 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrustratingly Easy Sentiment Analysis of Text Streams: Generating High-Quality Emotion Arcs Using Emotion Lexicons
Paper and Code
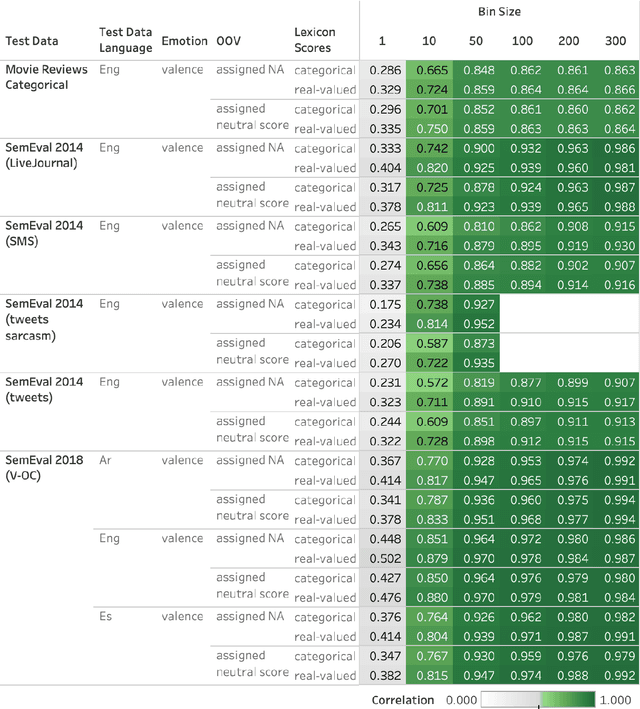

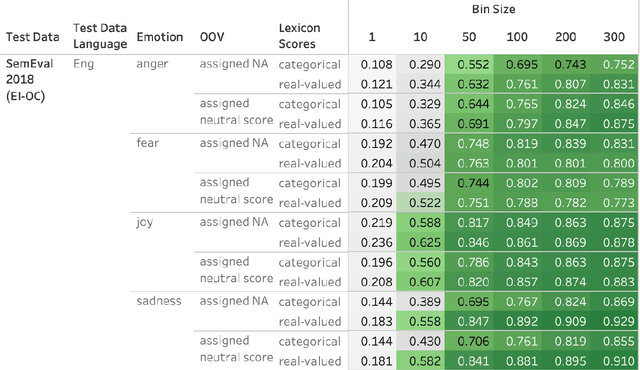
Automatically generated emotion arcs -- that capture how an individual or a population feels over time -- are widely used in industry and research. However, there is little work on evaluating the generated arcs. This is in part due to the difficulty of establishing the true (gold) emotion arc. Our work, for the first time, systematically and quantitatively evaluates automatically generated emotion arcs. We also compare two common ways of generating emotion arcs: Machine-Learning (ML) models and Lexicon-Only (LexO) methods. Using a number of diverse datasets, we systematically study the relationship between the quality of an emotion lexicon and the quality of the emotion arc that can be generated with it. We also study the relationship between the quality of an instance-level emotion detection system (say from an ML model) and the quality of emotion arcs that can be generated with it. We show that despite being markedly poor at instance level, LexO methods are highly accurate at generating emotion arcs by aggregating information from hundreds of instances. This has wide-spread implications for commercial development, as well as research in psychology, public health, digital humanities, etc. that values simple interpretable methods and disprefers the need for domain-specific training data, programming expertise, and high-carbon-footprint models.