 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAlignment Drift in CEFR-prompted LLMs for Interactive Spanish Tutoring
May 13, 2025This paper investigates the potentials of Large Language Models (LLMs) as adaptive tutors in the context of second-language learning. In particular, we evaluate whether system prompting can reliably constrain LLMs to generate only text appropriate to the student's competence level. We simulate full teacher-student dialogues in Spanish using instruction-tuned, open-source LLMs ranging in size from 7B to 12B parameters. Dialogues are generated by having an LLM alternate between tutor and student roles with separate chat histories. The output from the tutor model is then used to evaluate the effectiveness of CEFR-based prompting to control text difficulty across three proficiency levels (A1, B1, C1). Our findings suggest that while system prompting can be used to constrain model outputs, prompting alone is too brittle for sustained, long-term interactional contexts - a phenomenon we term alignment drift. Our results provide insights into the feasibility of LLMs for personalized, proficiency-aligned adaptive tutors and provide a scalable method for low-cost evaluation of model performance without human participants.
I only read it for the plot! Maturity Ratings Affect Fanfiction Style and Community Engagement
Apr 07, 2025



We consider the textual profiles of different fanfiction maturity ratings, how they vary across fan groups, and how this relates to reader engagement metrics. Previous studies have shown that fanfiction writing is motivated by a combination of admiration for and frustration with the fan object. These findings emerge when looking at fanfiction as a whole, as well as when it is divided into subgroups, also called fandoms. However, maturity ratings are used to indicate the intended audience of the fanfiction, as well as whether the story includes mature themes and explicit scenes. Since these ratings can be used to filter readers and writers, they can also be seen as a proxy for different reader/writer motivations and desires. We find that explicit fanfiction in particular has a distinct textual profile when compared to other maturity ratings. These findings thus nuance our understanding of reader/writer motivations in fanfiction communities, and also highlights the influence of the community norms and fan behavior more generally on these cultural products.
Context is Key(NMF): Modelling Topical Information Dynamics in Chinese Diaspora Media
Oct 16, 2024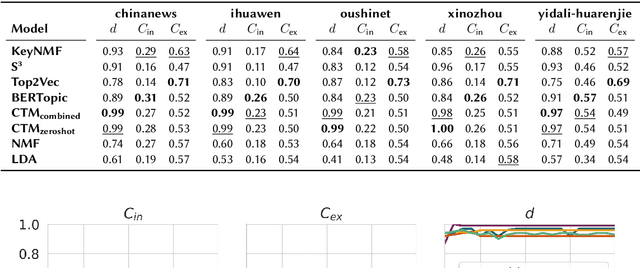
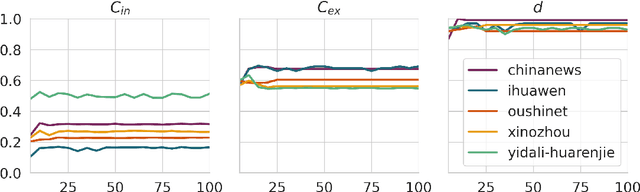
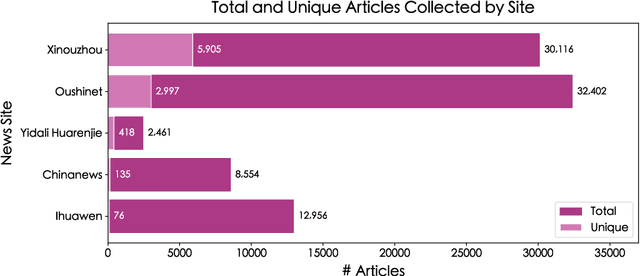
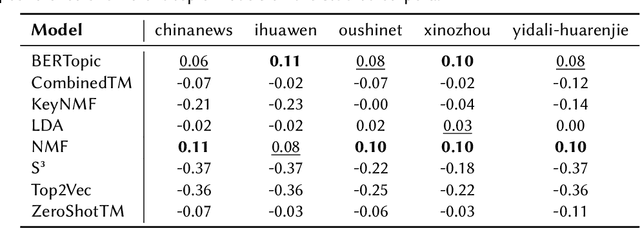
Does the People's Republic of China (PRC) interfere with European elections through ethnic Chinese diaspora media? This question forms the basis of an ongoing research project exploring how PRC narratives about European elections are represented in Chinese diaspora media, and thus the objectives of PRC news media manipulation. In order to study diaspora media efficiently and at scale, it is necessary to use techniques derived from quantitative text analysis, such as topic modelling. In this paper, we present a pipeline for studying information dynamics in Chinese media. Firstly, we present KeyNMF, a new approach to static and dynamic topic modelling using transformer-based contextual embedding models. We provide benchmark evaluations to demonstrate that our approach is competitive on a number of Chinese datasets and metrics. Secondly, we integrate KeyNMF with existing methods for describing information dynamics in complex systems. We apply this pipeline to data from five news sites, focusing on the period of time leading up to the 2024 European parliamentary elections. Our methods and results demonstrate the effectiveness of KeyNMF for studying information dynamics in Chinese media and lay groundwork for further work addressing the broader research questions.
Science is Exploration: Computational Frontiers for Conceptual Metaphor Theory
Oct 11, 2024
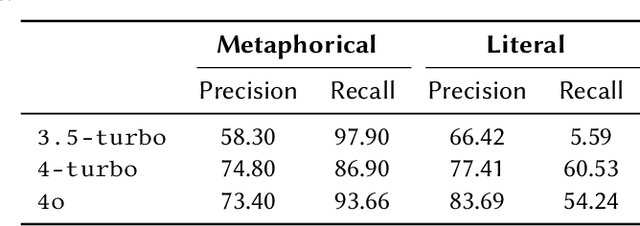

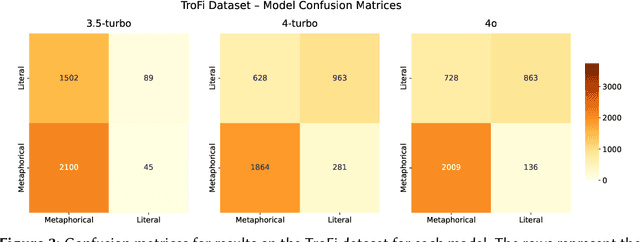
Metaphors are everywhere. They appear extensively across all domains of natural language, from the most sophisticated poetry to seemingly dry academic prose. A significant body of research in the cognitive science of language argues for the existence of conceptual metaphors, the systematic structuring of one domain of experience in the language of another. Conceptual metaphors are not simply rhetorical flourishes but are crucial evidence of the role of analogical reasoning in human cognition. In this paper, we ask whether Large Language Models (LLMs) can accurately identify and explain the presence of such conceptual metaphors in natural language data. Using a novel prompting technique based on metaphor annotation guidelines, we demonstrate that LLMs are a promising tool for large-scale computational research on conceptual metaphors. Further, we show that LLMs are able to apply procedural guidelines designed for human annotators, displaying a surprising depth of linguistic knowledge.
Says Who? Effective Zero-Shot Annotation of Focalization
Sep 17, 2024Focalization, the perspective through which narrative is presented, is encoded via a wide range of lexico-grammatical features and is subject to reader interpretation. Moreover, trained readers regularly disagree on interpretations, suggesting that this problem may be computationally intractable. In this paper, we provide experiments to test how well contemporary Large Language Models (LLMs) perform when annotating literary texts for focalization mode. Despite the challenging nature of the task, LLMs show comparable performance to trained human annotators in our experiments. We provide a case study working with the novels of Stephen King to demonstrate the usefulness of this approach for computational literary studies, illustrating how focalization can be studied at scale.
Chatbots Are Not Reliable Text Annotators
Nov 09, 2023Recent research highlights the significant potential of ChatGPT for text annotation in social science research. However, ChatGPT is a closed-source product which has major drawbacks with regards to transparency, reproducibility, cost, and data protection. Recent advances in open-source (OS) large language models (LLMs) offer alternatives which remedy these challenges. This means that it is important to evaluate the performance of OS LLMs relative to ChatGPT and standard approaches to supervised machine learning classification. We conduct a systematic comparative evaluation of the performance of a range of OS LLM models alongside ChatGPT, using both zero- and few-shot learning as well as generic and custom prompts, with results compared to more traditional supervised classification models. Using a new dataset of Tweets from US news media, and focusing on simple binary text annotation tasks for standard social science concepts, we find significant variation in the performance of ChatGPT and OS models across the tasks, and that supervised classifiers consistently outperform both. Given the unreliable performance of ChatGPT and the significant challenges it poses to Open Science we advise against using ChatGPT for substantive text annotation tasks in social science research.