 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAgent Bain vs. Agent McKinsey: A New Text-to-SQL Benchmark for the Business Domain
Oct 08, 2025In the business domain, where data-driven decision making is crucial, text-to-SQL is fundamental for easy natural language access to structured data. While recent LLMs have achieved strong performance in code generation, existing text-to-SQL benchmarks remain focused on factual retrieval of past records. We introduce CORGI, a new benchmark specifically designed for real-world business contexts. CORGI is composed of synthetic databases inspired by enterprises such as Doordash, Airbnb, and Lululemon. It provides questions across four increasingly complex categories of business queries: descriptive, explanatory, predictive, and recommendational. This challenge calls for causal reasoning, temporal forecasting, and strategic recommendation, reflecting multi-level and multi-step agentic intelligence. We find that LLM performance drops on high-level questions, struggling to make accurate predictions and offer actionable plans. Based on execution success rate, the CORGI benchmark is about 21\% more difficult than the BIRD benchmark. This highlights the gap between popular LLMs and the need for real-world business intelligence. We release a public dataset and evaluation framework, and a website for public submissions.
Cheaper, Better, Faster, Stronger: Robust Text-to-SQL without Chain-of-Thought or Fine-Tuning
May 20, 2025LLMs are effective at code generation tasks like text-to-SQL, but is it worth the cost? Many state-of-the-art approaches use non-task-specific LLM techniques including Chain-of-Thought (CoT), self-consistency, and fine-tuning. These methods can be costly at inference time, sometimes requiring over a hundred LLM calls with reasoning, incurring average costs of up to \$0.46 per query, while fine-tuning models can cost thousands of dollars. We introduce "N-rep" consistency, a more cost-efficient text-to-SQL approach that achieves similar BIRD benchmark scores as other more expensive methods, at only \$0.039 per query. N-rep leverages multiple representations of the same schema input to mitigate weaknesses in any single representation, making the solution more robust and allowing the use of smaller and cheaper models without any reasoning or fine-tuning. To our knowledge, N-rep is the best-performing text-to-SQL approach in its cost range.
Too Long, Didn't Model: Decomposing LLM Long-Context Understanding With Novels
May 20, 2025Although the context length of large language models (LLMs) has increased to millions of tokens, evaluating their effectiveness beyond needle-in-a-haystack approaches has proven difficult. We argue that novels provide a case study of subtle, complicated structure and long-range semantic dependencies often over 128k tokens in length. Inspired by work on computational novel analysis, we release the Too Long, Didn't Model (TLDM) benchmark, which tests a model's ability to report plot summary, storyworld configuration, and elapsed narrative time. We find that none of seven tested frontier LLMs retain stable understanding beyond 64k tokens. Our results suggest language model developers must look beyond "lost in the middle" benchmarks when evaluating model performance in complex long-context scenarios. To aid in further development we release the TLDM benchmark together with reference code and data.
The Zero Body Problem: Probing LLM Use of Sensory Language
Apr 08, 2025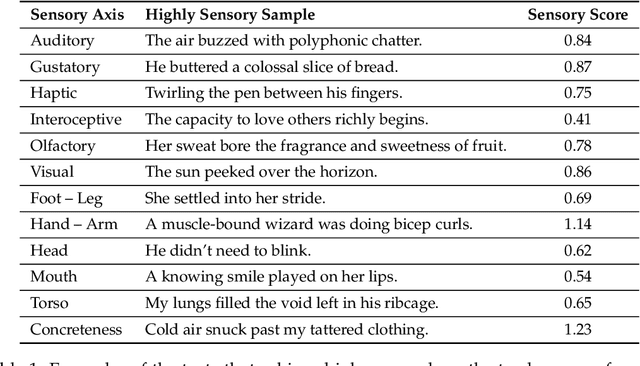
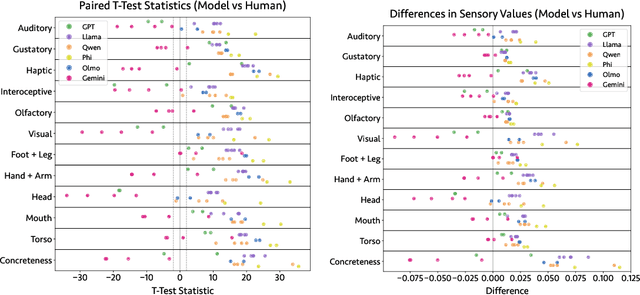
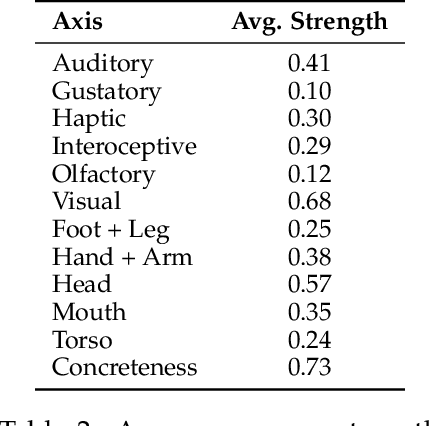
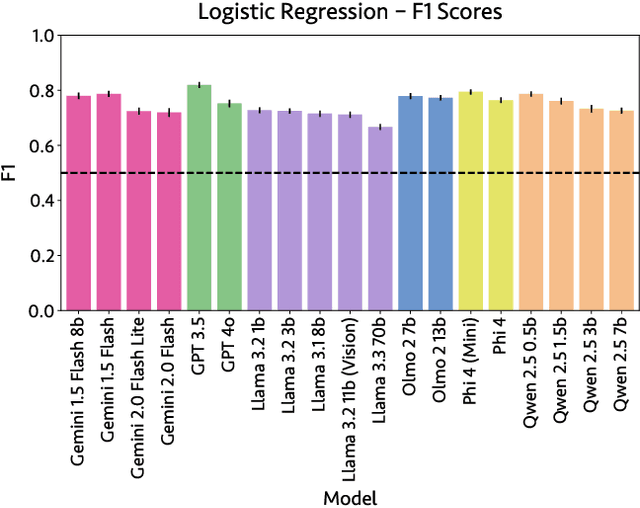
Sensory language expresses embodied experiences ranging from taste and sound to excitement and stomachache. This language is of interest to scholars from a wide range of domains including robotics, narratology, linguistics, and cognitive science. In this work, we explore whether language models, which are not embodied, can approximate human use of embodied language. We extend an existing corpus of parallel human and model responses to short story prompts with an additional 18,000 stories generated by 18 popular models. We find that all models generate stories that differ significantly from human usage of sensory language, but the direction of these differences varies considerably between model families. Namely, Gemini models use significantly more sensory language than humans along most axes whereas most models from the remaining five families use significantly less. Linear probes run on five models suggest that they are capable of identifying sensory language. However, we find preliminary evidence suggesting that instruction tuning may discourage usage of sensory language. Finally, to support further work, we release our expanded story dataset.
Tasks and Roles in Legal AI: Data Curation, Annotation, and Verification
Apr 02, 2025The application of AI tools to the legal field feels natural: large legal document collections could be used with specialized AI to improve workflow efficiency for lawyers and ameliorate the "justice gap" for underserved clients. However, legal documents differ from the web-based text that underlies most AI systems. The challenges of legal AI are both specific to the legal domain, and confounded with the expectation of AI's high performance in high-stakes settings. We identify three areas of special relevance to practitioners: data curation, data annotation, and output verification. First, it is difficult to obtain usable legal texts. Legal collections are inconsistent, analog, and scattered for reasons technical, economic, and jurisdictional. AI tools can assist document curation efforts, but the lack of existing data also limits AI performance. Second, legal data annotation typically requires significant expertise to identify complex phenomena such as modes of judicial reasoning or controlling precedents. We describe case studies of AI systems that have been developed to improve the efficiency of human annotation in legal contexts and identify areas of underperformance. Finally, AI-supported work in the law is valuable only if results are verifiable and trustworthy. We describe both the abilities of AI systems to support evaluation of their outputs, as well as new approaches to systematic evaluation of computational systems in complex domains. We call on both legal and AI practitioners to collaborate across disciplines and to release open access materials to support the development of novel, high-performing, and reliable AI tools for legal applications.
Do Chinese models speak Chinese languages?
Mar 31, 2025
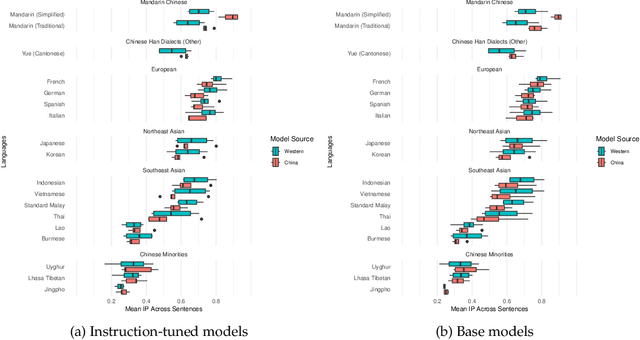


The release of top-performing open-weight LLMs has cemented China's role as a leading force in AI development. Do these models support languages spoken in China? Or do they speak the same languages as Western models? Comparing multilingual capabilities is important for two reasons. First, language ability provides insights into pre-training data curation, and thus into resource allocation and development priorities. Second, China has a long history of explicit language policy, varying between inclusivity of minority languages and a Mandarin-first policy. To test whether Chinese LLMs today reflect an agenda about China's languages, we test performance of Chinese and Western open-source LLMs on Asian regional and Chinese minority languages. Our experiments on Information Parity and reading comprehension show Chinese models' performance across these languages correlates strongly (r=0.93) with Western models', with the sole exception being better Mandarin. Sometimes, Chinese models cannot identify languages spoken by Chinese minorities such as Kazakh and Uyghur, even though they are good at French and German. These results provide a window into current development priorities, suggest options for future development, and indicate guidance for end users.
Provocations from the Humanities for Generative AI Research
Feb 26, 2025This paper presents a set of provocations for considering the uses, impact, and harms of generative AI from the perspective of humanities researchers. We provide a working definition of humanities research, summarize some of its most salient theories and methods, and apply these theories and methods to the current landscape of AI. Drawing from foundational work in critical data studies, along with relevant humanities scholarship, we elaborate eight claims with broad applicability to current conversations about generative AI: 1) Models make words, but people make meaning; 2) Generative AI requires an expanded definition of culture; 3) Generative AI can never be representative; 4) Bigger models are not always better models; 5) Not all training data is equivalent; 6) Openness is not an easy fix; 7) Limited access to compute enables corporate capture; and 8) AI universalism creates narrow human subjects. We conclude with a discussion of the importance of resisting the extraction of humanities research by computer science and related fields.
A City of Millions: Mapping Literary Social Networks At Scale
Feb 26, 2025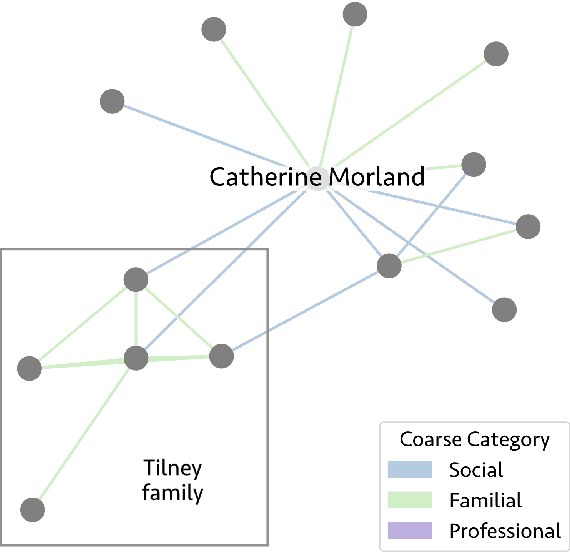
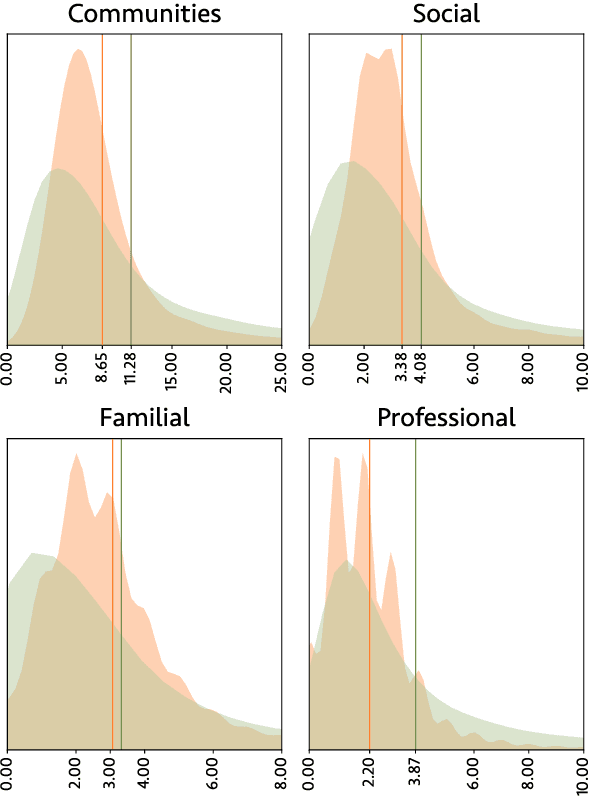
We release 70,509 high-quality social networks extracted from multilingual fiction and nonfiction narratives. We additionally provide metadata for ~30,000 of these texts (73% nonfiction and 27% fiction) written between 1800 and 1999 in 58 languages. This dataset provides information on historical social worlds at an unprecedented scale, including data for 1,192,855 individuals in 2,805,482 pair-wise relationships annotated for affinity and relationship type. We achieve this scale by automating previously manual methods of extracting social networks; specifically, we adapt an existing annotation task as a language model prompt, ensuring consistency at scale with the use of structured output. This dataset provides an unprecedented resource for the humanities and social sciences by providing data on cognitive models of social realities.
Lost in Space: Optimizing Tokens for Grammar-Constrained Decoding
Feb 20, 2025General-purpose language models are trained to produce varied natural language outputs, but for some tasks like annotation or classification we need more specific output formats. LLM systems increasingly support structured output, sampling tokens according to a grammar, which enforces a format but which can also reduce performance. We ask whether there are systematic differences between grammars that appear semantically similar to humans. To answer this question, we test four popular model families with five token formats on four NLP benchmarks. All models perform most accurately when instructed to classify with real numbers. Performance also improves by 5%-10% when models are instructed to return tokens incorporating leading whitespace, which we find can help models avoid structural deficiencies in subword token representations. Format-based differences are largest for smaller models that are often used for local laptop-scale inference. We present best practices for researchers using language models as zero-shot classifiers with structured output.
Looking for the Inner Music: Probing LLMs' Understanding of Literary Style
Feb 05, 2025



Recent work has demonstrated that language models can be trained to identify the author of much shorter literary passages than has been thought feasible for traditional stylometry. We replicate these results for authorship and extend them to a new dataset measuring novel genre. We find that LLMs are able to distinguish authorship and genre, but they do so in different ways. Some models seem to rely more on memorization, while others benefit more from training to learn author/genre characteristics. We then use three methods to probe one high-performing LLM for features that define style. These include direct syntactic ablations to input text as well as two methods that look at model internals. We find that authorial style is easier to define than genre-level style and is more impacted by minor syntactic decisions and contextual word usage. However, some traits like pronoun usage and word order prove significant for defining both kinds of literary style.