 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSemEval-2025 Task 11: Bridging the Gap in Text-Based Emotion Detection
Mar 10, 2025We present our shared task on text-based emotion detection, covering more than 30 languages from seven distinct language families. These languages are predominantly low-resource and spoken across various continents. The data instances are multi-labeled into six emotional classes, with additional datasets in 11 languages annotated for emotion intensity. Participants were asked to predict labels in three tracks: (a) emotion labels in monolingual settings, (b) emotion intensity scores, and (c) emotion labels in cross-lingual settings. The task attracted over 700 participants. We received final submissions from more than 200 teams and 93 system description papers. We report baseline results, as well as findings on the best-performing systems, the most common approaches, and the most effective methods across various tracks and languages. The datasets for this task are publicly available.
BRIGHTER: BRIdging the Gap in Human-Annotated Textual Emotion Recognition Datasets for 28 Languages
Feb 17, 2025



People worldwide use language in subtle and complex ways to express emotions. While emotion recognition -- an umbrella term for several NLP tasks -- significantly impacts different applications in NLP and other fields, most work in the area is focused on high-resource languages. Therefore, this has led to major disparities in research and proposed solutions, especially for low-resource languages that suffer from the lack of high-quality datasets. In this paper, we present BRIGHTER-- a collection of multilabeled emotion-annotated datasets in 28 different languages. BRIGHTER covers predominantly low-resource languages from Africa, Asia, Eastern Europe, and Latin America, with instances from various domains annotated by fluent speakers. We describe the data collection and annotation processes and the challenges of building these datasets. Then, we report different experimental results for monolingual and crosslingual multi-label emotion identification, as well as intensity-level emotion recognition. We investigate results with and without using LLMs and analyse the large variability in performance across languages and text domains. We show that BRIGHTER datasets are a step towards bridging the gap in text-based emotion recognition and discuss their impact and utility.
Exoplanet Transit Candidate Identification in TESS Full-Frame Images via a Transformer-Based Algorithm
Feb 11, 2025The Transiting Exoplanet Survey Satellite (TESS) is surveying a large fraction of the sky, generating a vast database of photometric time series data that requires thorough analysis to identify exoplanetary transit signals. Automated learning approaches have been successfully applied to identify transit signals. However, most existing methods focus on the classification and validation of candidates, while few efforts have explored new techniques for the search of candidates. To search for new exoplanet transit candidates, we propose an approach to identify exoplanet transit signals without the need for phase folding or assuming periodicity in the transit signals, such as those observed in multi-transit light curves. To achieve this, we implement a new neural network inspired by Transformers to directly process Full Frame Image (FFI) light curves to detect exoplanet transits. Transformers, originally developed for natural language processing, have recently demonstrated significant success in capturing long-range dependencies compared to previous approaches focused on sequential data. This ability allows us to employ multi-head self-attention to identify exoplanet transit signals directly from the complete light curves, combined with background and centroid time series, without requiring prior transit parameters. The network is trained to learn characteristics of the transit signal, like the dip shape, which helps distinguish planetary transits from other variability sources. Our model successfully identified 214 new planetary system candidates, including 122 multi-transit light curves, 88 single-transit and 4 multi-planet systems from TESS sectors 1-26 with a radius > 0.27 $R_{\mathrm{Jupiter}}$, demonstrating its ability to detect transits regardless of their periodicity.
EAGLE: Enhanced Visual Grounding Minimizes Hallucinations in Instructional Multimodal Models
Jan 06, 2025Large language models and vision transformers have demonstrated impressive zero-shot capabilities, enabling significant transferability in downstream tasks. The fusion of these models has resulted in multi-modal architectures with enhanced instructional capabilities. Despite incorporating vast image and language pre-training, these multi-modal architectures often generate responses that deviate from the ground truth in the image data. These failure cases are known as hallucinations. Current methods for mitigating hallucinations generally focus on regularizing the language component, improving the fusion module, or ensembling multiple visual encoders to improve visual representation. In this paper, we address the hallucination issue by directly enhancing the capabilities of the visual component. Our approach, named EAGLE, is fully agnostic to the LLM or fusion module and works as a post-pretraining approach that improves the grounding and language alignment of the visual encoder. We show that a straightforward reformulation of the original contrastive pre-training task results in an improved visual encoder that can be incorporated into the instructional multi-modal architecture without additional instructional training. As a result, EAGLE achieves a significant reduction in hallucinations across multiple challenging benchmarks and tasks.
Pixology: Probing the Linguistic and Visual Capabilities of Pixel-based Language Models
Oct 15, 2024
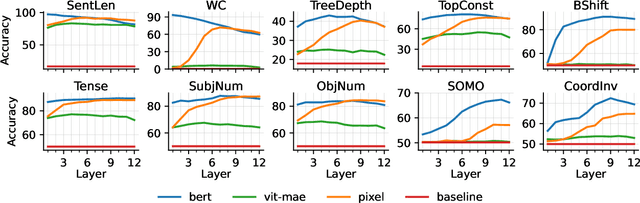
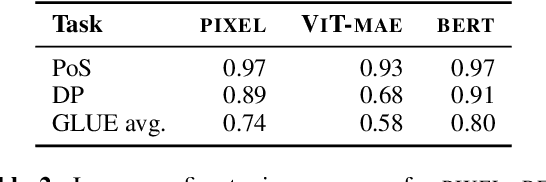
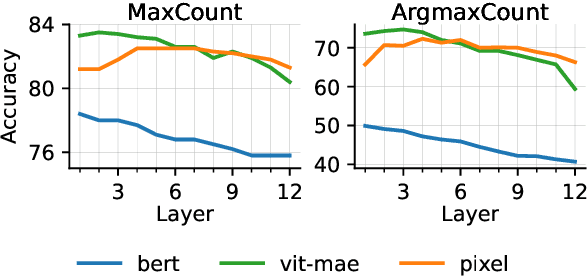
Pixel-based language models have emerged as a compelling alternative to subword-based language modelling, particularly because they can represent virtually any script. PIXEL, a canonical example of such a model, is a vision transformer that has been pre-trained on rendered text. While PIXEL has shown promising cross-script transfer abilities and robustness to orthographic perturbations, it falls short of outperforming monolingual subword counterparts like BERT in most other contexts. This discrepancy raises questions about the amount of linguistic knowledge learnt by these models and whether their performance in language tasks stems more from their visual capabilities than their linguistic ones. To explore this, we probe PIXEL using a variety of linguistic and visual tasks to assess its position on the vision-to-language spectrum. Our findings reveal a substantial gap between the model's visual and linguistic understanding. The lower layers of PIXEL predominantly capture superficial visual features, whereas the higher layers gradually learn more syntactic and semantic abstractions. Additionally, we examine variants of PIXEL trained with different text rendering strategies, discovering that introducing certain orthographic constraints at the input level can facilitate earlier learning of surface-level features. With this study, we hope to provide insights that aid the further development of pixel-based language models.
Learning to Route for Dynamic Adapter Composition in Continual Learning with Language Models
Aug 16, 2024Parameter-efficient fine-tuning (PEFT) methods are increasingly used with pre-trained language models (PLMs) for continual learning (CL). These methods involve training a PEFT module for each new task and using similarity-based selection to route modules during inference. However, they face two major limitations: 1) interference with already learned modules and 2) suboptimal routing when composing modules. In this paper, we introduce a method that isolates the training of PEFT modules for task specialization. Then, before evaluation, it learns to compose the previously learned modules by training a router that leverages samples from a small memory. We evaluate our method in two CL setups using several benchmarks. Our results show that our method provides a better composition of PEFT modules, leading to better generalization and performance compared to previous methods.
Extracting and Encoding: Leveraging Large Language Models and Medical Knowledge to Enhance Radiological Text Representation
Jul 02, 2024
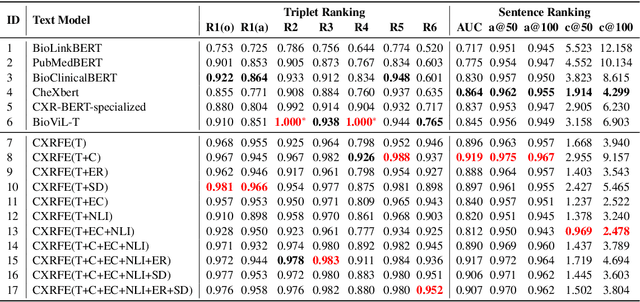
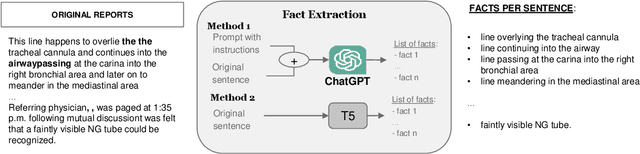
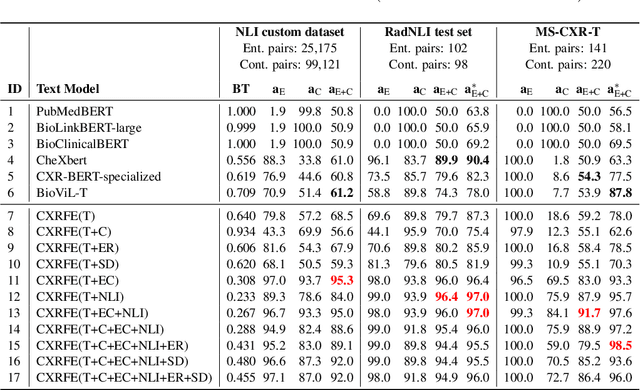
Advancing representation learning in specialized fields like medicine remains challenging due to the scarcity of expert annotations for text and images. To tackle this issue, we present a novel two-stage framework designed to extract high-quality factual statements from free-text radiology reports in order to improve the representations of text encoders and, consequently, their performance on various downstream tasks. In the first stage, we propose a \textit{Fact Extractor} that leverages large language models (LLMs) to identify factual statements from well-curated domain-specific datasets. In the second stage, we introduce a \textit{Fact Encoder} (CXRFE) based on a BERT model fine-tuned with objective functions designed to improve its representations using the extracted factual data. Our framework also includes a new embedding-based metric (CXRFEScore) for evaluating chest X-ray text generation systems, leveraging both stages of our approach. Extensive evaluations show that our fact extractor and encoder outperform current state-of-the-art methods in tasks such as sentence ranking, natural language inference, and label extraction from radiology reports. Additionally, our metric proves to be more robust and effective than existing metrics commonly used in the radiology report generation literature. The code of this project is available at \url{https://github.com/PabloMessina/CXR-Fact-Encoder}.
CVQA: Culturally-diverse Multilingual Visual Question Answering Benchmark
Jun 10, 2024



Visual Question Answering (VQA) is an important task in multimodal AI, and it is often used to test the ability of vision-language models to understand and reason on knowledge present in both visual and textual data. However, most of the current VQA models use datasets that are primarily focused on English and a few major world languages, with images that are typically Western-centric. While recent efforts have tried to increase the number of languages covered on VQA datasets, they still lack diversity in low-resource languages. More importantly, although these datasets often extend their linguistic range via translation or some other approaches, they usually keep images the same, resulting in narrow cultural representation. To address these limitations, we construct CVQA, a new Culturally-diverse multilingual Visual Question Answering benchmark, designed to cover a rich set of languages and cultures, where we engage native speakers and cultural experts in the data collection process. As a result, CVQA includes culturally-driven images and questions from across 28 countries on four continents, covering 26 languages with 11 scripts, providing a total of 9k questions. We then benchmark several Multimodal Large Language Models (MLLMs) on CVQA, and show that the dataset is challenging for the current state-of-the-art models. This benchmark can serve as a probing evaluation suite for assessing the cultural capability and bias of multimodal models and hopefully encourage more research efforts toward increasing cultural awareness and linguistic diversity in this field.
SemEval Task 1: Semantic Textual Relatedness for African and Asian Languages
Apr 04, 2024

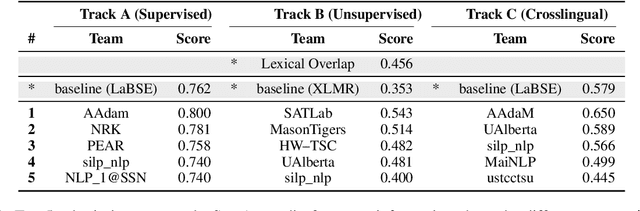
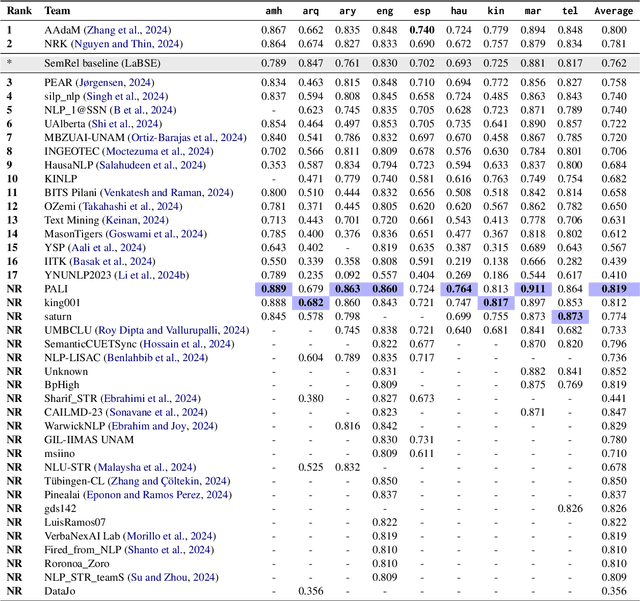
We present the first shared task on Semantic Textual Relatedness (STR). While earlier shared tasks primarily focused on semantic similarity, we instead investigate the broader phenomenon of semantic relatedness across 14 languages: Afrikaans, Algerian Arabic, Amharic, English, Hausa, Hindi, Indonesian, Kinyarwanda, Marathi, Moroccan Arabic, Modern Standard Arabic, Punjabi, Spanish, and Telugu. These languages originate from five distinct language families and are predominantly spoken in Africa and Asia -- regions characterised by the relatively limited availability of NLP resources. Each instance in the datasets is a sentence pair associated with a score that represents the degree of semantic textual relatedness between the two sentences. Participating systems were asked to rank sentence pairs by their closeness in meaning (i.e., their degree of semantic relatedness) in the 14 languages in three main tracks: (a) supervised, (b) unsupervised, and (c) crosslingual. The task attracted 163 participants. We received 70 submissions in total (across all tasks) from 51 different teams, and 38 system description papers. We report on the best-performing systems as well as the most common and the most effective approaches for the three different tracks.
SemRel2024: A Collection of Semantic Textual Relatedness Datasets for 14 Languages
Feb 15, 2024



Exploring and quantifying semantic relatedness is central to representing language. It holds significant implications across various NLP tasks, including offering insights into the capabilities and performance of Large Language Models (LLMs). While earlier NLP research primarily focused on semantic similarity, often within the English language context, we instead investigate the broader phenomenon of semantic relatedness. In this paper, we present SemRel, a new semantic relatedness dataset collection annotated by native speakers across 14 languages:Afrikaans, Algerian Arabic, Amharic, English, Hausa, Hindi, Indonesian, Kinyarwanda, Marathi, Moroccan Arabic, Modern Standard Arabic, Punjabi, Spanish, and Telugu. These languages originate from five distinct language families and are predominantly spoken in Africa and Asia -- regions characterised by a relatively limited availability of NLP resources. Each instance in the SemRel datasets is a sentence pair associated with a score that represents the degree of semantic textual relatedness between the two sentences. The scores are obtained using a comparative annotation framework. We describe the data collection and annotation processes, related challenges when building the datasets, and their impact and utility in NLP. We further report experiments for each language and across the different languages.