 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSocial Story Frames: Contextual Reasoning about Narrative Intent and Reception
Dec 17, 2025Reading stories evokes rich interpretive, affective, and evaluative responses, such as inferences about narrative intent or judgments about characters. Yet, computational models of reader response are limited, preventing nuanced analyses. To address this gap, we introduce SocialStoryFrames, a formalism for distilling plausible inferences about reader response, such as perceived author intent, explanatory and predictive reasoning, affective responses, and value judgments, using conversational context and a taxonomy grounded in narrative theory, linguistic pragmatics, and psychology. We develop two models, SSF-Generator and SSF-Classifier, validated through human surveys (N=382 participants) and expert annotations, respectively. We conduct pilot analyses to showcase the utility of the formalism for studying storytelling at scale. Specifically, applying our models to SSF-Corpus, a curated dataset of 6,140 social media stories from diverse contexts, we characterize the frequency and interdependence of storytelling intents, and we compare and contrast narrative practices (and their diversity) across communities. By linking fine-grained, context-sensitive modeling with a generic taxonomy of reader responses, SocialStoryFrames enable new research into storytelling in online communities.
BRIGHTER: BRIdging the Gap in Human-Annotated Textual Emotion Recognition Datasets for 28 Languages
Feb 17, 2025



People worldwide use language in subtle and complex ways to express emotions. While emotion recognition -- an umbrella term for several NLP tasks -- significantly impacts different applications in NLP and other fields, most work in the area is focused on high-resource languages. Therefore, this has led to major disparities in research and proposed solutions, especially for low-resource languages that suffer from the lack of high-quality datasets. In this paper, we present BRIGHTER-- a collection of multilabeled emotion-annotated datasets in 28 different languages. BRIGHTER covers predominantly low-resource languages from Africa, Asia, Eastern Europe, and Latin America, with instances from various domains annotated by fluent speakers. We describe the data collection and annotation processes and the challenges of building these datasets. Then, we report different experimental results for monolingual and crosslingual multi-label emotion identification, as well as intensity-level emotion recognition. We investigate results with and without using LLMs and analyse the large variability in performance across languages and text domains. We show that BRIGHTER datasets are a step towards bridging the gap in text-based emotion recognition and discuss their impact and utility.
The Detection and Understanding of Fictional Discourse
Jan 30, 2024
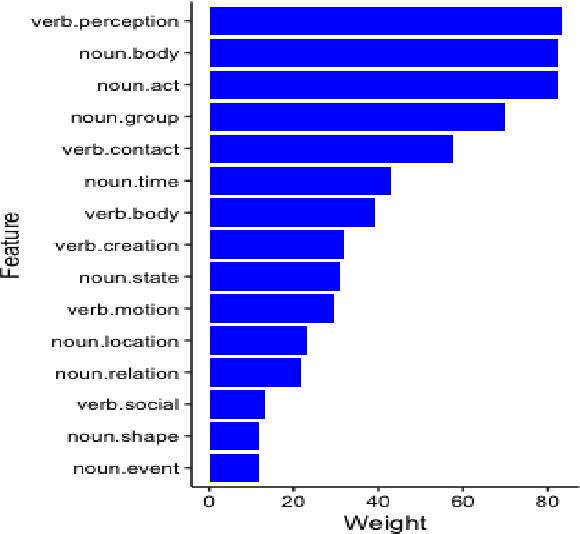


In this paper, we present a variety of classification experiments related to the task of fictional discourse detection. We utilize a diverse array of datasets, including contemporary professionally published fiction, historical fiction from the Hathi Trust, fanfiction, stories from Reddit, folk tales, GPT-generated stories, and anglophone world literature. Additionally, we introduce a new feature set of word "supersenses" that facilitate the goal of semantic generalization. The detection of fictional discourse can help enrich our knowledge of large cultural heritage archives and assist with the process of understanding the distinctive qualities of fictional storytelling more broadly.
Where Do People Tell Stories Online? Story Detection Across Online Communities
Nov 16, 2023



People share stories online for a myriad of purposes, whether as a means of self-disclosure, processing difficult personal experiences, providing needed information or entertainment, or persuading others to share their beliefs. Better understanding of online storytelling can illuminate the dynamics of social movements, sensemaking practices, persuasion strategies, and more. However, unlike other media such as books and visual content where the narrative nature of the content is often overtly signaled at the document level, studying storytelling in online communities is challenging due to the mixture of storytelling and non-storytelling behavior, which can be interspersed within documents and across diverse topics and settings. We introduce a codebook and create the Storytelling in Online Communities Corpus, an expert-annotated dataset of 502 English-language posts and comments with labeled story and event spans. Using our corpus, we train and evaluate an online story detection model, which we use to investigate the role storytelling of in different social contexts. We identify distinctive features of online storytelling, the prevalence of storytelling among different communities, and the conversational patterns of storytelling.
The COVID That Wasn't: Counterfactual Journalism Using GPT
Oct 13, 2022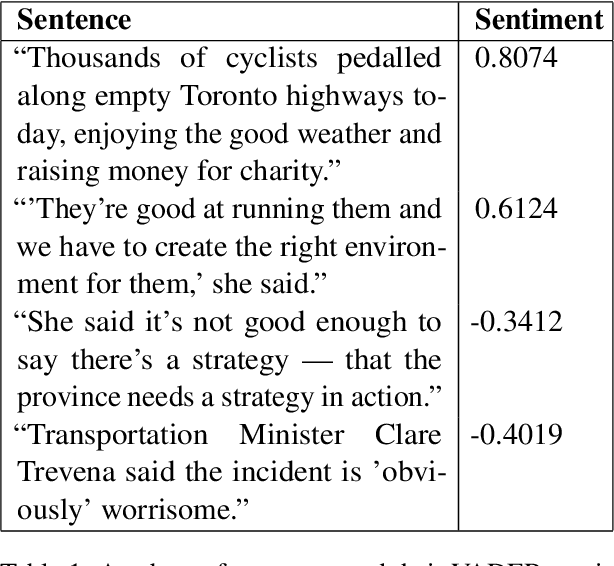
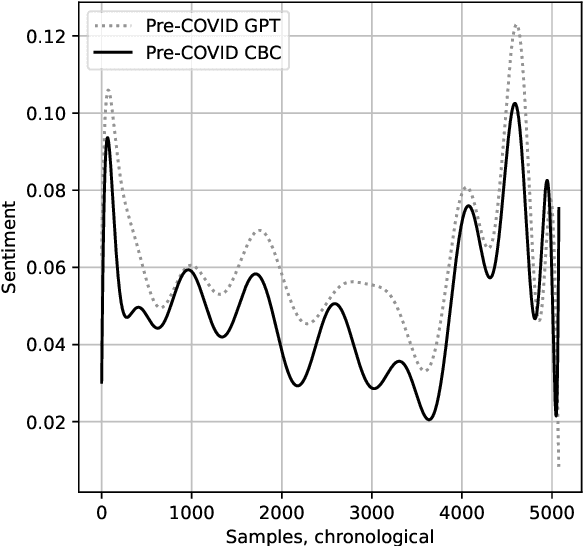
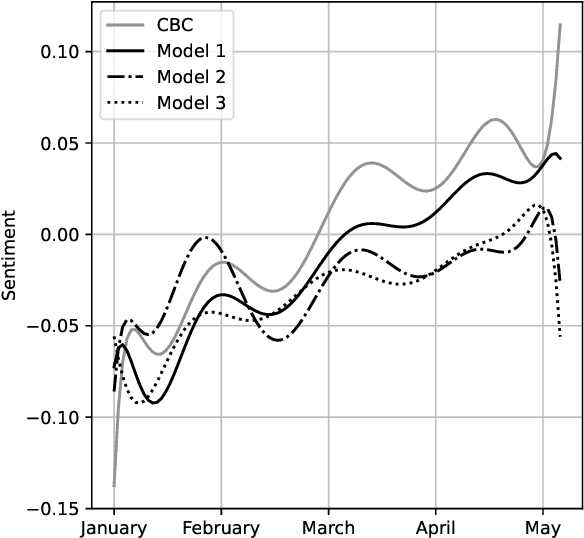
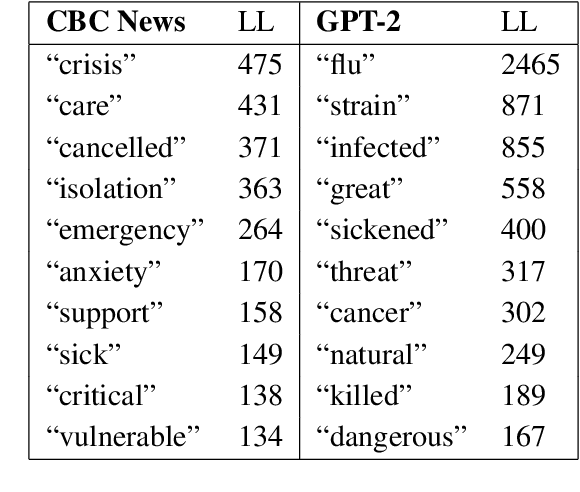
In this paper, we explore the use of large language models to assess human interpretations of real world events. To do so, we use a language model trained prior to 2020 to artificially generate news articles concerning COVID-19 given the headlines of actual articles written during the pandemic. We then compare stylistic qualities of our artificially generated corpus with a news corpus, in this case 5,082 articles produced by CBC News between January 23 and May 5, 2020. We find our artificially generated articles exhibits a considerably more negative attitude towards COVID and a significantly lower reliance on geopolitical framing. Our methods and results hold importance for researchers seeking to simulate large scale cultural processes via recent breakthroughs in text generation.