Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edgeand and , Oh My! Literary Coreference Annotation with LLMs
Paper and Code
Jan 31, 2024
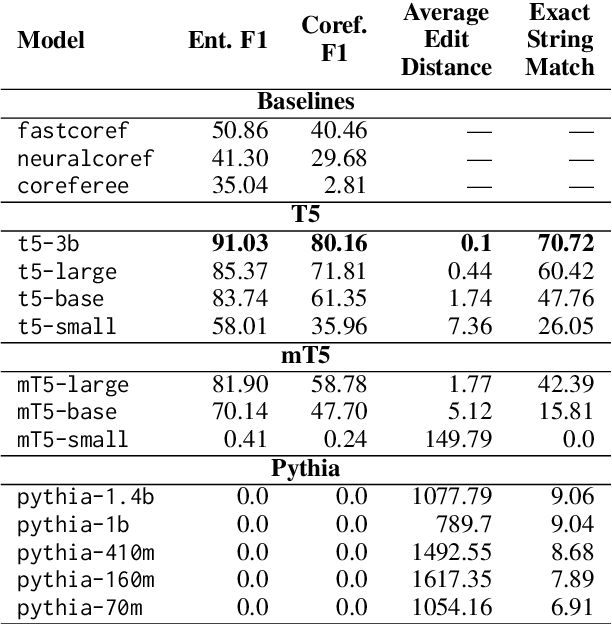
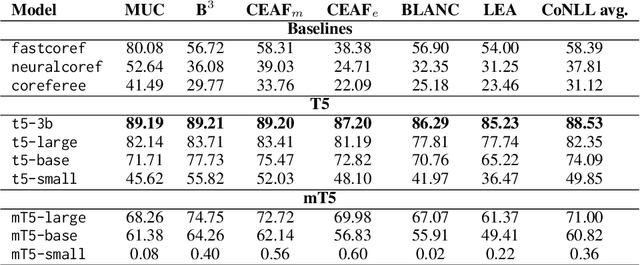
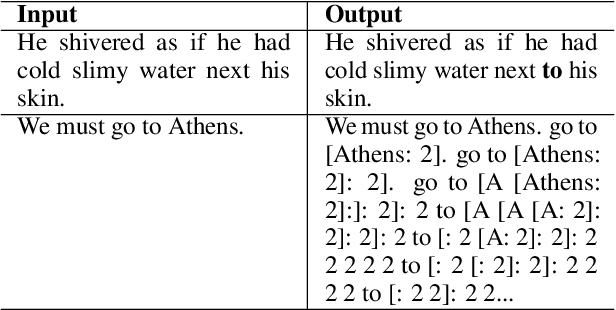
Coreference annotation and resolution is a vital component of computational literary studies. However, it has previously been difficult to build high quality systems for fiction. Coreference requires complicated structured outputs, and literary text involves subtle inferences and highly varied language. New language-model-based seq2seq systems present the opportunity to solve both these problems by learning to directly generate a copy of an input sentence with markdown-like annotations. We create, evaluate, and release several trained models for coreference, as well as a workflow for training new models.
* Accepted to LaTeCH-CLfL 2024
View paper on