 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMeasuring and Controlling the Spectral Bias for Self-Supervised Image Denoising
Oct 01, 2025Current self-supervised denoising methods for paired noisy images typically involve mapping one noisy image through the network to the other noisy image. However, after measuring the spectral bias of such methods using our proposed Image Pair Frequency-Band Similarity, it suffers from two practical limitations. Firstly, the high-frequency structural details in images are not preserved well enough. Secondly, during the process of fitting high frequencies, the network learns high-frequency noise from the mapped noisy images. To address these challenges, we introduce a Spectral Controlling network (SCNet) to optimize self-supervised denoising of paired noisy images. First, we propose a selection strategy to choose frequency band components for noisy images, to accelerate the convergence speed of training. Next, we present a parameter optimization method that restricts the learning ability of convolutional kernels to high-frequency noise using the Lipschitz constant, without changing the network structure. Finally, we introduce the Spectral Separation and low-rank Reconstruction module (SSR module), which separates noise and high-frequency details through frequency domain separation and low-rank space reconstruction, to retain the high-frequency structural details of images. Experiments performed on synthetic and real-world datasets verify the effectiveness of SCNet.
Interpretable Unsupervised Joint Denoising and Enhancement for Real-World low-light Scenarios
Mar 17, 2025
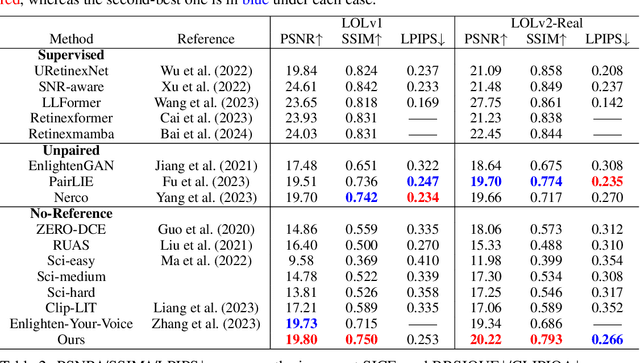
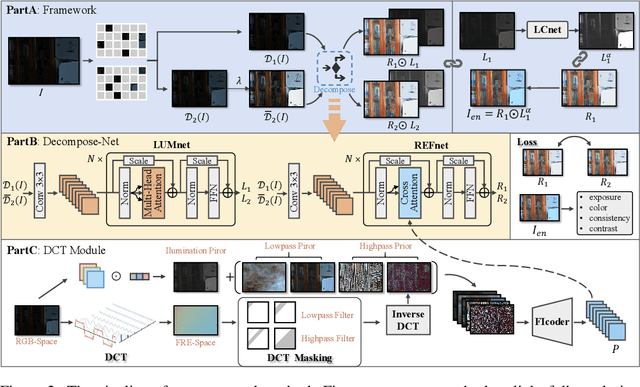
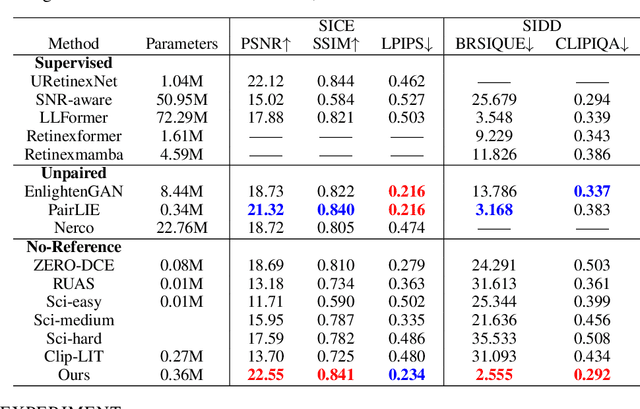
Real-world low-light images often suffer from complex degradations such as local overexposure, low brightness, noise, and uneven illumination. Supervised methods tend to overfit to specific scenarios, while unsupervised methods, though better at generalization, struggle to model these degradations due to the lack of reference images. To address this issue, we propose an interpretable, zero-reference joint denoising and low-light enhancement framework tailored for real-world scenarios. Our method derives a training strategy based on paired sub-images with varying illumination and noise levels, grounded in physical imaging principles and retinex theory. Additionally, we leverage the Discrete Cosine Transform (DCT) to perform frequency domain decomposition in the sRGB space, and introduce an implicit-guided hybrid representation strategy that effectively separates intricate compounded degradations. In the backbone network design, we develop retinal decomposition network guided by implicit degradation representation mechanisms. Extensive experiments demonstrate the superiority of our method. Code will be available at https://github.com/huaqlili/unsupervised-light-enhance-ICLR2025.
Prompt-SID: Learning Structural Representation Prompt via Latent Diffusion for Single-Image Denoising
Feb 10, 2025



Many studies have concentrated on constructing supervised models utilizing paired datasets for image denoising, which proves to be expensive and time-consuming. Current self-supervised and unsupervised approaches typically rely on blind-spot networks or sub-image pairs sampling, resulting in pixel information loss and destruction of detailed structural information, thereby significantly constraining the efficacy of such methods. In this paper, we introduce Prompt-SID, a prompt-learning-based single image denoising framework that emphasizes preserving of structural details. This approach is trained in a self-supervised manner using downsampled image pairs. It captures original-scale image information through structural encoding and integrates this prompt into the denoiser. To achieve this, we propose a structural representation generation model based on the latent diffusion process and design a structural attention module within the transformer-based denoiser architecture to decode the prompt. Additionally, we introduce a scale replay training mechanism, which effectively mitigates the scale gap from images of different resolutions. We conduct comprehensive experiments on synthetic, real-world, and fluorescence imaging datasets, showcasing the remarkable effectiveness of Prompt-SID.
Spatiotemporal Blind-Spot Network with Calibrated Flow Alignment for Self-Supervised Video Denoising
Dec 16, 2024Self-supervised video denoising aims to remove noise from videos without relying on ground truth data, leveraging the video itself to recover clean frames. Existing methods often rely on simplistic feature stacking or apply optical flow without thorough analysis. This results in suboptimal utilization of both inter-frame and intra-frame information, and it also neglects the potential of optical flow alignment under self-supervised conditions, leading to biased and insufficient denoising outcomes. To this end, we first explore the practicality of optical flow in the self-supervised setting and introduce a SpatioTemporal Blind-spot Network (STBN) for global frame feature utilization. In the temporal domain, we utilize bidirectional blind-spot feature propagation through the proposed blind-spot alignment block to ensure accurate temporal alignment and effectively capture long-range dependencies. In the spatial domain, we introduce the spatial receptive field expansion module, which enhances the receptive field and improves global perception capabilities. Additionally, to reduce the sensitivity of optical flow estimation to noise, we propose an unsupervised optical flow distillation mechanism that refines fine-grained inter-frame interactions during optical flow alignment. Our method demonstrates superior performance across both synthetic and real-world video denoising datasets. The source code is publicly available at https://github.com/ZKCCZ/STBN.
Spatiotemporal Graph Guided Multi-modal Network for Livestreaming Product Retrieval
Jul 24, 2024With the rapid expansion of e-commerce, more consumers have become accustomed to making purchases via livestreaming. Accurately identifying the products being sold by salespeople, i.e., livestreaming product retrieval (LPR), poses a fundamental and daunting challenge. The LPR task encompasses three primary dilemmas in real-world scenarios: 1) the recognition of intended products from distractor products present in the background; 2) the video-image heterogeneity that the appearance of products showcased in live streams often deviates substantially from standardized product images in stores; 3) there are numerous confusing products with subtle visual nuances in the shop. To tackle these challenges, we propose the Spatiotemporal Graphing Multi-modal Network (SGMN). First, we employ a text-guided attention mechanism that leverages the spoken content of salespeople to guide the model to focus toward intended products, emphasizing their salience over cluttered background products. Second, a long-range spatiotemporal graph network is further designed to achieve both instance-level interaction and frame-level matching, solving the misalignment caused by video-image heterogeneity. Third, we propose a multi-modal hard example mining, assisting the model in distinguishing highly similar products with fine-grained features across the video-image-text domain. Through extensive quantitative and qualitative experiments, we demonstrate the superior performance of our proposed SGMN model, surpassing the state-of-the-art methods by a substantial margin. The code is available at https://github.com/Huxiaowan/SGMN.
Unsupervised Flow-Aligned Sequence-to-Sequence Learning for Video Restoration
May 20, 2022
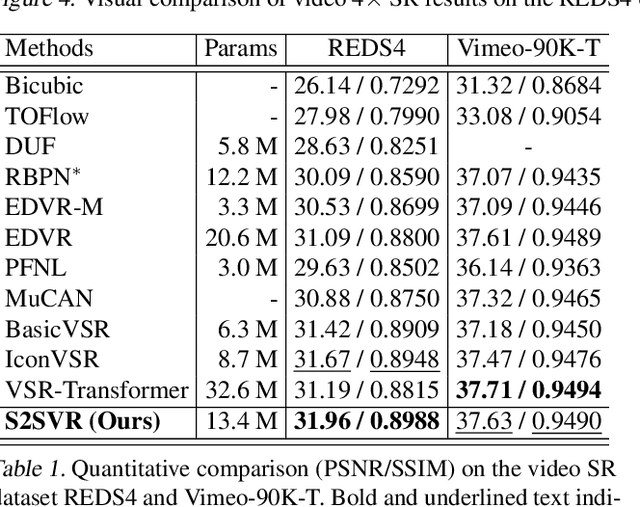
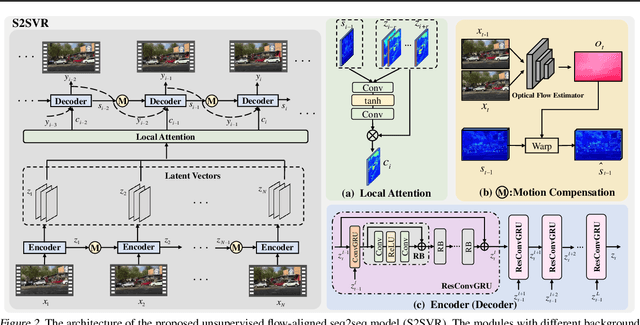
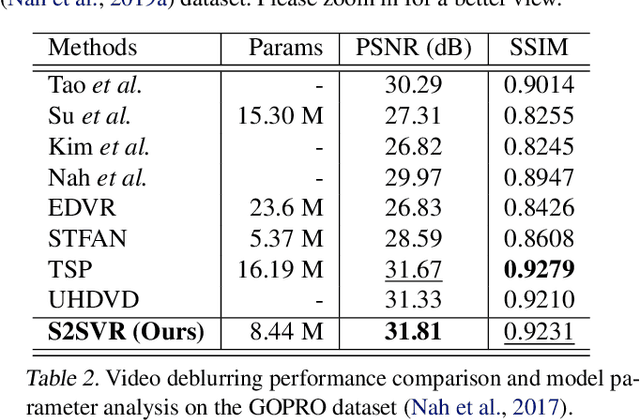
How to properly model the inter-frame relation within the video sequence is an important but unsolved challenge for video restoration (VR). In this work, we propose an unsupervised flow-aligned sequence-to-sequence model (S2SVR) to address this problem. On the one hand, the sequence-to-sequence model, which has proven capable of sequence modeling in the field of natural language processing, is explored for the first time in VR. Optimized serialization modeling shows potential in capturing long-range dependencies among frames. On the other hand, we equip the sequence-to-sequence model with an unsupervised optical flow estimator to maximize its potential. The flow estimator is trained with our proposed unsupervised distillation loss, which can alleviate the data discrepancy and inaccurate degraded optical flow issues of previous flow-based methods. With reliable optical flow, we can establish accurate correspondence among multiple frames, narrowing the domain difference between 1D language and 2D misaligned frames and improving the potential of the sequence-to-sequence model. S2SVR shows superior performance in multiple VR tasks, including video deblurring, video super-resolution, and compressed video quality enhancement. Code and models are publicly available at https://github.com/linjing7/VR-Baseline
Learning to Generate Realistic Noisy Images via Pixel-level Noise-aware Adversarial Training
Apr 06, 2022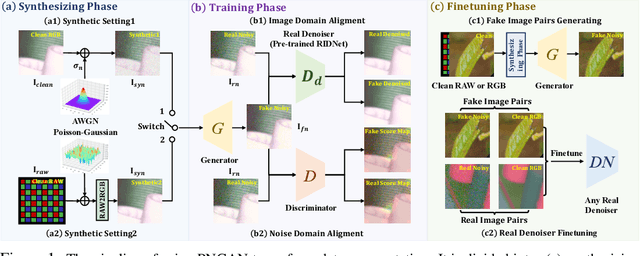
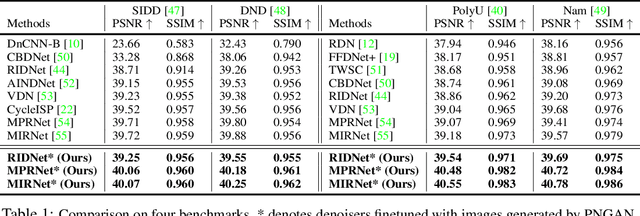
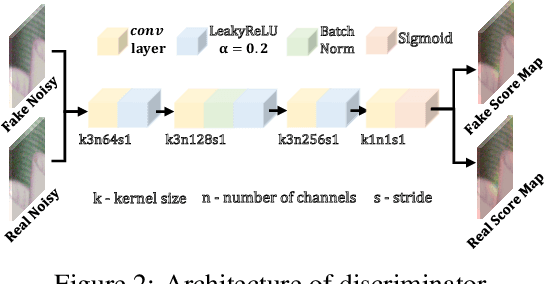

Existing deep learning real denoising methods require a large amount of noisy-clean image pairs for supervision. Nonetheless, capturing a real noisy-clean dataset is an unacceptable expensive and cumbersome procedure. To alleviate this problem, this work investigates how to generate realistic noisy images. Firstly, we formulate a simple yet reasonable noise model that treats each real noisy pixel as a random variable. This model splits the noisy image generation problem into two sub-problems: image domain alignment and noise domain alignment. Subsequently, we propose a novel framework, namely Pixel-level Noise-aware Generative Adversarial Network (PNGAN). PNGAN employs a pre-trained real denoiser to map the fake and real noisy images into a nearly noise-free solution space to perform image domain alignment. Simultaneously, PNGAN establishes a pixel-level adversarial training to conduct noise domain alignment. Additionally, for better noise fitting, we present an efficient architecture Simple Multi-scale Network (SMNet) as the generator. Qualitative validation shows that noise generated by PNGAN is highly similar to real noise in terms of intensity and distribution. Quantitative experiments demonstrate that a series of denoisers trained with the generated noisy images achieve state-of-the-art (SOTA) results on four real denoising benchmarks.
Coarse-to-Fine Sparse Transformer for Hyperspectral Image Reconstruction
Mar 09, 2022
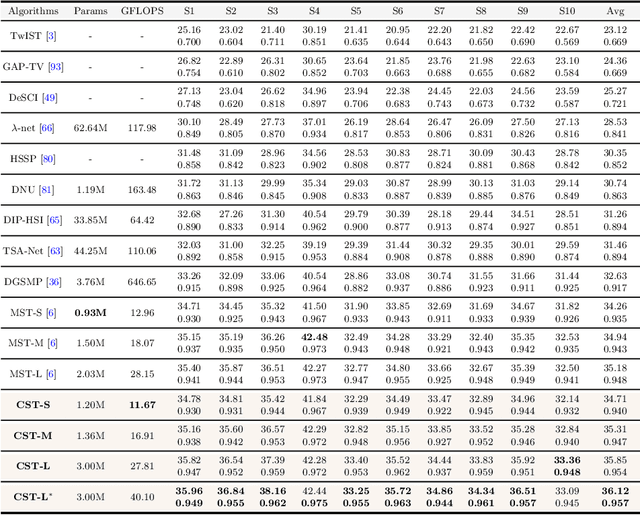
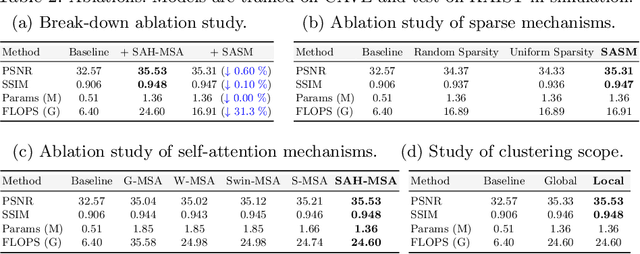
Many algorithms have been developed to solve the inverse problem of coded aperture snapshot spectral imaging (CASSI), i.e., recovering the 3D hyperspectral images (HSIs) from a 2D compressive measurement. In recent years, learning-based methods have demonstrated promising performance and dominated the mainstream research direction. However, existing CNN-based methods show limitations in capturing long-range dependencies and non-local self-similarity. Previous Transformer-based methods densely sample tokens, some of which are uninformative, and calculate the multi-head self-attention (MSA) between some tokens that are unrelated in content. This does not fit the spatially sparse nature of HSI signals and limits the model scalability. In this paper, we propose a novel Transformer-based method, coarse-to-fine sparse Transformer (CST), firstly embedding HSI sparsity into deep learning for HSI reconstruction. In particular, CST uses our proposed spectra-aware screening mechanism (SASM) for coarse patch selecting. Then the selected patches are fed into our customized spectra-aggregation hashing multi-head self-attention (SAH-MSA) for fine pixel clustering and self-similarity capturing. Comprehensive experiments show that our CST significantly outperforms state-of-the-art methods while requiring cheaper computational costs. The code and models will be made public.
HDNet: High-resolution Dual-domain Learning for Spectral Compressive Imaging
Mar 04, 2022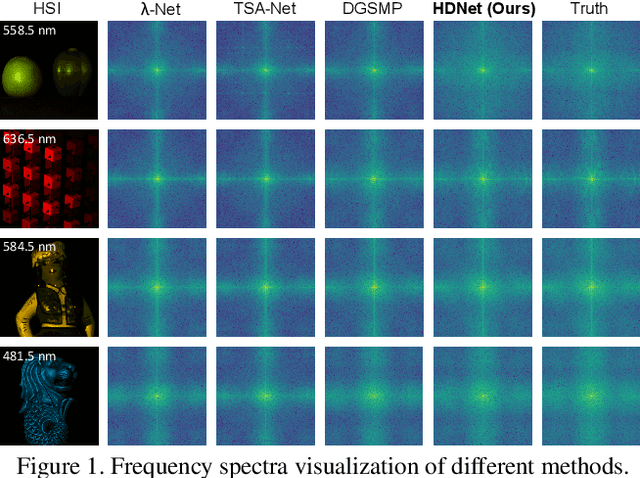
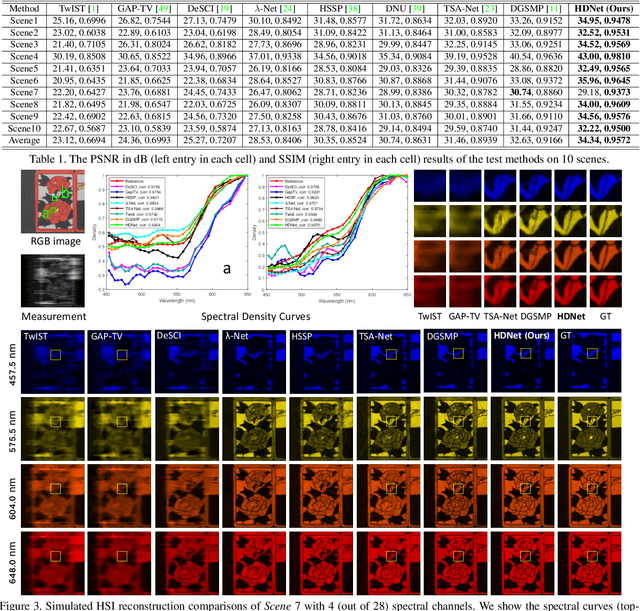
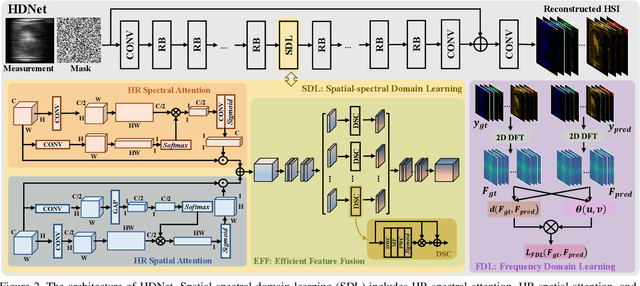

The rapid development of deep learning provides a better solution for the end-to-end reconstruction of hyperspectral image (HSI). However, existing learning-based methods have two major defects. Firstly, networks with self-attention usually sacrifice internal resolution to balance model performance against complexity, losing fine-grained high-resolution (HR) features. Secondly, even if the optimization focusing on spatial-spectral domain learning (SDL) converges to the ideal solution, there is still a significant visual difference between the reconstructed HSI and the truth. Therefore, we propose a high-resolution dual-domain learning network (HDNet) for HSI reconstruction. On the one hand, the proposed HR spatial-spectral attention module with its efficient feature fusion provides continuous and fine pixel-level features. On the other hand, frequency domain learning (FDL) is introduced for HSI reconstruction to narrow the frequency domain discrepancy. Dynamic FDL supervision forces the model to reconstruct fine-grained frequencies and compensate for excessive smoothing and distortion caused by pixel-level losses. The HR pixel-level attention and frequency-level refinement in our HDNet mutually promote HSI perceptual quality. Extensive quantitative and qualitative evaluation experiments show that our method achieves SOTA performance on simulated and real HSI datasets. Code and models will be released.
Flow-Guided Sparse Transformer for Video Deblurring
Jan 06, 2022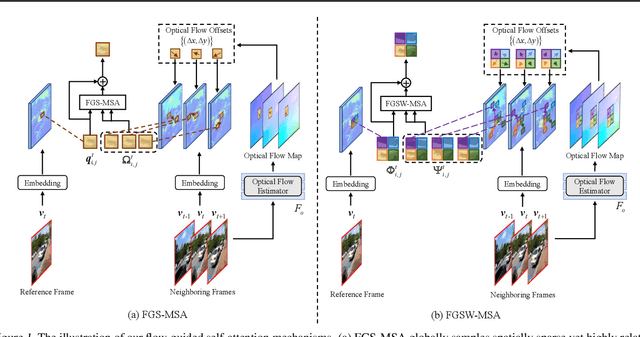
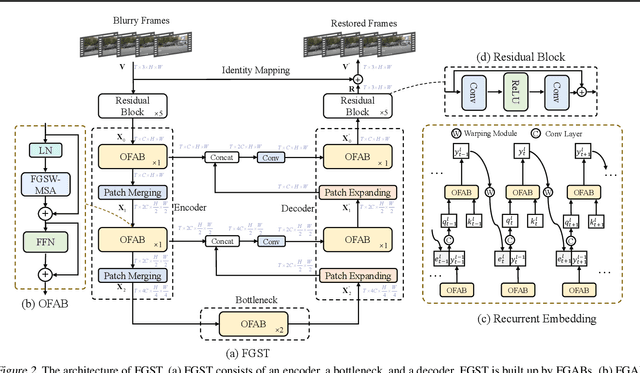

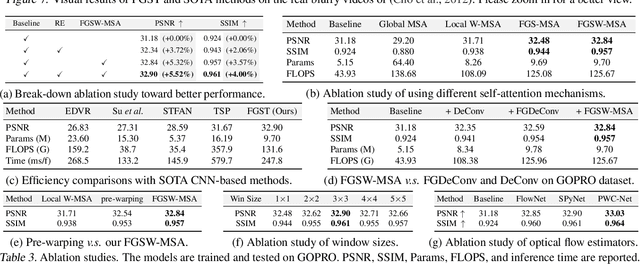
Exploiting similar and sharper scene patches in spatio-temporal neighborhoods is critical for video deblurring. However, CNN-based methods show limitations in capturing long-range dependencies and modeling non-local self-similarity. In this paper, we propose a novel framework, Flow-Guided Sparse Transformer (FGST), for video deblurring. In FGST, we customize a self-attention module, Flow-Guided Sparse Window-based Multi-head Self-Attention (FGSW-MSA). For each $query$ element on the blurry reference frame, FGSW-MSA enjoys the guidance of the estimated optical flow to globally sample spatially sparse yet highly related $key$ elements corresponding to the same scene patch in neighboring frames. Besides, we present a Recurrent Embedding (RE) mechanism to transfer information from past frames and strengthen long-range temporal dependencies. Comprehensive experiments demonstrate that our proposed FGST outperforms state-of-the-art (SOTA) methods on both DVD and GOPRO datasets and even yields more visually pleasing results in real video deblurring. Code and models will be released to the public.