 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeToo Long, Didn't Model: Decomposing LLM Long-Context Understanding With Novels
May 20, 2025Although the context length of large language models (LLMs) has increased to millions of tokens, evaluating their effectiveness beyond needle-in-a-haystack approaches has proven difficult. We argue that novels provide a case study of subtle, complicated structure and long-range semantic dependencies often over 128k tokens in length. Inspired by work on computational novel analysis, we release the Too Long, Didn't Model (TLDM) benchmark, which tests a model's ability to report plot summary, storyworld configuration, and elapsed narrative time. We find that none of seven tested frontier LLMs retain stable understanding beyond 64k tokens. Our results suggest language model developers must look beyond "lost in the middle" benchmarks when evaluating model performance in complex long-context scenarios. To aid in further development we release the TLDM benchmark together with reference code and data.
The Zero Body Problem: Probing LLM Use of Sensory Language
Apr 08, 2025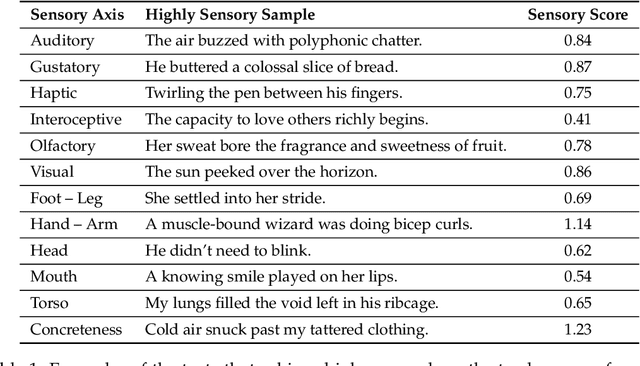
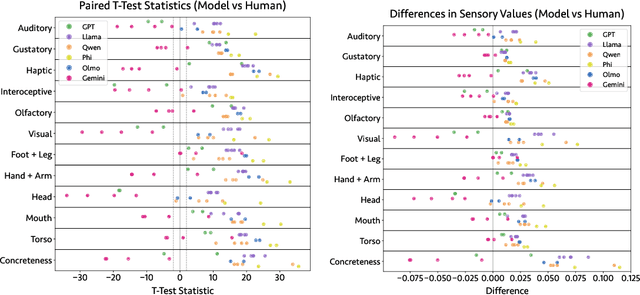
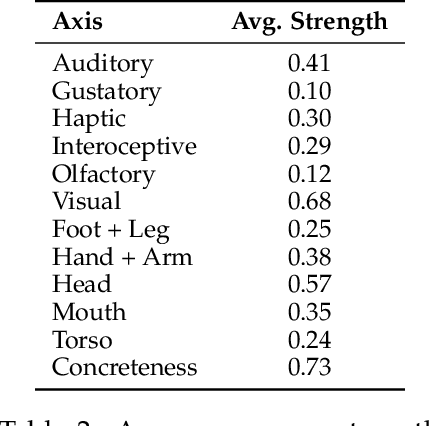
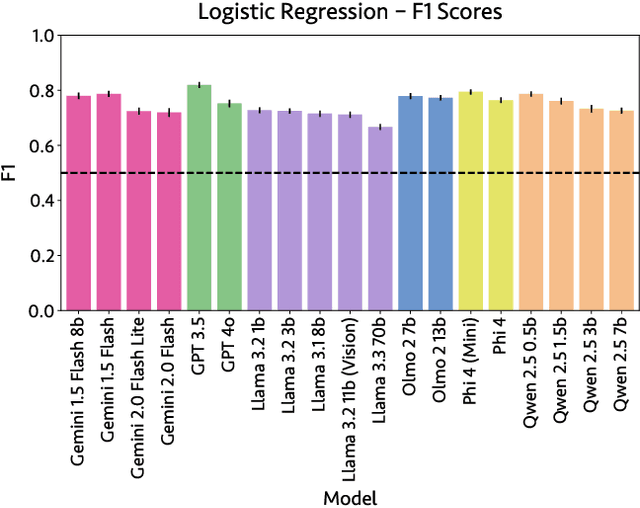
Sensory language expresses embodied experiences ranging from taste and sound to excitement and stomachache. This language is of interest to scholars from a wide range of domains including robotics, narratology, linguistics, and cognitive science. In this work, we explore whether language models, which are not embodied, can approximate human use of embodied language. We extend an existing corpus of parallel human and model responses to short story prompts with an additional 18,000 stories generated by 18 popular models. We find that all models generate stories that differ significantly from human usage of sensory language, but the direction of these differences varies considerably between model families. Namely, Gemini models use significantly more sensory language than humans along most axes whereas most models from the remaining five families use significantly less. Linear probes run on five models suggest that they are capable of identifying sensory language. However, we find preliminary evidence suggesting that instruction tuning may discourage usage of sensory language. Finally, to support further work, we release our expanded story dataset.
A City of Millions: Mapping Literary Social Networks At Scale
Feb 26, 2025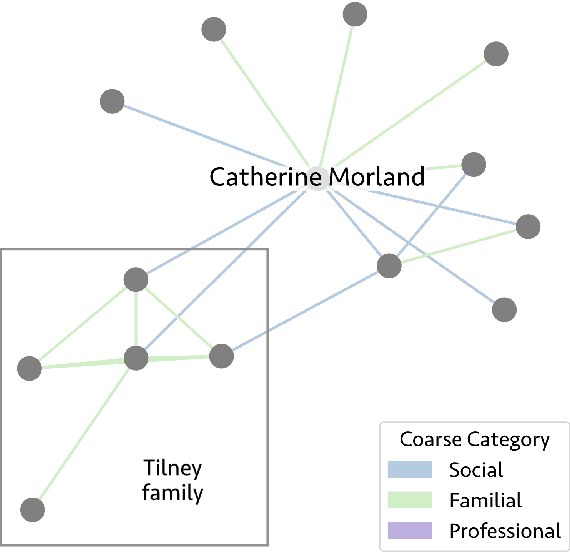
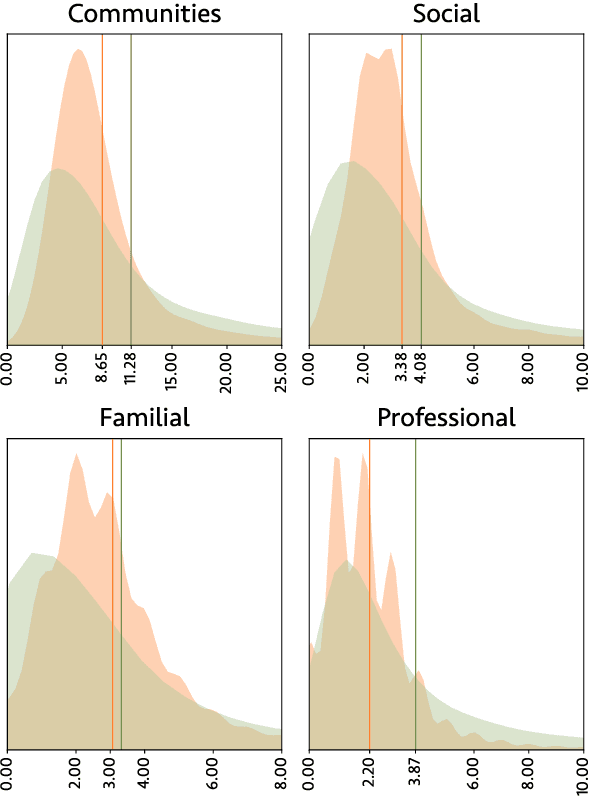
We release 70,509 high-quality social networks extracted from multilingual fiction and nonfiction narratives. We additionally provide metadata for ~30,000 of these texts (73% nonfiction and 27% fiction) written between 1800 and 1999 in 58 languages. This dataset provides information on historical social worlds at an unprecedented scale, including data for 1,192,855 individuals in 2,805,482 pair-wise relationships annotated for affinity and relationship type. We achieve this scale by automating previously manual methods of extracting social networks; specifically, we adapt an existing annotation task as a language model prompt, ensuring consistency at scale with the use of structured output. This dataset provides an unprecedented resource for the humanities and social sciences by providing data on cognitive models of social realities.
Lost in Space: Optimizing Tokens for Grammar-Constrained Decoding
Feb 20, 2025General-purpose language models are trained to produce varied natural language outputs, but for some tasks like annotation or classification we need more specific output formats. LLM systems increasingly support structured output, sampling tokens according to a grammar, which enforces a format but which can also reduce performance. We ask whether there are systematic differences between grammars that appear semantically similar to humans. To answer this question, we test four popular model families with five token formats on four NLP benchmarks. All models perform most accurately when instructed to classify with real numbers. Performance also improves by 5%-10% when models are instructed to return tokens incorporating leading whitespace, which we find can help models avoid structural deficiencies in subword token representations. Format-based differences are largest for smaller models that are often used for local laptop-scale inference. We present best practices for researchers using language models as zero-shot classifiers with structured output.
Detecting Mode Collapse in Language Models via Narration
Feb 06, 2024


No two authors write alike. Personal flourishes invoked in written narratives, from lexicon to rhetorical devices, imply a particular author--what literary theorists label the implied or virtual author; distinct from the real author or narrator of a text. Early large language models trained on unfiltered training sets drawn from a variety of discordant sources yielded incoherent personalities, problematic for conversational tasks but proving useful for sampling literature from multiple perspectives. Successes in alignment research in recent years have allowed researchers to impose subjectively consistent personae on language models via instruction tuning and reinforcement learning from human feedback (RLHF), but whether aligned models retain the ability to model an arbitrary virtual author has received little scrutiny. By studying 4,374 stories sampled from three OpenAI language models, we show successive versions of GPT-3 suffer from increasing degrees of "mode collapse" whereby overfitting the model during alignment constrains it from generalizing over authorship: models suffering from mode collapse become unable to assume a multiplicity of perspectives. Our method and results are significant for researchers seeking to employ language models in sociological simulations.
Blind Judgement: Agent-Based Supreme Court Modelling With GPT
Jan 12, 2023We present a novel Transformer-based multi-agent system for simulating the judicial rulings of the 2010-2016 Supreme Court of the United States. We train nine separate models with the respective authored opinions of each supreme justice active ca. 2015 and test the resulting system on 96 real-world cases. We find our system predicts the decisions of the real-world Supreme Court with better-than-random accuracy. We further find a correlation between model accuracy with respect to individual justices and their alignment between legal conservatism & liberalism. Our methods and results hold significance for researchers interested in using language models to simulate politically-charged discourse between multiple agents.
The COVID That Wasn't: Counterfactual Journalism Using GPT
Oct 13, 2022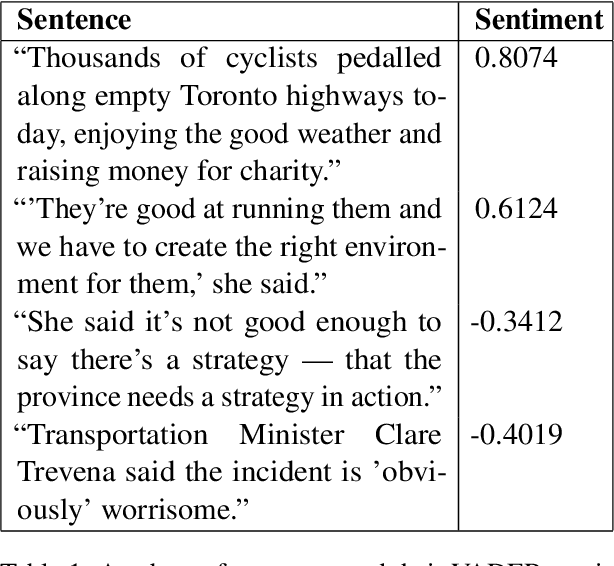
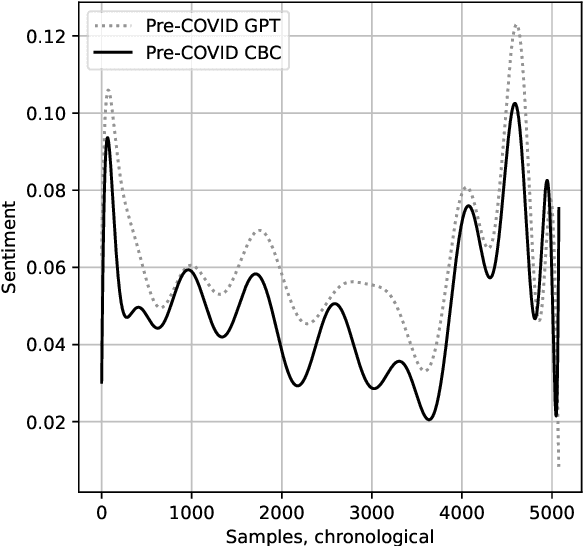
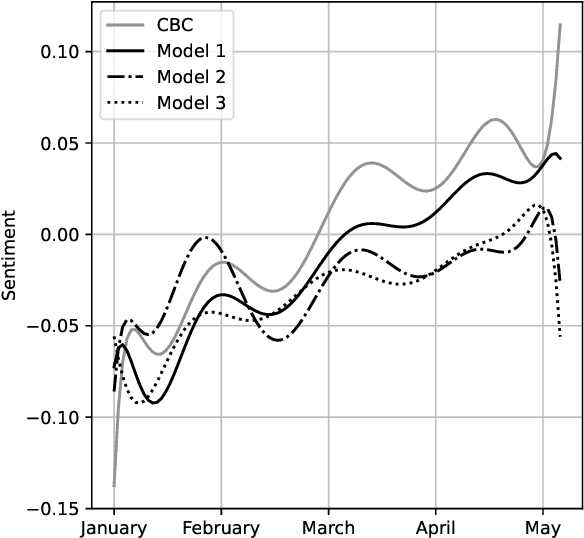
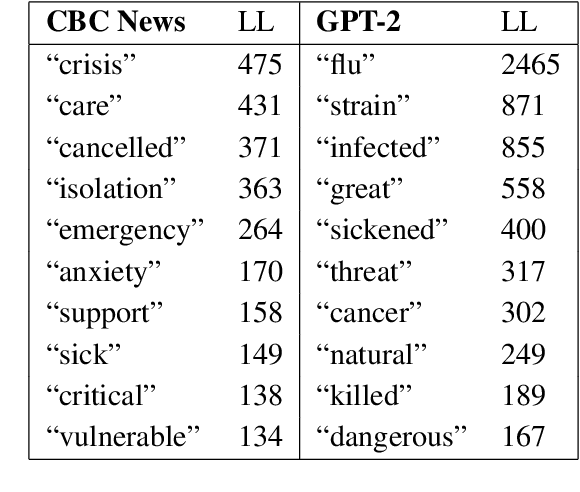
In this paper, we explore the use of large language models to assess human interpretations of real world events. To do so, we use a language model trained prior to 2020 to artificially generate news articles concerning COVID-19 given the headlines of actual articles written during the pandemic. We then compare stylistic qualities of our artificially generated corpus with a news corpus, in this case 5,082 articles produced by CBC News between January 23 and May 5, 2020. We find our artificially generated articles exhibits a considerably more negative attitude towards COVID and a significantly lower reliance on geopolitical framing. Our methods and results hold importance for researchers seeking to simulate large scale cultural processes via recent breakthroughs in text generation.