 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeD&M: Enriching E-commerce Videos with Sound Effects by Key Moment Detection and SFX Matching
Aug 23, 2024Videos showcasing specific products are increasingly important for E-commerce. Key moments naturally exist as the first appearance of a specific product, presentation of its distinctive features, the presence of a buying link, etc. Adding proper sound effects (SFX) to these key moments, or video decoration with SFX (VDSFX), is crucial for enhancing the user engaging experience. Previous studies about adding SFX to videos perform video to SFX matching at a holistic level, lacking the ability of adding SFX to a specific moment. Meanwhile, previous studies on video highlight detection or video moment retrieval consider only moment localization, leaving moment to SFX matching untouched. By contrast, we propose in this paper D&M, a unified method that accomplishes key moment detection and moment to SFX matching simultaneously. Moreover, for the new VDSFX task we build a large-scale dataset SFX-Moment from an E-commerce platform. For a fair comparison, we build competitive baselines by extending a number of current video moment detection methods to the new task. Extensive experiments on SFX-Moment show the superior performance of the proposed method over the baselines. Code and data will be released.
Spatiotemporal Graph Guided Multi-modal Network for Livestreaming Product Retrieval
Jul 24, 2024With the rapid expansion of e-commerce, more consumers have become accustomed to making purchases via livestreaming. Accurately identifying the products being sold by salespeople, i.e., livestreaming product retrieval (LPR), poses a fundamental and daunting challenge. The LPR task encompasses three primary dilemmas in real-world scenarios: 1) the recognition of intended products from distractor products present in the background; 2) the video-image heterogeneity that the appearance of products showcased in live streams often deviates substantially from standardized product images in stores; 3) there are numerous confusing products with subtle visual nuances in the shop. To tackle these challenges, we propose the Spatiotemporal Graphing Multi-modal Network (SGMN). First, we employ a text-guided attention mechanism that leverages the spoken content of salespeople to guide the model to focus toward intended products, emphasizing their salience over cluttered background products. Second, a long-range spatiotemporal graph network is further designed to achieve both instance-level interaction and frame-level matching, solving the misalignment caused by video-image heterogeneity. Third, we propose a multi-modal hard example mining, assisting the model in distinguishing highly similar products with fine-grained features across the video-image-text domain. Through extensive quantitative and qualitative experiments, we demonstrate the superior performance of our proposed SGMN model, surpassing the state-of-the-art methods by a substantial margin. The code is available at https://github.com/Huxiaowan/SGMN.
Reducing the Covariate Shift by Mirror Samples in Cross Domain Alignment
Oct 13, 2021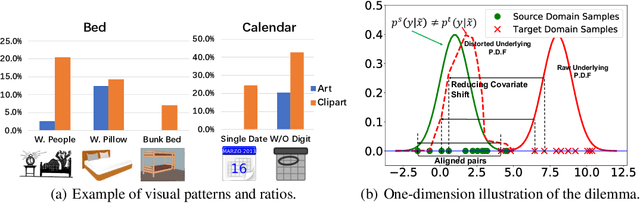
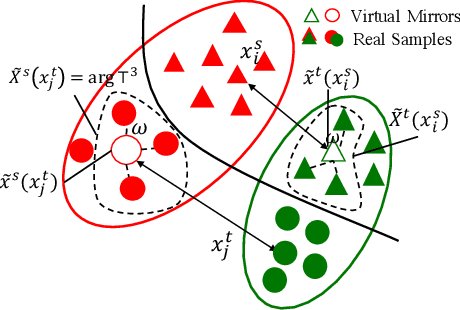

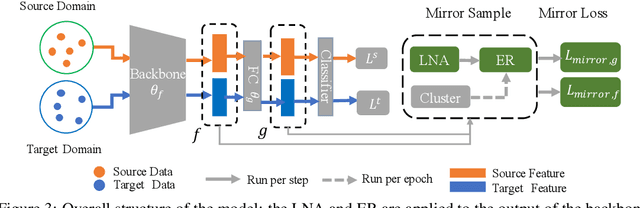
Eliminating the covariate shift cross domains is one of the common methods to deal with the issue of domain shift in visual unsupervised domain adaptation. However, current alignment methods, especially the prototype based or sample-level based methods neglect the structural properties of the underlying distribution and even break the condition of covariate shift. To relieve the limitations and conflicts, we introduce a novel concept named (virtual) mirror, which represents the equivalent sample in another domain. The equivalent sample pairs, named mirror pairs reflect the natural correspondence of the empirical distributions. Then a mirror loss, which aligns the mirror pairs cross domains, is constructed to enhance the alignment of the domains. The proposed method does not distort the internal structure of the underlying distribution. We also provide theoretical proof that the mirror samples and mirror loss have better asymptotic properties in reducing the domain shift. By applying the virtual mirror and mirror loss to the generic unsupervised domain adaptation model, we achieved consistent superior performance on several mainstream benchmarks.