 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA City of Millions: Mapping Literary Social Networks At Scale
Paper and Code
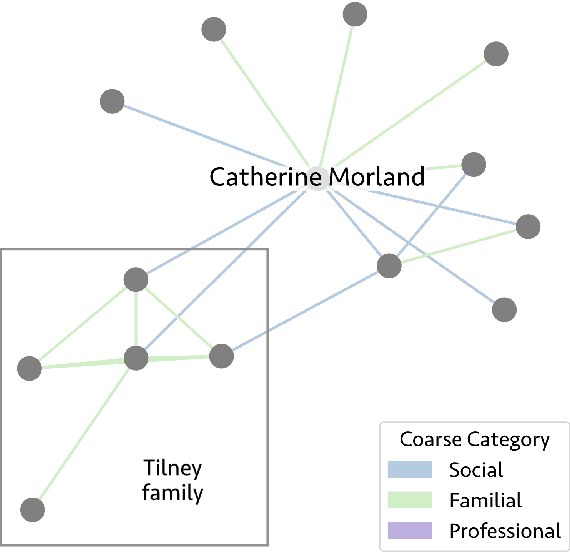
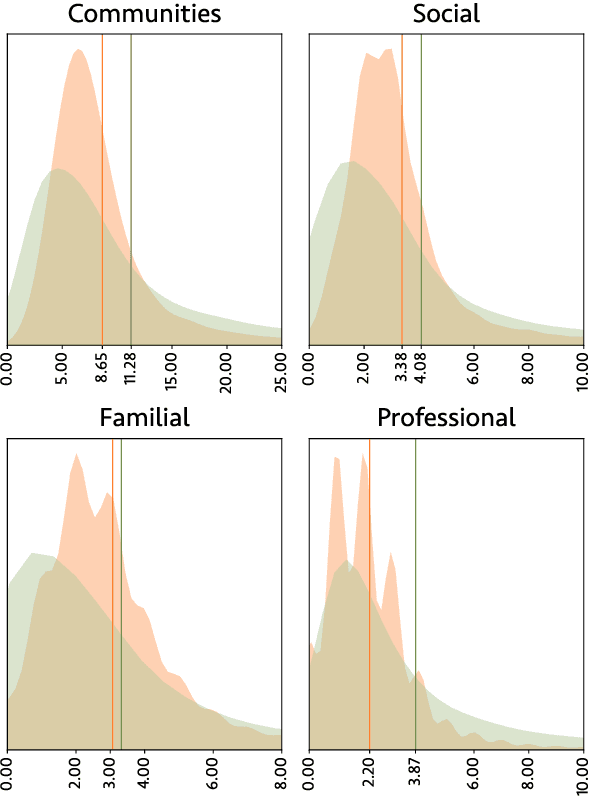
We release 70,509 high-quality social networks extracted from multilingual fiction and nonfiction narratives. We additionally provide metadata for ~30,000 of these texts (73% nonfiction and 27% fiction) written between 1800 and 1999 in 58 languages. This dataset provides information on historical social worlds at an unprecedented scale, including data for 1,192,855 individuals in 2,805,482 pair-wise relationships annotated for affinity and relationship type. We achieve this scale by automating previously manual methods of extracting social networks; specifically, we adapt an existing annotation task as a language model prompt, ensuring consistency at scale with the use of structured output. This dataset provides an unprecedented resource for the humanities and social sciences by providing data on cognitive models of social realities.