 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAttention Flows: Tracing LLM Conceptual Engagement via Story Summaries
Apr 07, 2026Although LLM context lengths have grown, there is evidence that their ability to integrate information across long-form texts has not kept pace. We evaluate one such understanding task: generating summaries of novels. When human authors of summaries compress a story, they reveal what they consider narratively important. Therefore, by comparing human and LLM-authored summaries, we can assess whether models mirror human patterns of conceptual engagement with texts. To measure conceptual engagement, we align sentences from 150 human-written novel summaries with the specific chapters they reference. We demonstrate the difficulty of this alignment task, which indicates the complexity of summarization as a task. We then generate and align additional summaries by nine state-of-the-art LLMs for each of the 150 reference texts. Comparing the human and model-authored summaries, we find both stylistic differences between the texts and differences in how humans and LLMs distribute their focus throughout a narrative, with models emphasizing the ends of texts. Comparing human narrative engagement with model attention mechanisms suggests explanations for degraded narrative comprehension and targets for future development. We release our dataset to support future research.
Too Long, Didn't Model: Decomposing LLM Long-Context Understanding With Novels
May 20, 2025Although the context length of large language models (LLMs) has increased to millions of tokens, evaluating their effectiveness beyond needle-in-a-haystack approaches has proven difficult. We argue that novels provide a case study of subtle, complicated structure and long-range semantic dependencies often over 128k tokens in length. Inspired by work on computational novel analysis, we release the Too Long, Didn't Model (TLDM) benchmark, which tests a model's ability to report plot summary, storyworld configuration, and elapsed narrative time. We find that none of seven tested frontier LLMs retain stable understanding beyond 64k tokens. Our results suggest language model developers must look beyond "lost in the middle" benchmarks when evaluating model performance in complex long-context scenarios. To aid in further development we release the TLDM benchmark together with reference code and data.
The Zero Body Problem: Probing LLM Use of Sensory Language
Apr 08, 2025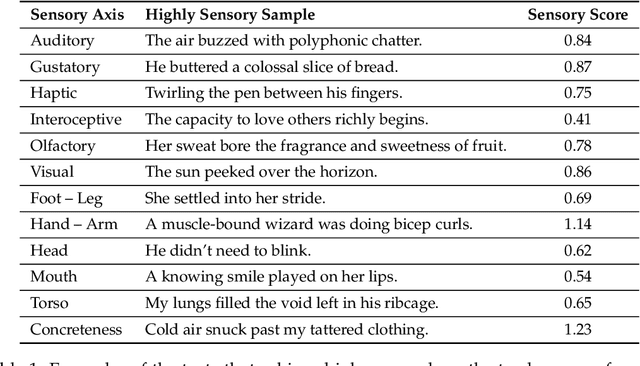
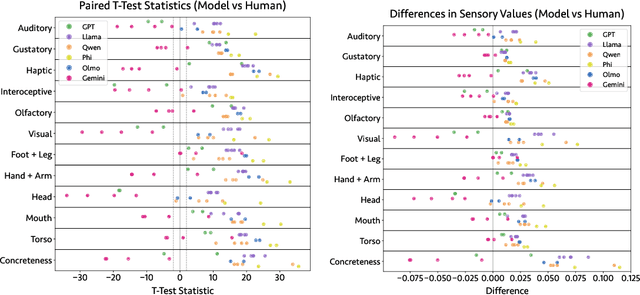
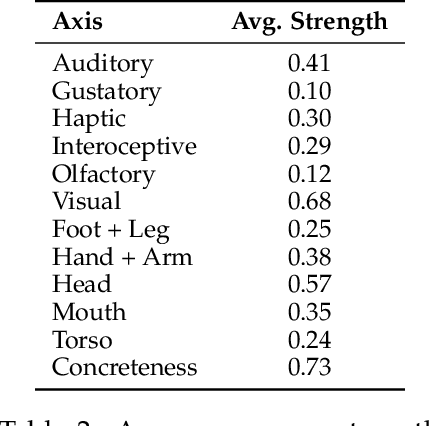
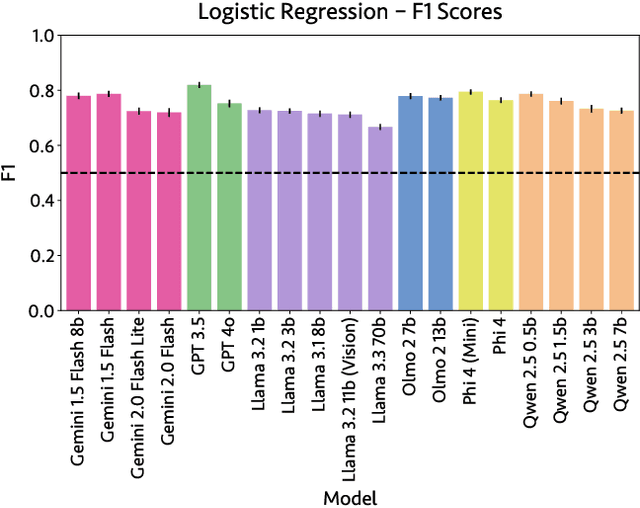
Sensory language expresses embodied experiences ranging from taste and sound to excitement and stomachache. This language is of interest to scholars from a wide range of domains including robotics, narratology, linguistics, and cognitive science. In this work, we explore whether language models, which are not embodied, can approximate human use of embodied language. We extend an existing corpus of parallel human and model responses to short story prompts with an additional 18,000 stories generated by 18 popular models. We find that all models generate stories that differ significantly from human usage of sensory language, but the direction of these differences varies considerably between model families. Namely, Gemini models use significantly more sensory language than humans along most axes whereas most models from the remaining five families use significantly less. Linear probes run on five models suggest that they are capable of identifying sensory language. However, we find preliminary evidence suggesting that instruction tuning may discourage usage of sensory language. Finally, to support further work, we release our expanded story dataset.
A City of Millions: Mapping Literary Social Networks At Scale
Feb 26, 2025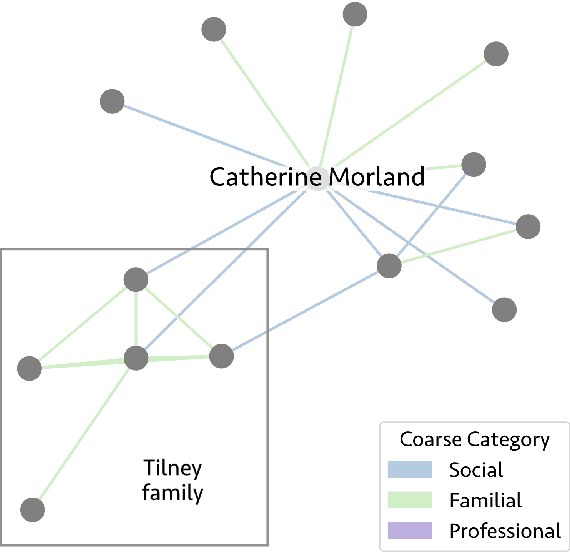
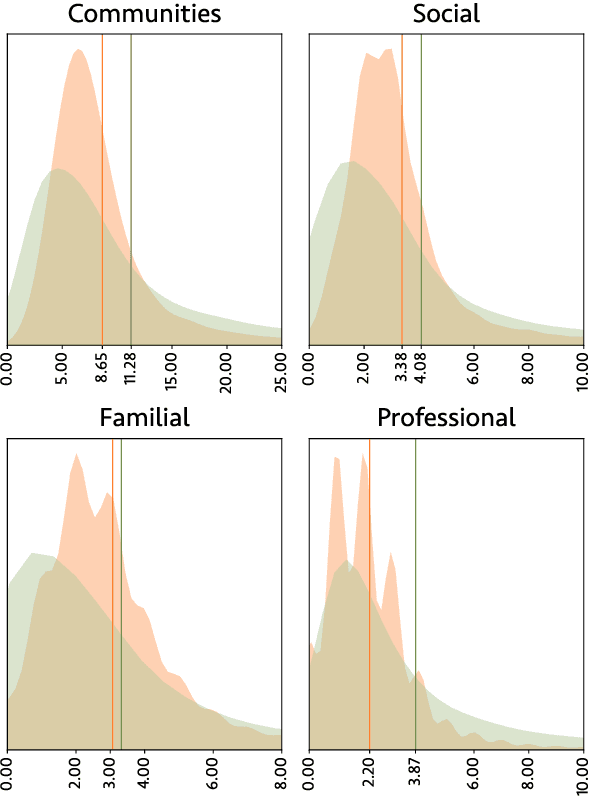
We release 70,509 high-quality social networks extracted from multilingual fiction and nonfiction narratives. We additionally provide metadata for ~30,000 of these texts (73% nonfiction and 27% fiction) written between 1800 and 1999 in 58 languages. This dataset provides information on historical social worlds at an unprecedented scale, including data for 1,192,855 individuals in 2,805,482 pair-wise relationships annotated for affinity and relationship type. We achieve this scale by automating previously manual methods of extracting social networks; specifically, we adapt an existing annotation task as a language model prompt, ensuring consistency at scale with the use of structured output. This dataset provides an unprecedented resource for the humanities and social sciences by providing data on cognitive models of social realities.
Looking for the Inner Music: Probing LLMs' Understanding of Literary Style
Feb 05, 2025



Recent work has demonstrated that language models can be trained to identify the author of much shorter literary passages than has been thought feasible for traditional stylometry. We replicate these results for authorship and extend them to a new dataset measuring novel genre. We find that LLMs are able to distinguish authorship and genre, but they do so in different ways. Some models seem to rely more on memorization, while others benefit more from training to learn author/genre characteristics. We then use three methods to probe one high-performing LLM for features that define style. These include direct syntactic ablations to input text as well as two methods that look at model internals. We find that authorial style is easier to define than genre-level style and is more impacted by minor syntactic decisions and contextual word usage. However, some traits like pronoun usage and word order prove significant for defining both kinds of literary style.
Context is Key(NMF): Modelling Topical Information Dynamics in Chinese Diaspora Media
Oct 16, 2024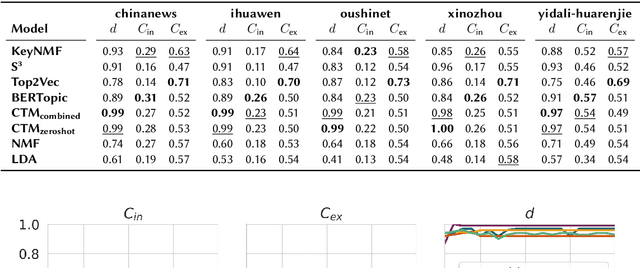
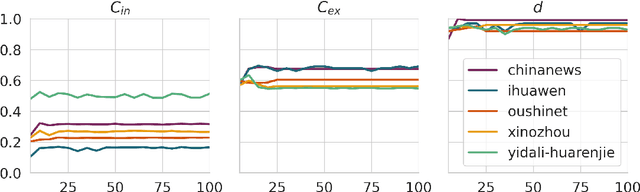
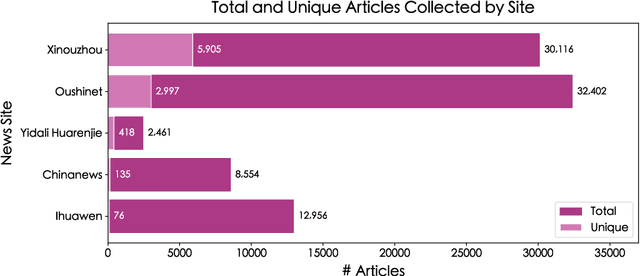
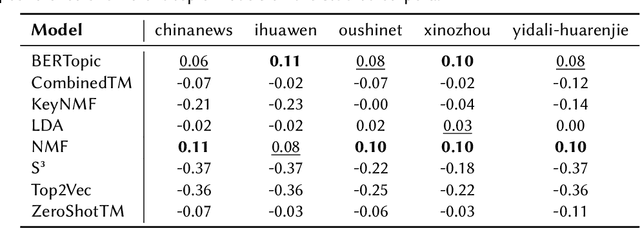
Does the People's Republic of China (PRC) interfere with European elections through ethnic Chinese diaspora media? This question forms the basis of an ongoing research project exploring how PRC narratives about European elections are represented in Chinese diaspora media, and thus the objectives of PRC news media manipulation. In order to study diaspora media efficiently and at scale, it is necessary to use techniques derived from quantitative text analysis, such as topic modelling. In this paper, we present a pipeline for studying information dynamics in Chinese media. Firstly, we present KeyNMF, a new approach to static and dynamic topic modelling using transformer-based contextual embedding models. We provide benchmark evaluations to demonstrate that our approach is competitive on a number of Chinese datasets and metrics. Secondly, we integrate KeyNMF with existing methods for describing information dynamics in complex systems. We apply this pipeline to data from five news sites, focusing on the period of time leading up to the 2024 European parliamentary elections. Our methods and results demonstrate the effectiveness of KeyNMF for studying information dynamics in Chinese media and lay groundwork for further work addressing the broader research questions.
Science is Exploration: Computational Frontiers for Conceptual Metaphor Theory
Oct 11, 2024
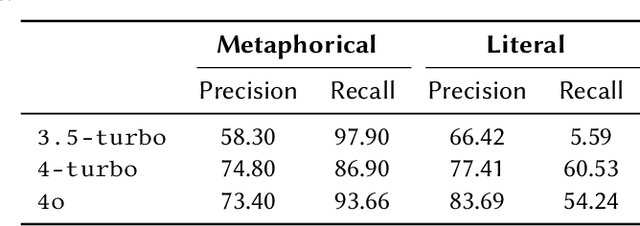

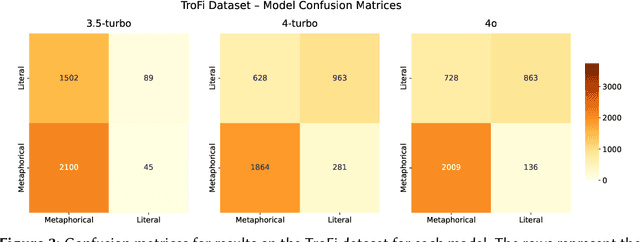
Metaphors are everywhere. They appear extensively across all domains of natural language, from the most sophisticated poetry to seemingly dry academic prose. A significant body of research in the cognitive science of language argues for the existence of conceptual metaphors, the systematic structuring of one domain of experience in the language of another. Conceptual metaphors are not simply rhetorical flourishes but are crucial evidence of the role of analogical reasoning in human cognition. In this paper, we ask whether Large Language Models (LLMs) can accurately identify and explain the presence of such conceptual metaphors in natural language data. Using a novel prompting technique based on metaphor annotation guidelines, we demonstrate that LLMs are a promising tool for large-scale computational research on conceptual metaphors. Further, we show that LLMs are able to apply procedural guidelines designed for human annotators, displaying a surprising depth of linguistic knowledge.
Says Who? Effective Zero-Shot Annotation of Focalization
Sep 17, 2024Focalization, the perspective through which narrative is presented, is encoded via a wide range of lexico-grammatical features and is subject to reader interpretation. Moreover, trained readers regularly disagree on interpretations, suggesting that this problem may be computationally intractable. In this paper, we provide experiments to test how well contemporary Large Language Models (LLMs) perform when annotating literary texts for focalization mode. Despite the challenging nature of the task, LLMs show comparable performance to trained human annotators in our experiments. We provide a case study working with the novels of Stephen King to demonstrate the usefulness of this approach for computational literary studies, illustrating how focalization can be studied at scale.
and and , Oh My! Literary Coreference Annotation with LLMs
Jan 31, 2024
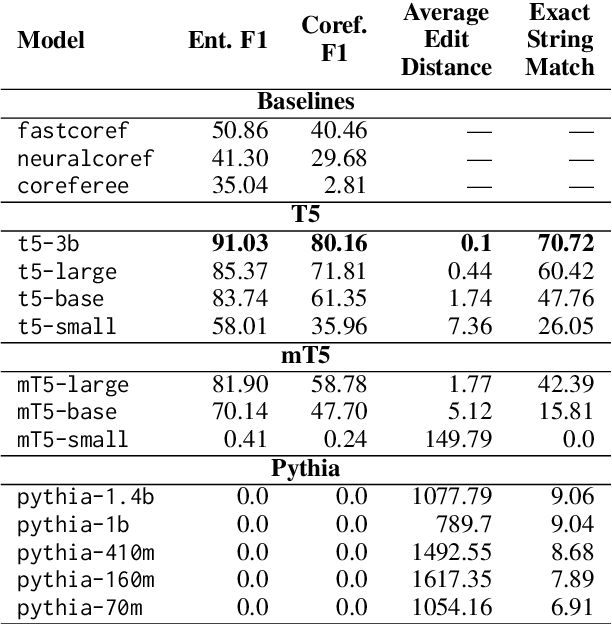
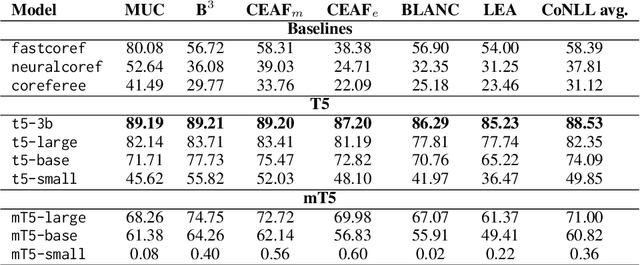
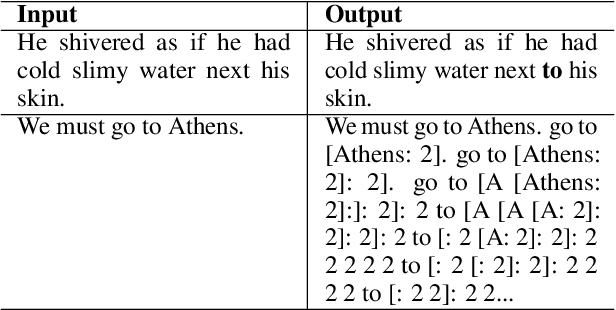
Coreference annotation and resolution is a vital component of computational literary studies. However, it has previously been difficult to build high quality systems for fiction. Coreference requires complicated structured outputs, and literary text involves subtle inferences and highly varied language. New language-model-based seq2seq systems present the opportunity to solve both these problems by learning to directly generate a copy of an input sentence with markdown-like annotations. We create, evaluate, and release several trained models for coreference, as well as a workflow for training new models.
T5 meets Tybalt: Author Attribution in Early Modern English Drama Using Large Language Models
Oct 27, 2023
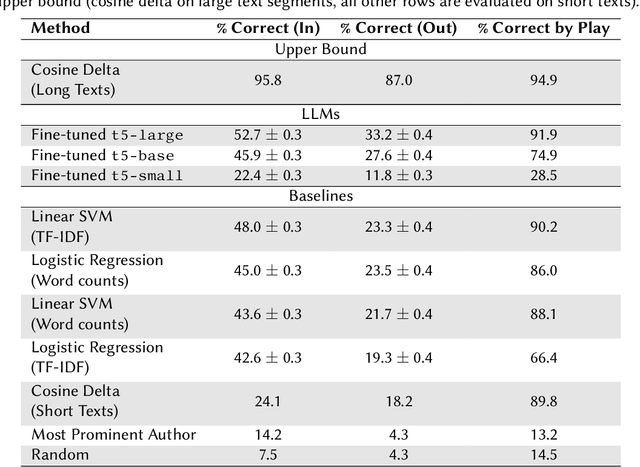
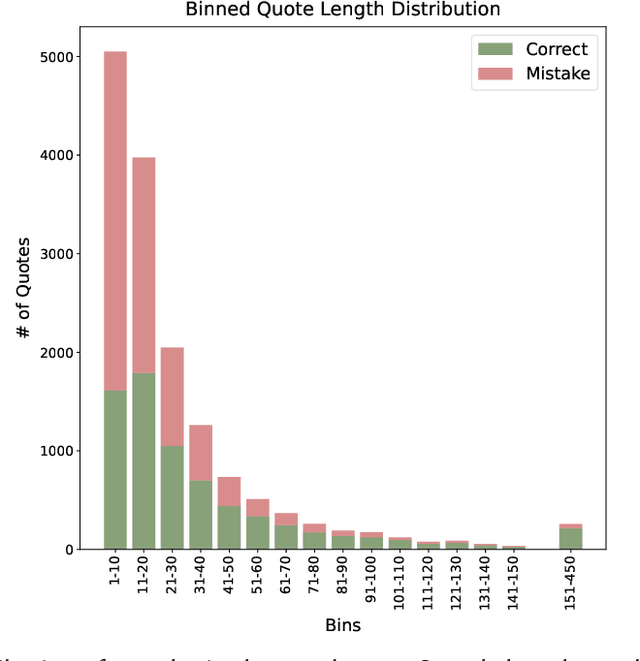
Large language models have shown breakthrough potential in many NLP domains. Here we consider their use for stylometry, specifically authorship identification in Early Modern English drama. We find both promising and concerning results; LLMs are able to accurately predict the author of surprisingly short passages but are also prone to confidently misattribute texts to specific authors. A fine-tuned t5-large model outperforms all tested baselines, including logistic regression, SVM with a linear kernel, and cosine delta, at attributing small passages. However, we see indications that the presence of certain authors in the model's pre-training data affects predictive results in ways that are difficult to assess.