 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSemEval-2025 Task 11: Bridging the Gap in Text-Based Emotion Detection
Mar 10, 2025We present our shared task on text-based emotion detection, covering more than 30 languages from seven distinct language families. These languages are predominantly low-resource and spoken across various continents. The data instances are multi-labeled into six emotional classes, with additional datasets in 11 languages annotated for emotion intensity. Participants were asked to predict labels in three tracks: (a) emotion labels in monolingual settings, (b) emotion intensity scores, and (c) emotion labels in cross-lingual settings. The task attracted over 700 participants. We received final submissions from more than 200 teams and 93 system description papers. We report baseline results, as well as findings on the best-performing systems, the most common approaches, and the most effective methods across various tracks and languages. The datasets for this task are publicly available.
BRIGHTER: BRIdging the Gap in Human-Annotated Textual Emotion Recognition Datasets for 28 Languages
Feb 17, 2025



People worldwide use language in subtle and complex ways to express emotions. While emotion recognition -- an umbrella term for several NLP tasks -- significantly impacts different applications in NLP and other fields, most work in the area is focused on high-resource languages. Therefore, this has led to major disparities in research and proposed solutions, especially for low-resource languages that suffer from the lack of high-quality datasets. In this paper, we present BRIGHTER-- a collection of multilabeled emotion-annotated datasets in 28 different languages. BRIGHTER covers predominantly low-resource languages from Africa, Asia, Eastern Europe, and Latin America, with instances from various domains annotated by fluent speakers. We describe the data collection and annotation processes and the challenges of building these datasets. Then, we report different experimental results for monolingual and crosslingual multi-label emotion identification, as well as intensity-level emotion recognition. We investigate results with and without using LLMs and analyse the large variability in performance across languages and text domains. We show that BRIGHTER datasets are a step towards bridging the gap in text-based emotion recognition and discuss their impact and utility.
Emotion Granularity from Text: An Aggregate-Level Indicator of Mental Health
Mar 04, 2024We are united in how emotions are central to shaping our experiences; and yet, individuals differ greatly in how we each identify, categorize, and express emotions. In psychology, variation in the ability of individuals to differentiate between emotion concepts is called emotion granularity (determined through self-reports of one's emotions). High emotion granularity has been linked with better mental and physical health; whereas low emotion granularity has been linked with maladaptive emotion regulation strategies and poor health outcomes. In this work, we propose computational measures of emotion granularity derived from temporally-ordered speaker utterances in social media (in lieu of self-reports that suffer from various biases). We then investigate the effectiveness of such text-derived measures of emotion granularity in functioning as markers of various mental health conditions (MHCs). We establish baseline measures of emotion granularity derived from textual utterances, and show that, at an aggregate level, emotion granularities are significantly lower for people self-reporting as having an MHC than for the control population. This paves the way towards a better understanding of the MHCs, and specifically the role emotions play in our well-being.
Language and Mental Health: Measures of Emotion Dynamics from Text as Linguistic Biosocial Markers
Nov 04, 2023



Research in psychopathology has shown that, at an aggregate level, the patterns of emotional change over time -- emotion dynamics -- are indicators of one's mental health. One's patterns of emotion change have traditionally been determined through self-reports of emotions; however, there are known issues with accuracy, bias, and ease of data collection. Recent approaches to determining emotion dynamics from one's everyday utterances addresses many of these concerns, but it is not yet known whether these measures of utterance emotion dynamics (UED) correlate with mental health diagnoses. Here, for the first time, we study the relationship between tweet emotion dynamics and mental health disorders. We find that each of the UED metrics studied varied by the user's self-disclosed diagnosis. For example: average valence was significantly higher (i.e., more positive text) in the control group compared to users with ADHD, MDD, and PTSD. Valence variability was significantly lower in the control group compared to ADHD, depression, bipolar disorder, MDD, PTSD, and OCD but not PPD. Rise and recovery rates of valence also exhibited significant differences from the control. This work provides important early evidence for how linguistic cues pertaining to emotion dynamics can play a crucial role as biosocial markers for mental illnesses and aid in the understanding, diagnosis, and management of mental health disorders.
Utterance Emotion Dynamics in Children's Poems: Emotional Changes Across Age
Jun 08, 2023



Emerging psychopathology studies are showing that patterns of changes in emotional state -- emotion dynamics -- are associated with overall well-being and mental health. More recently, there has been some work in tracking emotion dynamics through one's utterances, allowing for data to be collected on a larger scale across time and people. However, several questions about how emotion dynamics change with age, especially in children, and when determined through children's writing, remain unanswered. In this work, we use both a lexicon and a machine learning based approach to quantify characteristics of emotion dynamics determined from poems written by children of various ages. We show that both approaches point to similar trends: consistent increasing intensities for some emotions (e.g., anger, fear, joy, sadness, arousal, and dominance) with age and a consistent decreasing valence with age. We also find increasing emotional variability, rise rates (i.e., emotional reactivity), and recovery rates (i.e., emotional regulation) with age. These results act as a useful baselines for further research in how patterns of emotions expressed by children change with age, and their association with mental health.
Generating High-Quality Emotion Arcs For Low-Resource Languages Using Emotion Lexicons
Jun 03, 2023
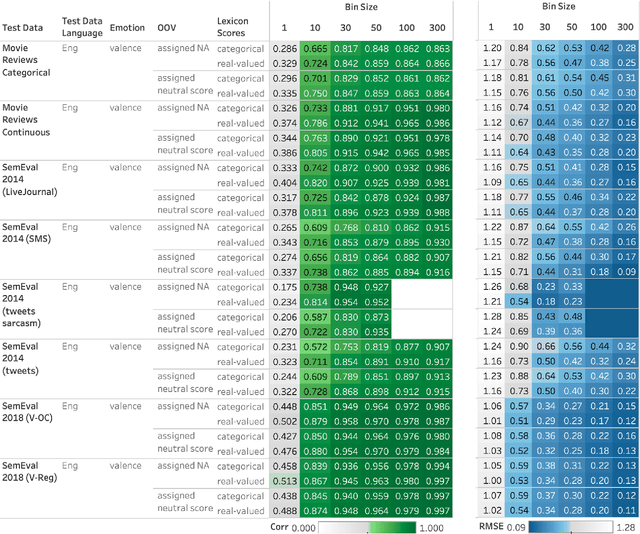
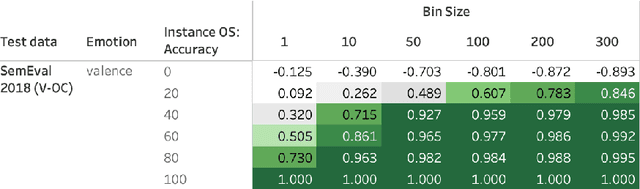
Automatically generated emotion arcs -- that capture how an individual or a population feels over time -- are widely used in industry and research. However, there is little work on evaluating the generated arcs in English (where the emotion resources are available) and no work on generating or evaluating emotion arcs for low-resource languages. Work on generating emotion arcs in low-resource languages such as those indigenous to Africa, the Americas, and Australia is stymied by the lack of emotion-labeled resources and large language models for those languages. Work on evaluating emotion arcs (for any language) is scarce because of the difficulty of establishing the true (gold) emotion arc. Our work, for the first time, systematically and quantitatively evaluates automatically generated emotion arcs. We also compare two common ways of generating emotion arcs: Machine-Learning (ML) models and Lexicon-Only (LexO) methods. By running experiments on 42 diverse datasets in 9 languages, we show that despite being markedly poor at instance level emotion classification, LexO methods are highly accurate at generating emotion arcs when aggregating information from hundreds of instances. (Predicted arcs have correlations ranging from 0.94 to 0.99 with the gold arcs for various emotions.) We also show that for languages with no emotion lexicons, automatic translations of English emotion lexicons can be used to generate high-quality emotion arcs -- correlations above 0.9 with the gold emotion arcs in all six indigenous African languages explored. This opens up avenues for work on emotions in numerous languages from around the world; crucial not only for commerce, public policy, and health research in service of speakers of those languages, but also to draw meaningful conclusions in emotion-pertinent research using information from around the world (thereby avoiding a western-centric bias in research).
Frustratingly Easy Sentiment Analysis of Text Streams: Generating High-Quality Emotion Arcs Using Emotion Lexicons
Oct 13, 2022
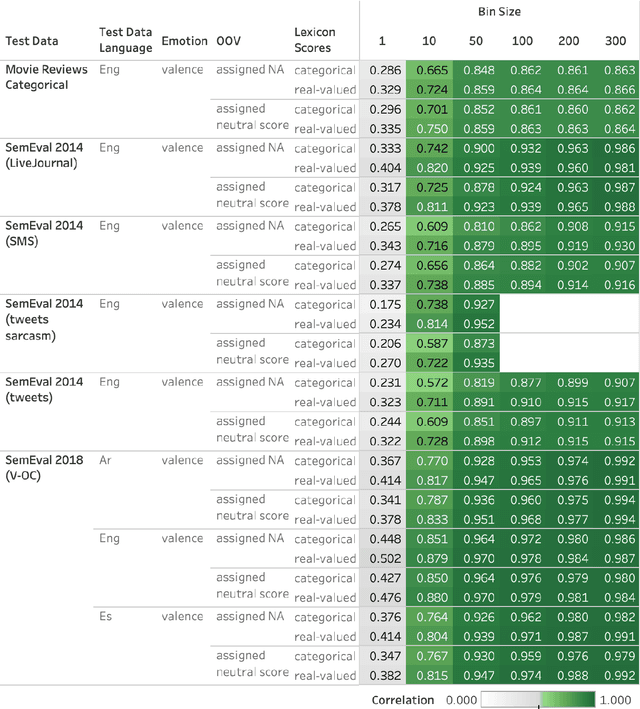

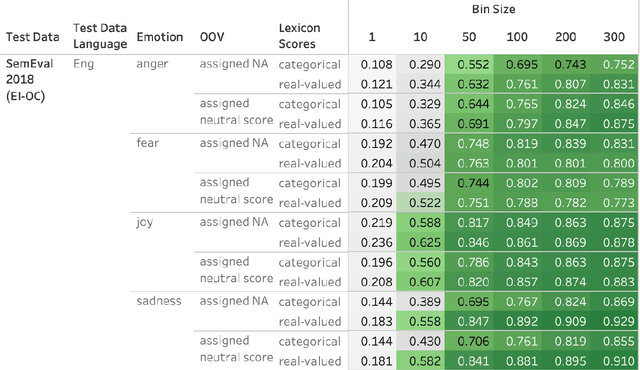
Automatically generated emotion arcs -- that capture how an individual or a population feels over time -- are widely used in industry and research. However, there is little work on evaluating the generated arcs. This is in part due to the difficulty of establishing the true (gold) emotion arc. Our work, for the first time, systematically and quantitatively evaluates automatically generated emotion arcs. We also compare two common ways of generating emotion arcs: Machine-Learning (ML) models and Lexicon-Only (LexO) methods. Using a number of diverse datasets, we systematically study the relationship between the quality of an emotion lexicon and the quality of the emotion arc that can be generated with it. We also study the relationship between the quality of an instance-level emotion detection system (say from an ML model) and the quality of emotion arcs that can be generated with it. We show that despite being markedly poor at instance level, LexO methods are highly accurate at generating emotion arcs by aggregating information from hundreds of instances. This has wide-spread implications for commercial development, as well as research in psychology, public health, digital humanities, etc. that values simple interpretable methods and disprefers the need for domain-specific training data, programming expertise, and high-carbon-footprint models.