 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSPICE: Submodular Penalized Information-Conflict Selection for Efficient Large Language Model Training
Jan 30, 2026Information-based data selection for instruction tuning is compelling: maximizing the log-determinant of the Fisher information yields a monotone submodular objective, enabling greedy algorithms to achieve a $(1-1/e)$ approximation under a cardinality budget. In practice, however, we identify alleviating gradient conflicts, misalignment between per-sample gradients, is a key factor that slows down the decay of marginal log-determinant information gains, thereby preventing significant loss of information. We formalize this via an $\varepsilon$-decomposition that quantifies the deviation from ideal submodularity as a function of conflict statistics, yielding data-dependent approximation factors that tighten as conflicts diminish. Guided by this analysis, we propose SPICE, a conflict-aware selector that maximizes information while penalizing misalignment, and that supports early stopping and proxy models for efficiency. Empirically, SPICE selects subsets with higher log-determinant information than original criteria, and these informational gains translate into performance improvements: across 8 benchmarks with LLaMA2-7B and Qwen2-7B, SPICE uses only 10% of the data, yet matches or exceeds 6 methods including full-data tuning. This achieves performance improvements with substantially lower training cost.
Semantic Leakage from Image Embeddings
Jan 30, 2026Image embeddings are generally assumed to pose limited privacy risk. We challenge this assumption by formalizing semantic leakage as the ability to recover semantic structures from compressed image embeddings. Surprisingly, we show that semantic leakage does not require exact reconstruction of the original image. Preserving local semantic neighborhoods under embedding alignment is sufficient to expose the intrinsic vulnerability of image embeddings. Crucially, this preserved neighborhood structure allows semantic information to propagate through a sequence of lossy mappings. Based on this conjecture, we propose Semantic Leakage from Image Embeddings (SLImE), a lightweight inference framework that reveals semantic information from standalone compressed image embeddings, incorporating a locally trained semantic retriever with off-the-shelf models, without training task-specific decoders. We thoroughly validate each step of the framework empirically, from aligned embeddings to retrieved tags, symbolic representations, and grammatical and coherent descriptions. We evaluate SLImE across a range of open and closed embedding models, including GEMINI, COHERE, NOMIC, and CLIP, and demonstrate consistent recovery of semantic information across diverse inference tasks. Our results reveal a fundamental vulnerability in image embeddings, whereby the preservation of semantic neighborhoods under alignment enables semantic leakage, highlighting challenges for privacy preservation.1
AIConfigurator: Lightning-Fast Configuration Optimization for Multi-Framework LLM Serving
Jan 09, 2026Optimizing Large Language Model (LLM) inference in production systems is increasingly difficult due to dynamic workloads, stringent latency/throughput targets, and a rapidly expanding configuration space. This complexity spans not only distributed parallelism strategies (tensor/pipeline/expert) but also intricate framework-specific runtime parameters such as those concerning the enablement of CUDA graphs, available KV-cache memory fractions, and maximum token capacity, which drastically impact performance. The diversity of modern inference frameworks (e.g., TRT-LLM, vLLM, SGLang), each employing distinct kernels and execution policies, makes manual tuning both framework-specific and computationally prohibitive. We present AIConfigurator, a unified performance-modeling system that enables rapid, framework-agnostic inference configuration search without requiring GPU-based profiling. AIConfigurator combines (1) a methodology that decomposes inference into analytically modelable primitives - GEMM, attention, communication, and memory operations while capturing framework-specific scheduling dynamics; (2) a calibrated kernel-level performance database for these primitives across a wide range of hardware platforms and popular open-weights models (GPT-OSS, Qwen, DeepSeek, LLama, Mistral); and (3) an abstraction layer that automatically resolves optimal launch parameters for the target backend, seamlessly integrating into production-grade orchestration systems. Evaluation on production LLM serving workloads demonstrates that AIConfigurator identifies superior serving configurations that improve performance by up to 40% for dense models (e.g., Qwen3-32B) and 50% for MoE architectures (e.g., DeepSeek-V3), while completing searches within 30 seconds on average. Enabling the rapid exploration of vast design spaces - from cluster topology down to engine specific flags.
Do LLMs Really Memorize Personally Identifiable Information? Revisiting PII Leakage with a Cue-Controlled Memorization Framework
Jan 07, 2026Large Language Models (LLMs) have been reported to "leak" Personally Identifiable Information (PII), with successful PII reconstruction often interpreted as evidence of memorization. We propose a principled revision of memorization evaluation for LLMs, arguing that PII leakage should be evaluated under low lexical cue conditions, where target PII cannot be reconstructed through prompt-induced generalization or pattern completion. We formalize Cue-Resistant Memorization (CRM) as a cue-controlled evaluation framework and a necessary condition for valid memorization evaluation, explicitly conditioning on prompt-target overlap cues. Using CRM, we conduct a large-scale multilingual re-evaluation of PII leakage across 32 languages and multiple memorization paradigms. Revisiting reconstruction-based settings, including verbatim prefix-suffix completion and associative reconstruction, we find that their apparent effectiveness is driven primarily by direct surface-form cues rather than by true memorization. When such cues are controlled for, reconstruction success diminishes substantially. We further examine cue-free generation and membership inference, both of which exhibit extremely low true positive rates. Overall, our results suggest that previously reported PII leakage is better explained by cue-driven behavior than by genuine memorization, highlighting the importance of cue-controlled evaluation for reliably quantifying privacy-relevant memorization in LLMs.
Shared Path: Unraveling Memorization in Multilingual LLMs through Language Similarities
May 21, 2025We present the first comprehensive study of Memorization in Multilingual Large Language Models (MLLMs), analyzing 95 languages using models across diverse model scales, architectures, and memorization definitions. As MLLMs are increasingly deployed, understanding their memorization behavior has become critical. Yet prior work has focused primarily on monolingual models, leaving multilingual memorization underexplored, despite the inherently long-tailed nature of training corpora. We find that the prevailing assumption, that memorization is highly correlated with training data availability, fails to fully explain memorization patterns in MLLMs. We hypothesize that treating languages in isolation - ignoring their similarities - obscures the true patterns of memorization. To address this, we propose a novel graph-based correlation metric that incorporates language similarity to analyze cross-lingual memorization. Our analysis reveals that among similar languages, those with fewer training tokens tend to exhibit higher memorization, a trend that only emerges when cross-lingual relationships are explicitly modeled. These findings underscore the importance of a language-aware perspective in evaluating and mitigating memorization vulnerabilities in MLLMs. This also constitutes empirical evidence that language similarity both explains Memorization in MLLMs and underpins Cross-lingual Transferability, with broad implications for multilingual NLP.
LAGO: Few-shot Crosslingual Embedding Inversion Attacks via Language Similarity-Aware Graph Optimization
May 21, 2025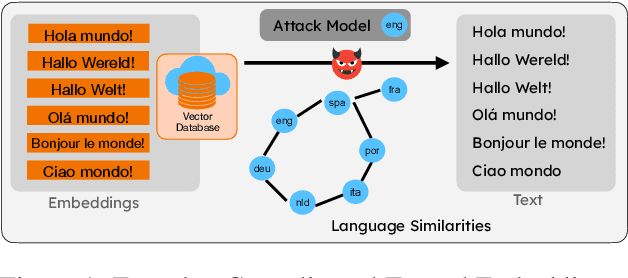
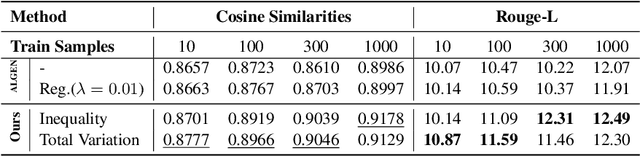
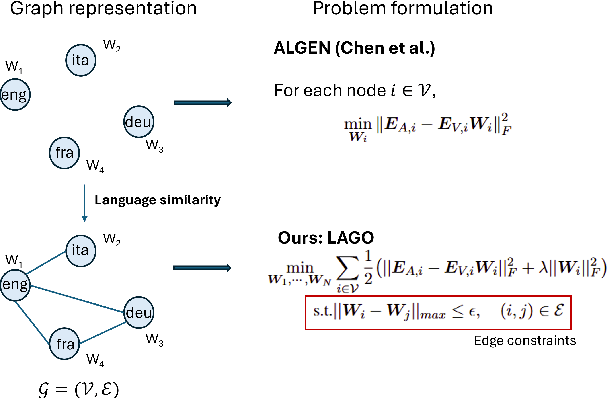
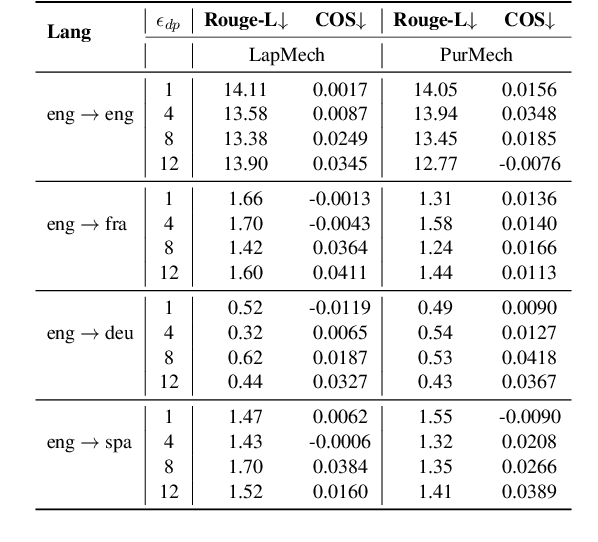
We propose LAGO - Language Similarity-Aware Graph Optimization - a novel approach for few-shot cross-lingual embedding inversion attacks, addressing critical privacy vulnerabilities in multilingual NLP systems. Unlike prior work in embedding inversion attacks that treat languages independently, LAGO explicitly models linguistic relationships through a graph-based constrained distributed optimization framework. By integrating syntactic and lexical similarity as edge constraints, our method enables collaborative parameter learning across related languages. Theoretically, we show this formulation generalizes prior approaches, such as ALGEN, which emerges as a special case when similarity constraints are relaxed. Our framework uniquely combines Frobenius-norm regularization with linear inequality or total variation constraints, ensuring robust alignment of cross-lingual embedding spaces even with extremely limited data (as few as 10 samples per language). Extensive experiments across multiple languages and embedding models demonstrate that LAGO substantially improves the transferability of attacks with 10-20% increase in Rouge-L score over baselines. This work establishes language similarity as a critical factor in inversion attack transferability, urging renewed focus on language-aware privacy-preserving multilingual embeddings.
NLP Security and Ethics, in the Wild
Apr 09, 2025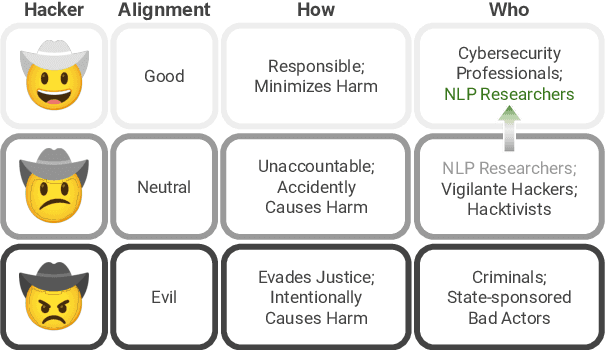
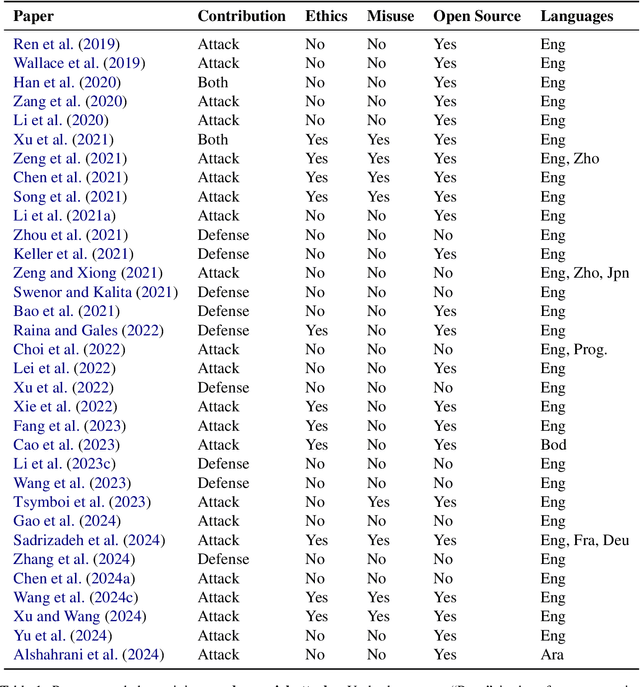
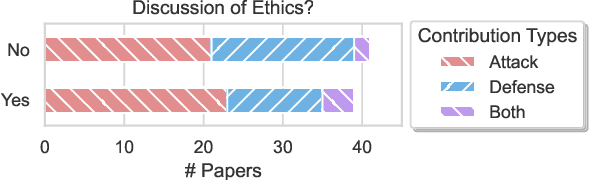
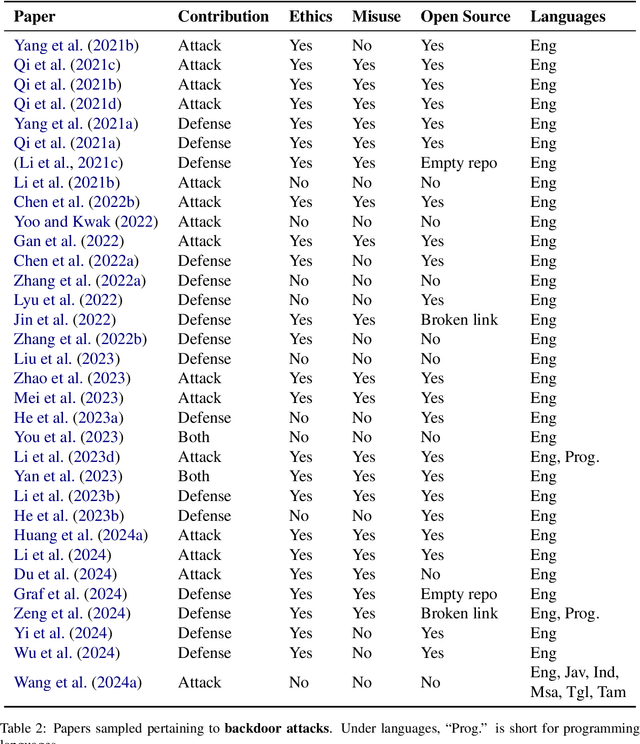
As NLP models are used by a growing number of end-users, an area of increasing importance is NLP Security (NLPSec): assessing the vulnerability of models to malicious attacks and developing comprehensive countermeasures against them. While work at the intersection of NLP and cybersecurity has the potential to create safer NLP for all, accidental oversights can result in tangible harm (e.g., breaches of privacy or proliferation of malicious models). In this emerging field, however, the research ethics of NLP have not yet faced many of the long-standing conundrums pertinent to cybersecurity, until now. We thus examine contemporary works across NLPSec, and explore their engagement with cybersecurity's ethical norms. We identify trends across the literature, ultimately finding alarming gaps on topics like harm minimization and responsible disclosure. To alleviate these concerns, we provide concrete recommendations to help NLP researchers navigate this space more ethically, bridging the gap between traditional cybersecurity and NLP ethics, which we frame as ``white hat NLP''. The goal of this work is to help cultivate an intentional culture of ethical research for those working in NLP Security.
Trustworthy Machine Learning via Memorization and the Granular Long-Tail: A Survey on Interactions, Tradeoffs, and Beyond
Mar 10, 2025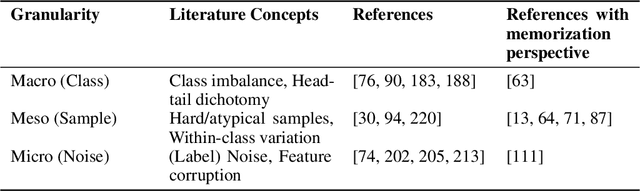

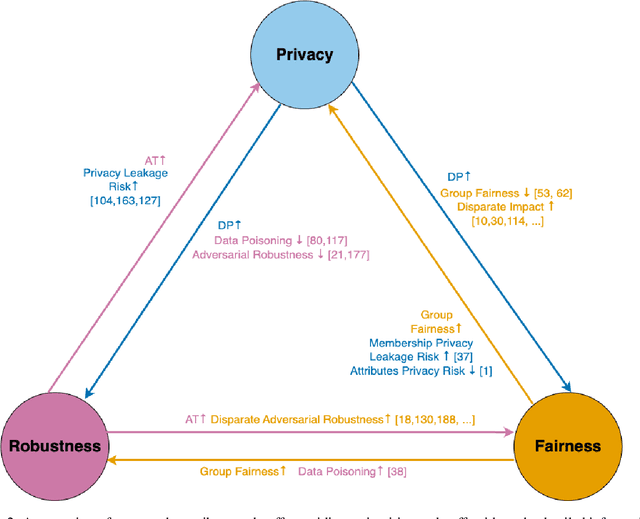
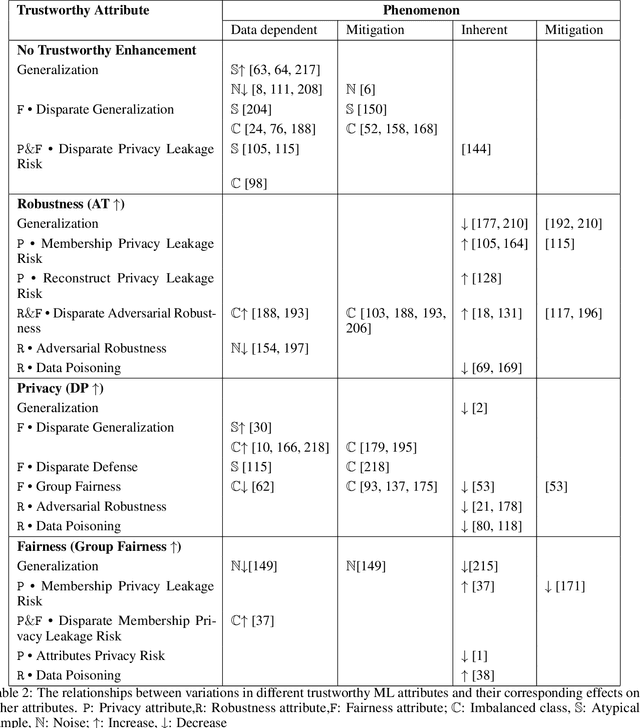
The role of memorization in machine learning (ML) has garnered significant attention, particularly as modern models are empirically observed to memorize fragments of training data. Previous theoretical analyses, such as Feldman's seminal work, attribute memorization to the prevalence of long-tail distributions in training data, proving it unavoidable for samples that lie in the tail of the distribution. However, the intersection of memorization and trustworthy ML research reveals critical gaps. While prior research in memorization in trustworthy ML has solely focused on class imbalance, recent work starts to differentiate class-level rarity from atypical samples, which are valid and rare intra-class instances. However, a critical research gap remains: current frameworks conflate atypical samples with noisy and erroneous data, neglecting their divergent impacts on fairness, robustness, and privacy. In this work, we conduct a thorough survey of existing research and their findings on trustworthy ML and the role of memorization. More and beyond, we identify and highlight uncharted gaps and propose new revenues in this research direction. Since existing theoretical and empirical analyses lack the nuances to disentangle memorization's duality as both a necessity and a liability, we formalize three-level long-tail granularity - class imbalance, atypicality, and noise - to reveal how current frameworks misapply these levels, perpetuating flawed solutions. By systematizing this granularity, we draw a roadmap for future research. Trustworthy ML must reconcile the nuanced trade-offs between memorizing atypicality for fairness assurance and suppressing noise for robustness and privacy guarantee. Redefining memorization via this granularity reshapes the theoretical foundation for trustworthy ML, and further affords an empirical prerequisite for models that align performance with societal trust.
How Do Hackathons Foster Creativity? Towards AI Collaborative Evaluation of Creativity at Scale
Mar 06, 2025Hackathons have become popular collaborative events for accelerating the development of creative ideas and prototypes. There are several case studies showcasing creative outcomes across domains such as industry, education, and research. However, there are no large-scale studies on creativity in hackathons which can advance theory on how hackathon formats lead to creative outcomes. We conducted a computational analysis of 193,353 hackathon projects. By operationalizing creativity through usefulness and novelty, we refined our dataset to 10,363 projects, allowing us to analyze how participant characteristics, collaboration patterns, and hackathon setups influence the development of creative projects. The contribution of our paper is twofold: We identified means for organizers to foster creativity in hackathons. We also explore the use of large language models (LLMs) to augment the evaluation of creative outcomes and discuss challenges and opportunities of doing this, which has implications for creativity research at large.
Large Language Models are Easily Confused: A Quantitative Metric, Security Implications and Typological Analysis
Oct 17, 2024
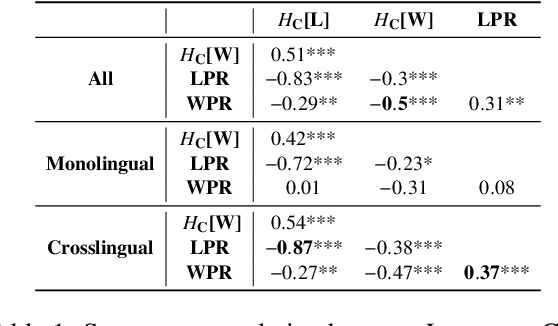

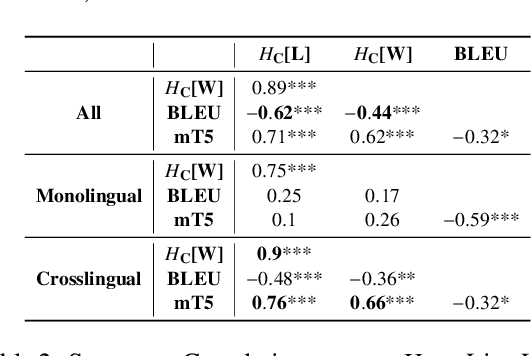
Language Confusion is a phenomenon where Large Language Models (LLMs) generate text that is neither in the desired language, nor in a contextually appropriate language. This phenomenon presents a critical challenge in text generation by LLMs, often appearing as erratic and unpredictable behavior. We hypothesize that there are linguistic regularities to this inherent vulnerability in LLMs and shed light on patterns of language confusion across LLMs. We introduce a novel metric, Language Confusion Entropy, designed to directly measure and quantify this confusion, based on language distributions informed by linguistic typology and lexical variation. Comprehensive comparisons with the Language Confusion Benchmark (Marchisio et al., 2024) confirm the effectiveness of our metric, revealing patterns of language confusion across LLMs. We further link language confusion to LLM security, and find patterns in the case of multilingual embedding inversion attacks. Our analysis demonstrates that linguistic typology offers theoretically grounded interpretation, and valuable insights into leveraging language similarities as a prior for LLM alignment and security.