 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSemEval-2026 Task 3: Dimensional Aspect-Based Sentiment Analysis (DimABSA)
Apr 08, 2026We present the SemEval-2026 shared task on Dimensional Aspect-Based Sentiment Analysis (DimABSA), which improves traditional ABSA by modeling sentiment along valence-arousal (VA) dimensions rather than using categorical polarity labels. To extend ABSA beyond consumer reviews to public-issue discourse (e.g., political, energy, and climate issues), we introduce an additional task, Dimensional Stance Analysis (DimStance), which treats stance targets as aspects and reformulates stance detection as regression in the VA space. The task consists of two tracks: Track A (DimABSA) and Track B (DimStance). Track A includes three subtasks: (1) dimensional aspect sentiment regression, (2) dimensional aspect sentiment triplet extraction, and (3) dimensional aspect sentiment quadruplet extraction, while Track B includes only the regression subtask for stance targets. We also introduce a continuous F1 (cF1) metric to jointly evaluate structured extraction and VA regression. The task attracted more than 400 participants, resulting in 112 final submissions and 42 system description papers. We report baseline results, discuss top-performing systems, and analyze key design choices to provide insights into dimensional sentiment analysis at the aspect and stance-target levels. All resources are available on our GitHub repository.
I Came, I Saw, I Explained: Benchmarking Multimodal LLMs on Figurative Meaning in Memes
Mar 24, 2026Internet memes represent a popular form of multimodal online communication and often use figurative elements to convey layered meaning through the combination of text and images. However, it remains largely unclear how multimodal large language models (MLLMs) combine and interpret visual and textual information to identify figurative meaning in memes. To address this gap, we evaluate eight state-of-the-art generative MLLMs across three datasets on their ability to detect and explain six types of figurative meaning. In addition, we conduct a human evaluation of the explanations generated by these MLLMs, assessing whether the provided reasoning supports the predicted label and whether it remains faithful to the original meme content. Our findings indicate that all models exhibit a strong bias to associate a meme with figurative meaning, even when no such meaning is present. Qualitative analysis further shows that correct predictions are not always accompanied by faithful explanations.
ClaimFlow: Tracing the Evolution of Scientific Claims in NLP
Mar 17, 2026Scientific papers do more than report results $-$ they advance $\textit{claims}$ that later work supports, extends, or sometimes refutes. Yet existing methods for citation and claim analysis capture only fragments of this dialogue. In this work, we make these interactions explicit at the level of individual scientific claims. We introduce $\texttt{ClaimFlow}$, a claim-centric view of the NLP literature, built from $304$ ACL Anthology papers (1979$-$2025) that are manually annotated with $1{,}084$ claims and $832$ cross-paper claim relations, indicating whether a citing paper $\textit{supports}$, $\textit{extends}$, $\textit{qualifies}$, $\textit{refutes}$, or references a claim as $\textit{background}$. Using $\texttt{ClaimFlow}$, we define a new task $-$ $\textit{Claim Relation Classification}$ $-$ which requires models to infer the scientific stance toward a cited claim from the text and citation context. Evaluating strong neural models and large language models on this task, we report baseline performance of $0.78$ macro-F1, highlighting that claim-relation classification is feasible but challenging. We further apply our model to $\sim$$13k$ NLP papers to analyze how claims evolve across decades of NLP research. Our analysis reveals that $63.5$% claims are never reused; only $11.1$% are ever challenged; meanwhile, widely propagated claims are more often $\textit{reshaped}$ through qualification and extension than directly confirmed or refuted. Overall, $\texttt{ClaimFlow}$ offers a lens for examining how ideas shift and mature within NLP, and a foundation for assessing whether models can interpret scientific argumentation.
When are We Worried? Temporal Trends of Anxiety and What They Reveal about Us
Feb 11, 2026In this short paper, we make use of a recently created lexicon of word-anxiety associations to analyze large amounts of US and Canadian social media data (tweets) to explore *when* we are anxious and what insights that reveals about us. We show that our levels of anxiety on social media exhibit systematic patterns of rise and fall during the day -- highest at 8am (in-line with when we have high cortisol levels in the body) and lowest around noon. Anxiety is lowest on weekends and highest mid-week. We also examine anxiety in past, present, and future tense sentences to show that anxiety is highest in past tense and lowest in future tense. Finally, we examine the use of anxiety and calmness words in posts that contain pronouns to show: more anxiety in 3rd person pronouns (he, they) posts than 1st and 2nd person pronouns and higher anxiety in posts with subject pronouns (I, he, she, they) than object pronouns (me, him, her, them). Overall, these trends provide valuable insights on not just when we are anxious, but also how different types of focus (future, past, self, outward, etc.) are related to anxiety.
Annotating Dimensions of Social Perception in Text: The First Sentence-Level Dataset of Warmth and Competence
Jan 09, 2026Warmth (W) (often further broken down into Trust (T) and Sociability (S)) and Competence (C) are central dimensions along which people evaluate individuals and social groups (Fiske, 2018). While these constructs are well established in social psychology, they are only starting to get attention in NLP research through word-level lexicons, which do not completely capture their contextual expression in larger text units and discourse. In this work, we introduce Warmth and Competence Sentences (W&C-Sent), the first sentence-level dataset annotated for warmth and competence. The dataset includes over 1,600 English sentence--target pairs annotated along three dimensions: trust and sociability (components of warmth), and competence. The sentences in W&C-Sent are from social media and often express attitudes and opinions about specific individuals or social groups (the targets of our annotations). We describe the data collection, annotation, and quality-control procedures in detail, and evaluate a range of large language models (LLMs) on their ability to identify trust, sociability, and competence in text. W&C-Sent provides a new resource for analyzing warmth and competence in language and supports future research at the intersection of NLP and computational social science.
Affect, Body, Cognition, Demographics, and Emotion: The ABCDE of Text Features for Computational Affective Science
Dec 19, 2025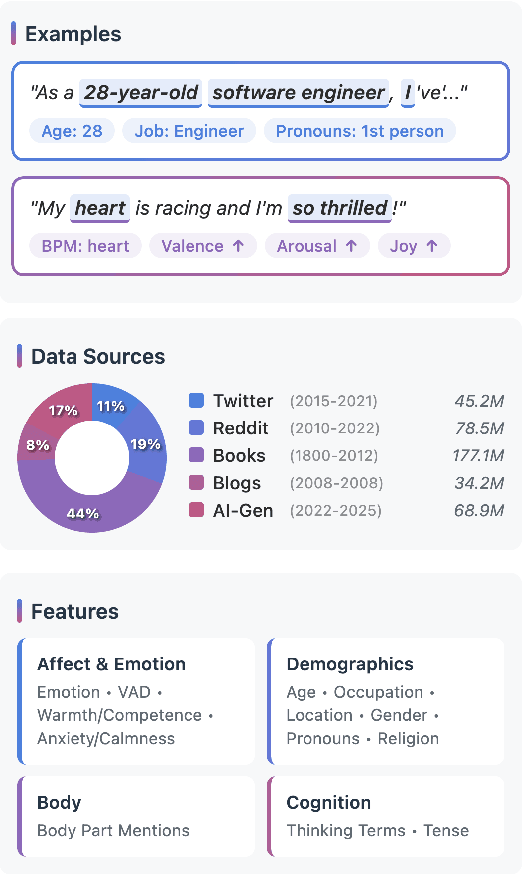
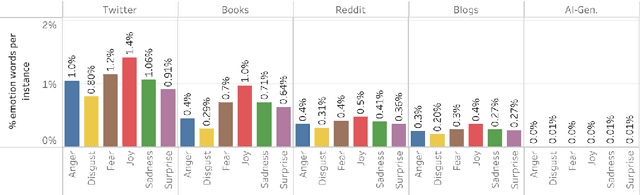
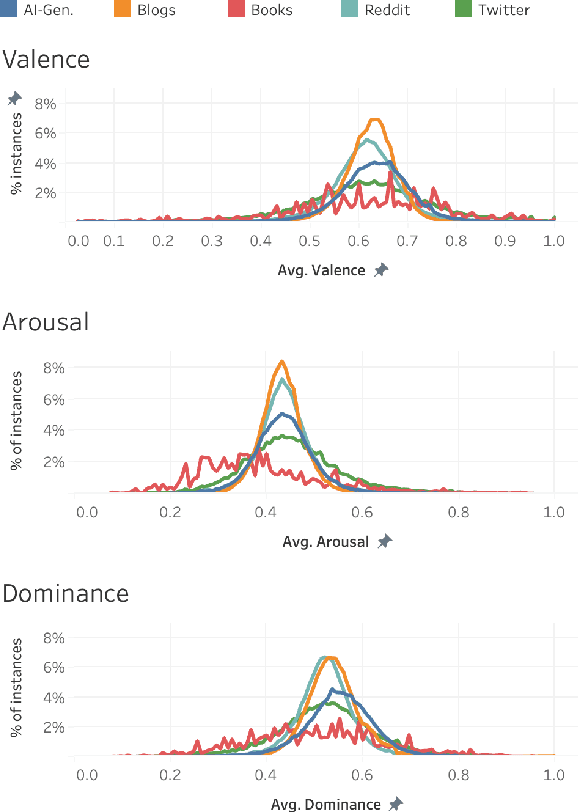

Work in Computational Affective Science and Computational Social Science explores a wide variety of research questions about people, emotions, behavior, and health. Such work often relies on language data that is first labeled with relevant information, such as the use of emotion words or the age of the speaker. Although many resources and algorithms exist to enable this type of labeling, discovering, accessing, and using them remains a substantial impediment, particularly for practitioners outside of computer science. Here, we present the ABCDE dataset (Affect, Body, Cognition, Demographics, and Emotion), a large-scale collection of over 400 million text utterances drawn from social media, blogs, books, and AI-generated sources. The dataset is annotated with a wide range of features relevant to computational affective and social science. ABCDE facilitates interdisciplinary research across numerous fields, including affective science, cognitive science, the digital humanities, sociology, political science, and computational linguistics.
Words of Warmth: Trust and Sociability Norms for over 26k English Words
Jun 04, 2025Social psychologists have shown that Warmth (W) and Competence (C) are the primary dimensions along which we assess other people and groups. These dimensions impact various aspects of our lives from social competence and emotion regulation to success in the work place and how we view the world. More recent work has started to explore how these dimensions develop, why they have developed, and what they constitute. Of particular note, is the finding that warmth has two distinct components: Trust (T) and Sociability (S). In this work, we introduce Words of Warmth, the first large-scale repository of manually derived word--warmth (as well as word--trust and word--sociability) associations for over 26k English words. We show that the associations are highly reliable. We use the lexicons to study the rate at which children acquire WCTS words with age. Finally, we show that the lexicon enables a wide variety of bias and stereotype research through case studies on various target entities. Words of Warmth is freely available at: http://saifmohammad.com/warmth.html
* In Proceedings of ACL 2025 Main
The Language of Interoception: Examining Embodiment and Emotion Through a Corpus of Body Part Mentions
May 22, 2025This paper is the first investigation of the connection between emotion, embodiment, and everyday language in a large sample of natural language data. We created corpora of body part mentions (BPMs) in online English text (blog posts and tweets). This includes a subset featuring human annotations for the emotions of the person whose body part is mentioned in the text. We show that BPMs are common in personal narratives and tweets (~5% to 10% of posts include BPMs) and that their usage patterns vary markedly by time and %geographic location. Using word-emotion association lexicons and our annotated data, we show that text containing BPMs tends to be more emotionally charged, even when the BPM is not explicitly used to describe a physical reaction to the emotion in the text. Finally, we discover a strong and statistically significant correlation between body-related language and a variety of poorer health outcomes. In sum, we argue that investigating the role of body-part related words in language can open up valuable avenues of future research at the intersection of NLP, the affective sciences, and the study of human wellbeing.
What Media Frames Reveal About Stance: A Dataset and Study about Memes in Climate Change Discourse
May 22, 2025Media framing refers to the emphasis on specific aspects of perceived reality to shape how an issue is defined and understood. Its primary purpose is to shape public perceptions often in alignment with the authors' opinions and stances. However, the interaction between stance and media frame remains largely unexplored. In this work, we apply an interdisciplinary approach to conceptualize and computationally explore this interaction with internet memes on climate change. We curate CLIMATEMEMES, the first dataset of climate-change memes annotated with both stance and media frames, inspired by research in communication science. CLIMATEMEMES includes 1,184 memes sourced from 47 subreddits, enabling analysis of frame prominence over time and communities, and sheds light on the framing preferences of different stance holders. We propose two meme understanding tasks: stance detection and media frame detection. We evaluate LLaVA-NeXT and Molmo in various setups, and report the corresponding results on their LLM backbone. Human captions consistently enhance performance. Synthetic captions and human-corrected OCR also help occasionally. Our findings highlight that VLMs perform well on stance, but struggle on frames, where LLMs outperform VLMs. Finally, we analyze VLMs' limitations in handling nuanced frames and stance expressions on climate change internet memes.
NRC VAD Lexicon v2: Norms for Valence, Arousal, and Dominance for over 55k English Terms
Mar 30, 2025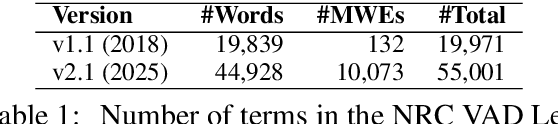



Factor analysis studies have shown that the primary dimensions of word meaning are Valence (V), Arousal (A), and Dominance (D) (also referred to in social cognition research as Competence (C)). These dimensions impact various aspects of our lives from social competence and emotion regulation to success in the work place and how we view the world. We present here the NRC VAD Lexicon v2, which has human ratings of valence, arousal, and dominance for more than 55,000 English words and phrases. Notably, it adds entries for $\sim$25k additional words to v1.0. It also now includes for the first time entries for common multi-word phrases (~10k). We show that the associations are highly reliable. The lexicon enables a wide variety of research in psychology, NLP, public health, digital humanities, and social sciences. The NRC VAD Lexicon v2 is made freely available for research through our project webpage.