 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the Interplay between Positional Encodings, Morphological Complexity, and Word Order Flexibility
Nov 11, 2025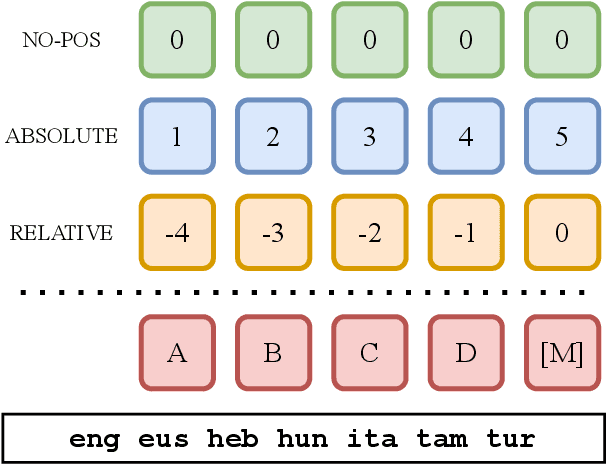
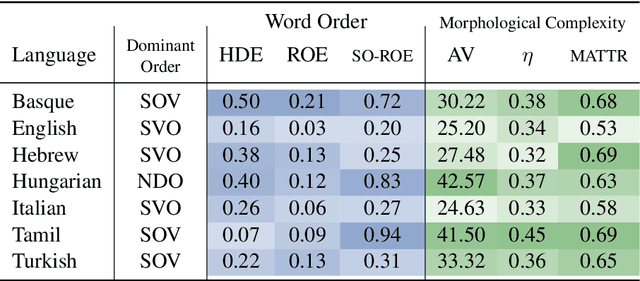

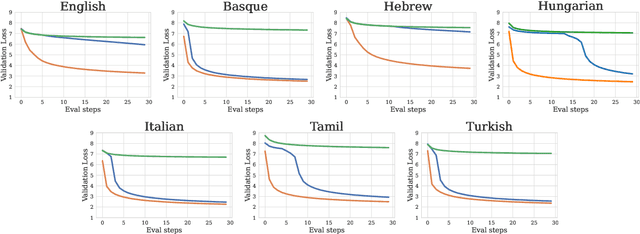
Language model architectures are predominantly first created for English and subsequently applied to other languages. It is an open question whether this architectural bias leads to degraded performance for languages that are structurally different from English. We examine one specific architectural choice: positional encodings, through the lens of the trade-off hypothesis: the supposed interplay between morphological complexity and word order flexibility. This hypothesis posits a trade-off between the two: a more morphologically complex language can have a more flexible word order, and vice-versa. Positional encodings are a direct target to investigate the implications of this hypothesis in relation to language modelling. We pretrain monolingual model variants with absolute, relative, and no positional encodings for seven typologically diverse languages and evaluate them on four downstream tasks. Contrary to previous findings, we do not observe a clear interaction between position encodings and morphological complexity or word order flexibility, as measured by various proxies. Our results show that the choice of tasks, languages, and metrics are essential for drawing stable conclusions
How Good is Your Wikipedia?
Nov 08, 2024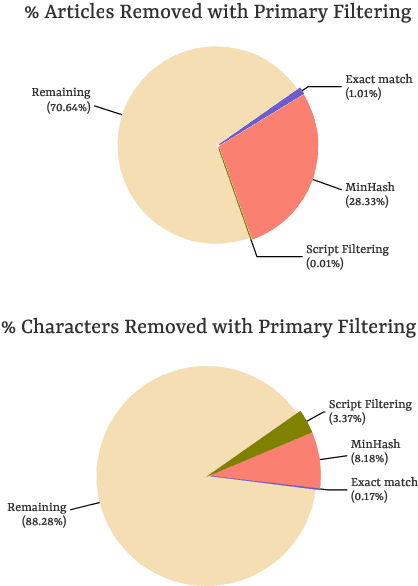

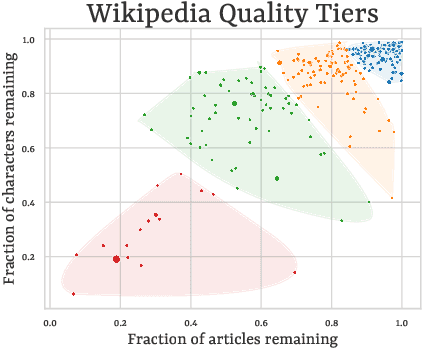
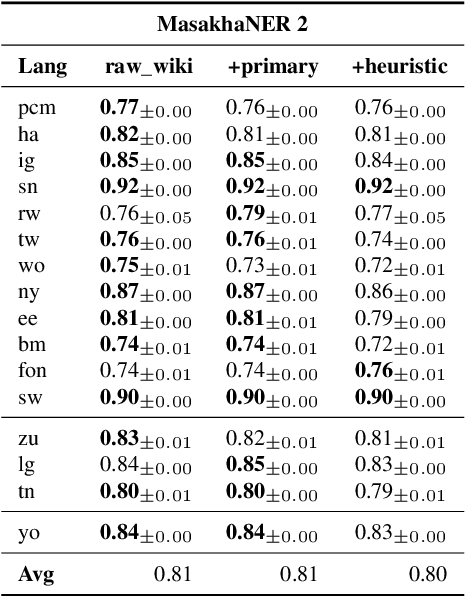
Wikipedia's perceived high quality and broad language coverage have established it as a fundamental resource in multilingual NLP. In the context of low-resource languages, however, these quality assumptions are increasingly being scrutinised. This paper critically examines the data quality of Wikipedia in a non-English setting by subjecting it to various quality filtering techniques, revealing widespread issues such as a high percentage of one-line articles and duplicate articles. We evaluate the downstream impact of quality filtering on Wikipedia and find that data quality pruning is an effective means for resource-efficient training without hurting performance, especially for low-resource languages. Moreover, we advocate for a shift in perspective from seeking a general definition of data quality towards a more language- and task-specific one. Ultimately, we aim for this study to serve as a guide to using Wikipedia for pretraining in a multilingual setting.
Pixology: Probing the Linguistic and Visual Capabilities of Pixel-based Language Models
Oct 15, 2024
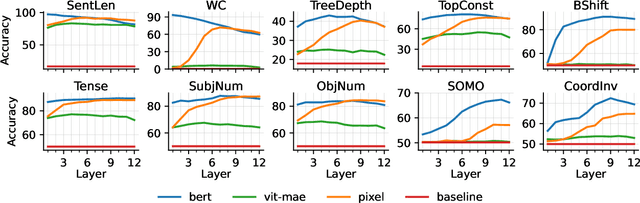
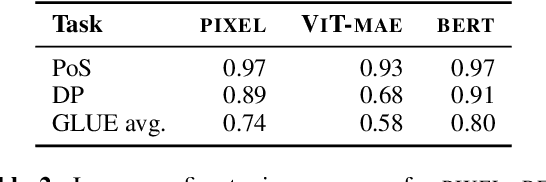
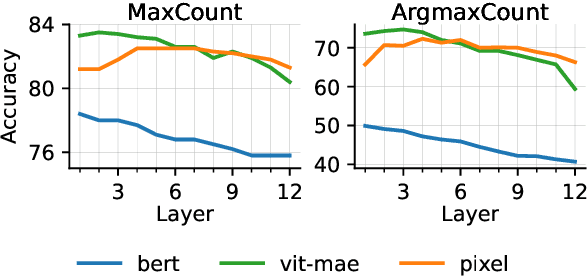
Pixel-based language models have emerged as a compelling alternative to subword-based language modelling, particularly because they can represent virtually any script. PIXEL, a canonical example of such a model, is a vision transformer that has been pre-trained on rendered text. While PIXEL has shown promising cross-script transfer abilities and robustness to orthographic perturbations, it falls short of outperforming monolingual subword counterparts like BERT in most other contexts. This discrepancy raises questions about the amount of linguistic knowledge learnt by these models and whether their performance in language tasks stems more from their visual capabilities than their linguistic ones. To explore this, we probe PIXEL using a variety of linguistic and visual tasks to assess its position on the vision-to-language spectrum. Our findings reveal a substantial gap between the model's visual and linguistic understanding. The lower layers of PIXEL predominantly capture superficial visual features, whereas the higher layers gradually learn more syntactic and semantic abstractions. Additionally, we examine variants of PIXEL trained with different text rendering strategies, discovering that introducing certain orthographic constraints at the input level can facilitate earlier learning of surface-level features. With this study, we hope to provide insights that aid the further development of pixel-based language models.
Sociolinguistically Informed Interpretability: A Case Study on Hinglish Emotion Classification
Feb 05, 2024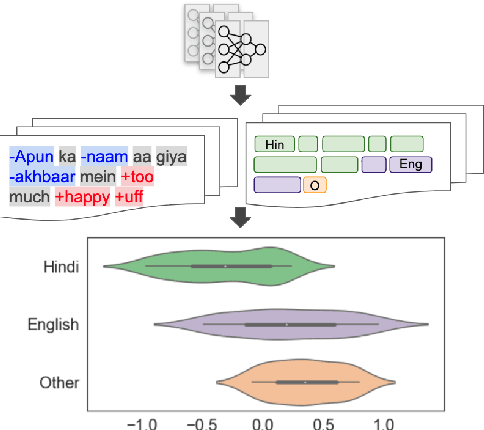

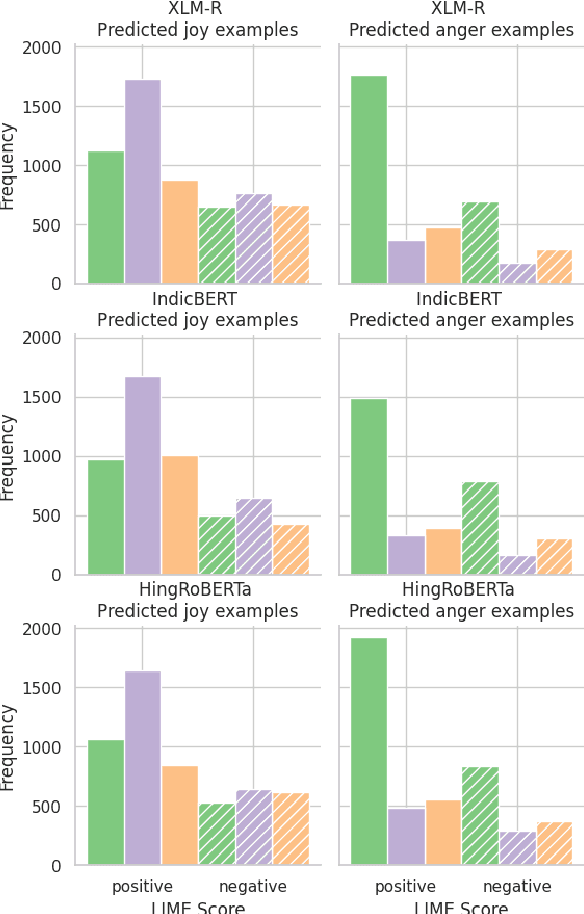

Emotion classification is a challenging task in NLP due to the inherent idiosyncratic and subjective nature of linguistic expression, especially with code-mixed data. Pre-trained language models (PLMs) have achieved high performance for many tasks and languages, but it remains to be seen whether these models learn and are robust to the differences in emotional expression across languages. Sociolinguistic studies have shown that Hinglish speakers switch to Hindi when expressing negative emotions and to English when expressing positive emotions. To understand if language models can learn these associations, we study the effect of language on emotion prediction across 3 PLMs on a Hinglish emotion classification dataset. Using LIME and token level language ID, we find that models do learn these associations between language choice and emotional expression. Moreover, having code-mixed data present in the pre-training can augment that learning when task-specific data is scarce. We also conclude from the misclassifications that the models may overgeneralise this heuristic to other infrequent examples where this sociolinguistic phenomenon does not apply.
CreoleVal: Multilingual Multitask Benchmarks for Creoles
Oct 30, 2023Creoles represent an under-explored and marginalized group of languages, with few available resources for NLP research. While the genealogical ties between Creoles and other highly-resourced languages imply a significant potential for transfer learning, this potential is hampered due to this lack of annotated data. In this work we present CreoleVal, a collection of benchmark datasets spanning 8 different NLP tasks, covering up to 28 Creole languages; it is an aggregate of brand new development datasets for machine comprehension, relation classification, and machine translation for Creoles, in addition to a practical gateway to a handful of preexisting benchmarks. For each benchmark, we conduct baseline experiments in a zero-shot setting in order to further ascertain the capabilities and limitations of transfer learning for Creoles. Ultimately, the goal of CreoleVal is to empower research on Creoles in NLP and computational linguistics. We hope this resource will contribute to technological inclusion for Creole language users around the globe.