 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSemEval-2025 Task 11: Bridging the Gap in Text-Based Emotion Detection
Mar 10, 2025We present our shared task on text-based emotion detection, covering more than 30 languages from seven distinct language families. These languages are predominantly low-resource and spoken across various continents. The data instances are multi-labeled into six emotional classes, with additional datasets in 11 languages annotated for emotion intensity. Participants were asked to predict labels in three tracks: (a) emotion labels in monolingual settings, (b) emotion intensity scores, and (c) emotion labels in cross-lingual settings. The task attracted over 700 participants. We received final submissions from more than 200 teams and 93 system description papers. We report baseline results, as well as findings on the best-performing systems, the most common approaches, and the most effective methods across various tracks and languages. The datasets for this task are publicly available.
Visualising Policy-Reward Interplay to Inform Zeroth-Order Preference Optimisation of Large Language Models
Mar 05, 2025



Fine-tuning LLMs with first-order methods like back-propagation is computationally intensive. Zeroth-Order (ZO) optimisation, using function evaluations instead of gradients, reduces memory usage but suffers from slow convergence in high-dimensional models. As a result, ZO research in LLMs has mostly focused on classification, overlooking more complex generative tasks. In this paper, we introduce ZOPrO, a novel ZO algorithm designed for \textit{Preference Optimisation} in LLMs. We begin by analysing the interplay between policy and reward models during traditional (first-order) Preference Optimisation, uncovering patterns in their relative updates. Guided by these insights, we adapt Simultaneous Perturbation Stochastic Approximation (SPSA) with a targeted sampling strategy to accelerate convergence. Through experiments on summarisation, machine translation, and conversational assistants, we demonstrate that our method consistently enhances reward signals while achieving convergence times comparable to first-order methods. While it falls short of some state-of-the-art methods, our work is the first to apply Zeroth-Order methods to Preference Optimisation in LLMs, going beyond classification tasks and paving the way for a largely unexplored research direction. Code and visualisations are available at https://github.com/alessioGalatolo/VisZOPrO
BRIGHTER: BRIdging the Gap in Human-Annotated Textual Emotion Recognition Datasets for 28 Languages
Feb 17, 2025



People worldwide use language in subtle and complex ways to express emotions. While emotion recognition -- an umbrella term for several NLP tasks -- significantly impacts different applications in NLP and other fields, most work in the area is focused on high-resource languages. Therefore, this has led to major disparities in research and proposed solutions, especially for low-resource languages that suffer from the lack of high-quality datasets. In this paper, we present BRIGHTER-- a collection of multilabeled emotion-annotated datasets in 28 different languages. BRIGHTER covers predominantly low-resource languages from Africa, Asia, Eastern Europe, and Latin America, with instances from various domains annotated by fluent speakers. We describe the data collection and annotation processes and the challenges of building these datasets. Then, we report different experimental results for monolingual and crosslingual multi-label emotion identification, as well as intensity-level emotion recognition. We investigate results with and without using LLMs and analyse the large variability in performance across languages and text domains. We show that BRIGHTER datasets are a step towards bridging the gap in text-based emotion recognition and discuss their impact and utility.
AfriHate: A Multilingual Collection of Hate Speech and Abusive Language Datasets for African Languages
Jan 15, 2025



Hate speech and abusive language are global phenomena that need socio-cultural background knowledge to be understood, identified, and moderated. However, in many regions of the Global South, there have been several documented occurrences of (1) absence of moderation and (2) censorship due to the reliance on keyword spotting out of context. Further, high-profile individuals have frequently been at the center of the moderation process, while large and targeted hate speech campaigns against minorities have been overlooked. These limitations are mainly due to the lack of high-quality data in the local languages and the failure to include local communities in the collection, annotation, and moderation processes. To address this issue, we present AfriHate: a multilingual collection of hate speech and abusive language datasets in 15 African languages. Each instance in AfriHate is annotated by native speakers familiar with the local culture. We report the challenges related to the construction of the datasets and present various classification baseline results with and without using LLMs. The datasets, individual annotations, and hate speech and offensive language lexicons are available on https://github.com/AfriHate/AfriHate
Building Better: Avoiding Pitfalls in Developing Language Resources when Data is Scarce
Oct 17, 2024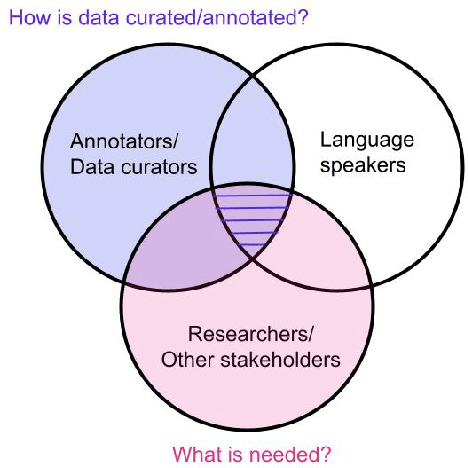

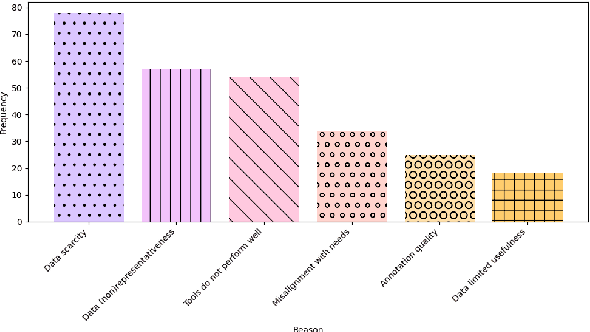
Language is a symbolic capital that affects people's lives in many ways (Bourdieu, 1977, 1991). It is a powerful tool that accounts for identities, cultures, traditions, and societies in general. Hence, data in a given language should be viewed as more than a collection of tokens. Good data collection and labeling practices are key to building more human-centered and socially aware technologies. While there has been a rising interest in mid- to low-resource languages within the NLP community, work in this space has to overcome unique challenges such as data scarcity and access to suitable annotators. In this paper, we collect feedback from those directly involved in and impacted by NLP artefacts for mid- to low-resource languages. We conduct a quantitative and qualitative analysis of the responses and highlight the main issues related to (1) data quality such as linguistic and cultural data suitability; and (2) the ethics of common annotation practices such as the misuse of online community services. Based on these findings, we make several recommendations for the creation of high-quality language artefacts that reflect the cultural milieu of its speakers, while simultaneously respecting the dignity and labor of data workers.
Defining Boundaries: The Impact of Domain Specification on Cross-Language and Cross-Domain Transfer in Machine Translation
Aug 21, 2024Recent advancements in neural machine translation (NMT) have revolutionized the field, yet the dependency on extensive parallel corpora limits progress for low-resource languages. Cross-lingual transfer learning offers a promising solution by utilizing data from high-resource languages but often struggles with in-domain NMT. In this paper, we investigate three pivotal aspects: enhancing the domain-specific quality of NMT by fine-tuning domain-relevant data from different language pairs, identifying which domains are transferable in zero-shot scenarios, and assessing the impact of language-specific versus domain-specific factors on adaptation effectiveness. Using English as the source language and Spanish for fine-tuning, we evaluate multiple target languages including Portuguese, Italian, French, Czech, Polish, and Greek. Our findings reveal significant improvements in domain-specific translation quality, especially in specialized fields such as medical, legal, and IT, underscoring the importance of well-defined domain data and transparency of the experiment setup in in-domain transfer learning.
DIEKAE: Difference Injection for Efficient Knowledge Augmentation and Editing of Large Language Models
Jun 15, 2024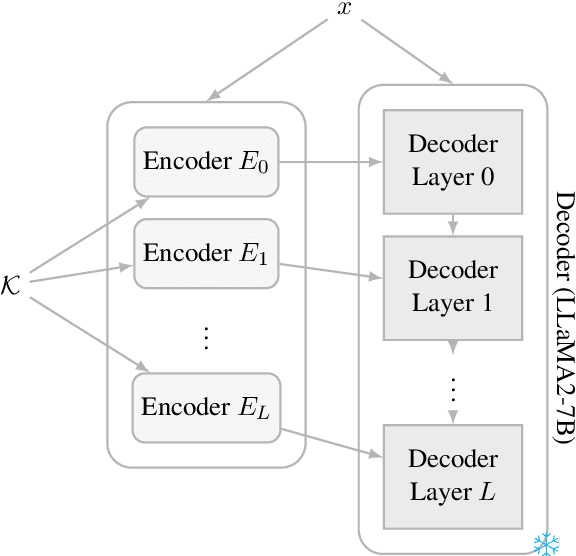



Pretrained Language Models (PLMs) store extensive knowledge within their weights, enabling them to recall vast amount of information. However, relying on this parametric knowledge brings some limitations such as outdated information or gaps in the training data. This work addresses these problems by distinguish between two separate solutions: knowledge editing and knowledge augmentation. We introduce Difference Injection for Efficient Knowledge Augmentation and Editing (DIEK\AE), a new method that decouples knowledge processing from the PLM (LLaMA2-7B, in particular) by adopting a series of encoders. These encoders handle external knowledge and inject it into the PLM layers, significantly reducing computational costs and improving performance of the PLM. We propose a novel training technique for these encoders that does not require back-propagation through the PLM, thus greatly reducing the memory and time required to train them. Our findings demonstrate how our method is faster and more efficient compared to multiple baselines in knowledge augmentation and editing during both training and inference. We have released our code and data at https://github.com/alessioGalatolo/DIEKAE.
SemEval Task 1: Semantic Textual Relatedness for African and Asian Languages
Apr 04, 2024

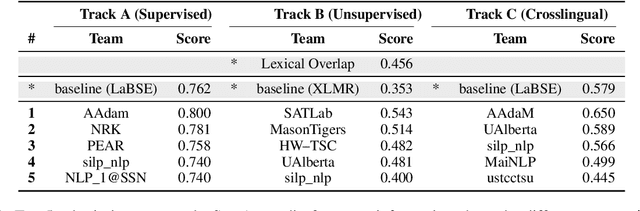
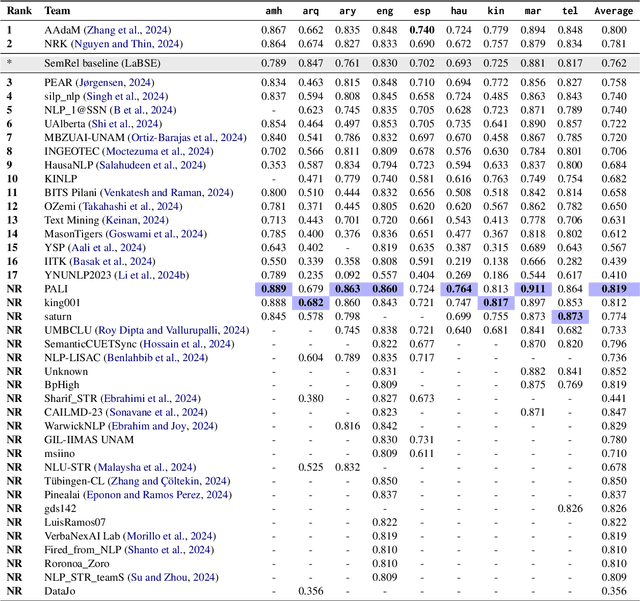
We present the first shared task on Semantic Textual Relatedness (STR). While earlier shared tasks primarily focused on semantic similarity, we instead investigate the broader phenomenon of semantic relatedness across 14 languages: Afrikaans, Algerian Arabic, Amharic, English, Hausa, Hindi, Indonesian, Kinyarwanda, Marathi, Moroccan Arabic, Modern Standard Arabic, Punjabi, Spanish, and Telugu. These languages originate from five distinct language families and are predominantly spoken in Africa and Asia -- regions characterised by the relatively limited availability of NLP resources. Each instance in the datasets is a sentence pair associated with a score that represents the degree of semantic textual relatedness between the two sentences. Participating systems were asked to rank sentence pairs by their closeness in meaning (i.e., their degree of semantic relatedness) in the 14 languages in three main tracks: (a) supervised, (b) unsupervised, and (c) crosslingual. The task attracted 163 participants. We received 70 submissions in total (across all tasks) from 51 different teams, and 38 system description papers. We report on the best-performing systems as well as the most common and the most effective approaches for the three different tracks.
SemRel2024: A Collection of Semantic Textual Relatedness Datasets for 14 Languages
Feb 15, 2024



Exploring and quantifying semantic relatedness is central to representing language. It holds significant implications across various NLP tasks, including offering insights into the capabilities and performance of Large Language Models (LLMs). While earlier NLP research primarily focused on semantic similarity, often within the English language context, we instead investigate the broader phenomenon of semantic relatedness. In this paper, we present SemRel, a new semantic relatedness dataset collection annotated by native speakers across 14 languages:Afrikaans, Algerian Arabic, Amharic, English, Hausa, Hindi, Indonesian, Kinyarwanda, Marathi, Moroccan Arabic, Modern Standard Arabic, Punjabi, Spanish, and Telugu. These languages originate from five distinct language families and are predominantly spoken in Africa and Asia -- regions characterised by a relatively limited availability of NLP resources. Each instance in the SemRel datasets is a sentence pair associated with a score that represents the degree of semantic textual relatedness between the two sentences. The scores are obtained using a comparative annotation framework. We describe the data collection and annotation processes, related challenges when building the datasets, and their impact and utility in NLP. We further report experiments for each language and across the different languages.
SemEval-2023 Task 12: Sentiment Analysis for African Languages
May 01, 2023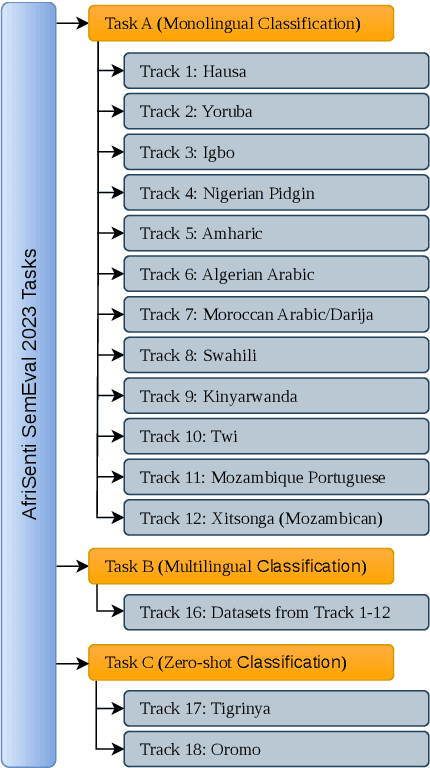
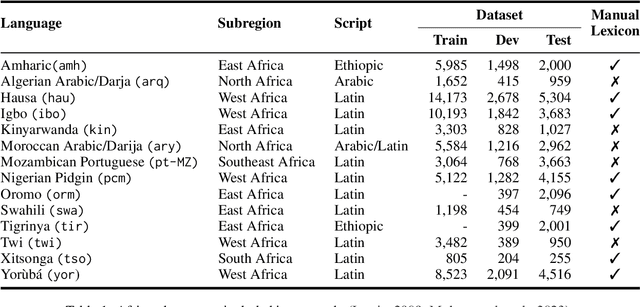
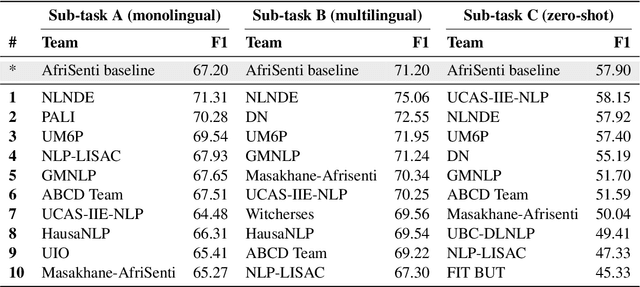
We present the first Africentric SemEval Shared task, Sentiment Analysis for African Languages (AfriSenti-SemEval) - The dataset is available at https://github.com/afrisenti-semeval/afrisent-semeval-2023. AfriSenti-SemEval is a sentiment classification challenge in 14 African languages: Amharic, Algerian Arabic, Hausa, Igbo, Kinyarwanda, Moroccan Arabic, Mozambican Portuguese, Nigerian Pidgin, Oromo, Swahili, Tigrinya, Twi, Xitsonga, and Yor\`ub\'a (Muhammad et al., 2023), using data labeled with 3 sentiment classes. We present three subtasks: (1) Task A: monolingual classification, which received 44 submissions; (2) Task B: multilingual classification, which received 32 submissions; and (3) Task C: zero-shot classification, which received 34 submissions. The best performance for tasks A and B was achieved by NLNDE team with 71.31 and 75.06 weighted F1, respectively. UCAS-IIE-NLP achieved the best average score for task C with 58.15 weighted F1. We describe the various approaches adopted by the top 10 systems and their approaches.