 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIs Sentiment Banana-Shaped? Exploring the Geometry and Portability of Sentiment Concept Vectors
Jan 12, 2026Use cases of sentiment analysis in the humanities often require contextualized, continuous scores. Concept Vector Projections (CVP) offer a recent solution: by modeling sentiment as a direction in embedding space, they produce continuous, multilingual scores that align closely with human judgments. Yet the method's portability across domains and underlying assumptions remain underexplored. We evaluate CVP across genres, historical periods, languages, and affective dimensions, finding that concept vectors trained on one corpus transfer well to others with minimal performance loss. To understand the patterns of generalization, we further examine the linearity assumption underlying CVP. Our findings suggest that while CVP is a portable approach that effectively captures generalizable patterns, its linearity assumption is approximate, pointing to potential for further development.
Continuous sentiment scores for literary and multilingual contexts
Aug 20, 2025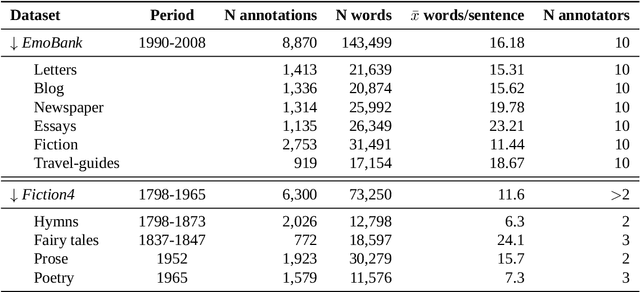
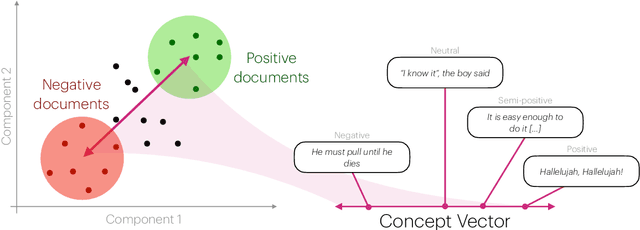
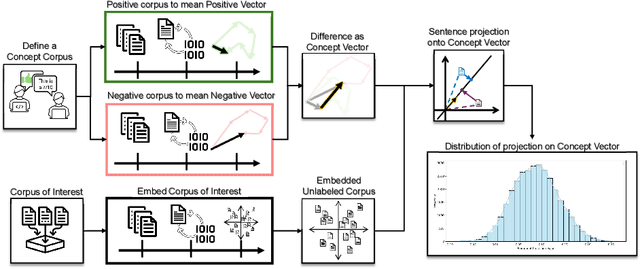
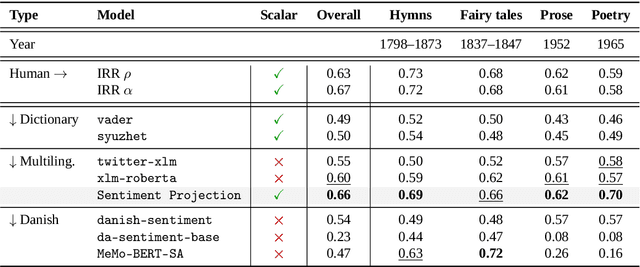
Sentiment Analysis is widely used to quantify sentiment in text, but its application to literary texts poses unique challenges due to figurative language, stylistic ambiguity, as well as sentiment evocation strategies. Traditional dictionary-based tools often underperform, especially for low-resource languages, and transformer models, while promising, typically output coarse categorical labels that limit fine-grained analysis. We introduce a novel continuous sentiment scoring method based on concept vector projection, trained on multilingual literary data, which more effectively captures nuanced sentiment expressions across genres, languages, and historical periods. Our approach outperforms existing tools on English and Danish texts, producing sentiment scores whose distribution closely matches human ratings, enabling more accurate analysis and sentiment arc modeling in literature.
Says Who? Effective Zero-Shot Annotation of Focalization
Sep 17, 2024Focalization, the perspective through which narrative is presented, is encoded via a wide range of lexico-grammatical features and is subject to reader interpretation. Moreover, trained readers regularly disagree on interpretations, suggesting that this problem may be computationally intractable. In this paper, we provide experiments to test how well contemporary Large Language Models (LLMs) perform when annotating literary texts for focalization mode. Despite the challenging nature of the task, LLMs show comparable performance to trained human annotators in our experiments. We provide a case study working with the novels of Stephen King to demonstrate the usefulness of this approach for computational literary studies, illustrating how focalization can be studied at scale.
Good Books are Complex Matters: Gauging Complexity Profiles Across Diverse Categories of Perceived Literary Quality
Apr 14, 2024In this study, we employ a classification approach to show that different categories of literary "quality" display unique linguistic profiles, leveraging a corpus that encompasses titles from the Norton Anthology, Penguin Classics series, and the Open Syllabus project, contrasted against contemporary bestsellers, Nobel prize winners and recipients of prestigious literary awards. Our analysis reveals that canonical and so called high-brow texts exhibit distinct textual features when compared to other quality categories such as bestsellers and popular titles as well as to control groups, likely responding to distinct (but not mutually exclusive) models of quality. We apply a classic machine learning approach, namely Random Forest, to distinguish quality novels from "control groups", achieving up to 77\% F1 scores in differentiating between the categories. We find that quality category tend to be easier to distinguish from control groups than from other quality categories, suggesting than literary quality features might be distinguishable but shared through quality proxies.