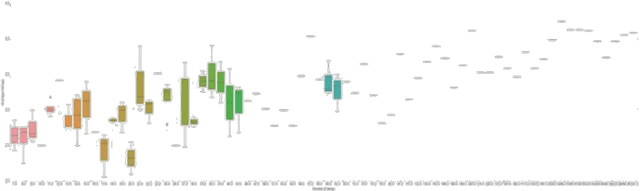
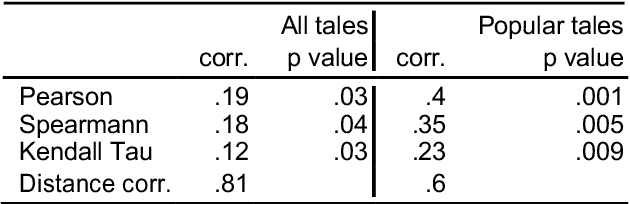
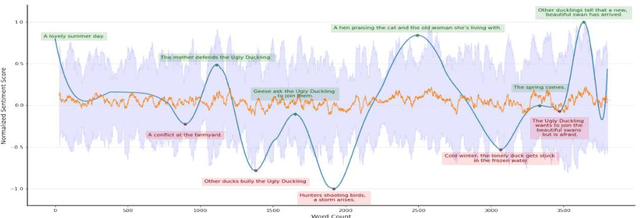
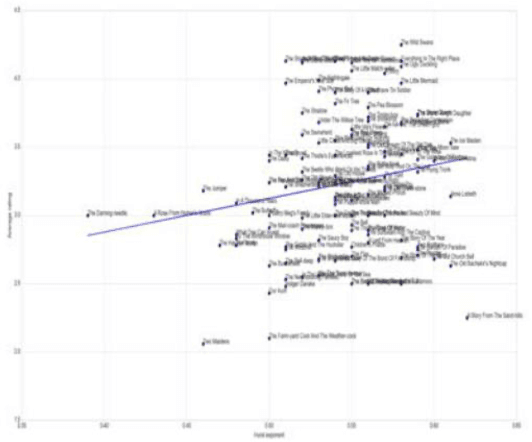
We explore the correlation between the sentiment arcs of H. C. Andersen's fairy tales and their popularity, measured as their average score on the platform GoodReads. Specifically, we do not conceive a story's overall sentimental trend as predictive \textit{per se}, but we focus on its coherence and predictability over time as represented by the arc's Hurst exponent. We find that degrading Hurst values tend to imply degrading quality scores, while a Hurst exponent between .55 and .65 might indicate a "sweet spot" for literary appreciation.
DaCy: A Unified Framework for Danish NLP
Jul 12, 2021
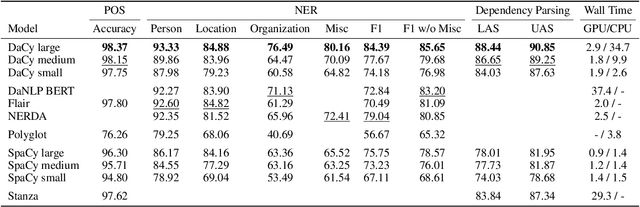
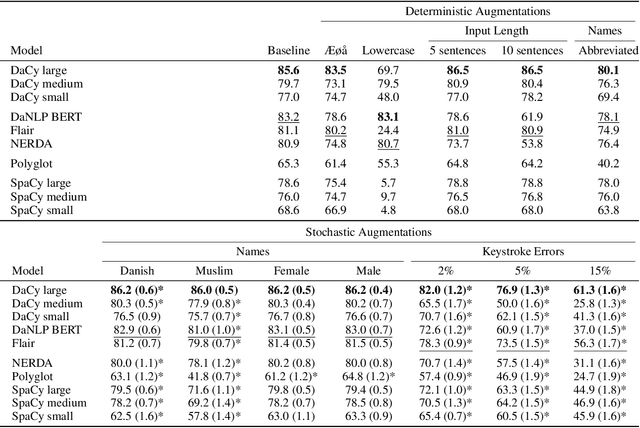
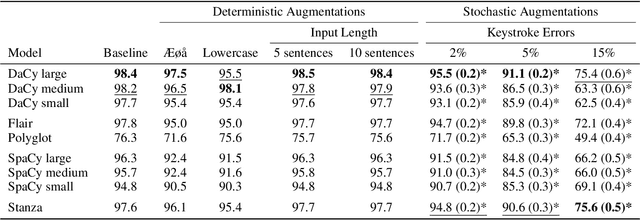
Danish natural language processing (NLP) has in recent years obtained considerable improvements with the addition of multiple new datasets and models. However, at present, there is no coherent framework for applying state-of-the-art models for Danish. We present DaCy: a unified framework for Danish NLP built on SpaCy. DaCy uses efficient multitask models which obtain state-of-the-art performance on named entity recognition, part-of-speech tagging, and dependency parsing. DaCy contains tools for easy integration of existing models such as for polarity, emotion, or subjectivity detection. In addition, we conduct a series of tests for biases and robustness of Danish NLP pipelines through augmentation of the test set of DaNE. DaCy large compares favorably and is especially robust to long input lengths and spelling variations and errors. All models except DaCy large display significant biases related to ethnicity while only Polyglot shows a significant gender bias. We argue that for languages with limited benchmark sets, data augmentation can be particularly useful for obtaining more realistic and fine-grained performance estimates. We provide a series of augmenters as a first step towards a more thorough evaluation of language models for low and medium resource languages and encourage further development.