 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBuilding Better: Avoiding Pitfalls in Developing Language Resources when Data is Scarce
Paper and Code
Oct 17, 2024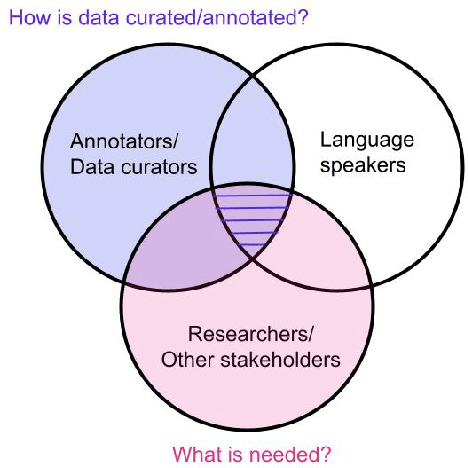

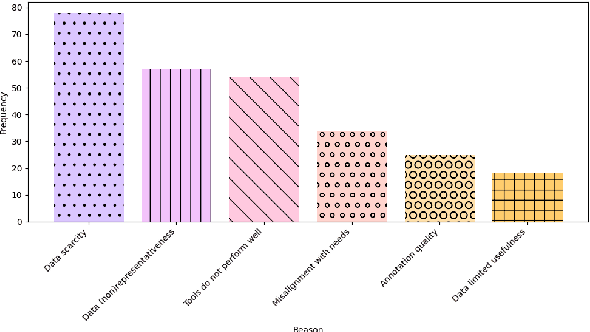
Language is a symbolic capital that affects people's lives in many ways (Bourdieu, 1977, 1991). It is a powerful tool that accounts for identities, cultures, traditions, and societies in general. Hence, data in a given language should be viewed as more than a collection of tokens. Good data collection and labeling practices are key to building more human-centered and socially aware technologies. While there has been a rising interest in mid- to low-resource languages within the NLP community, work in this space has to overcome unique challenges such as data scarcity and access to suitable annotators. In this paper, we collect feedback from those directly involved in and impacted by NLP artefacts for mid- to low-resource languages. We conduct a quantitative and qualitative analysis of the responses and highlight the main issues related to (1) data quality such as linguistic and cultural data suitability; and (2) the ethics of common annotation practices such as the misuse of online community services. Based on these findings, we make several recommendations for the creation of high-quality language artefacts that reflect the cultural milieu of its speakers, while simultaneously respecting the dignity and labor of data workers.