 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLow-Res Leads the Way: Improving Generalization for Super-Resolution by Self-Supervised Learning
Mar 05, 2024
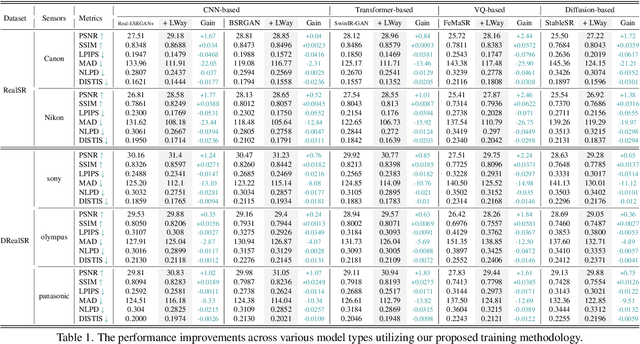
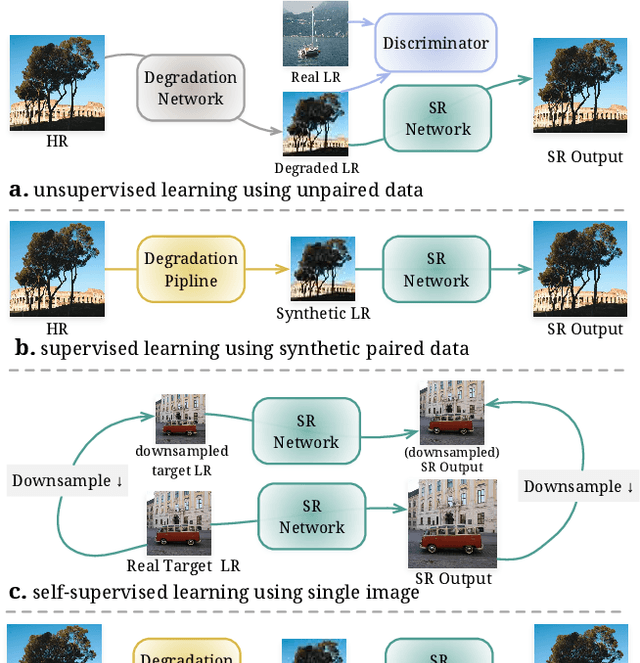

For image super-resolution (SR), bridging the gap between the performance on synthetic datasets and real-world degradation scenarios remains a challenge. This work introduces a novel "Low-Res Leads the Way" (LWay) training framework, merging Supervised Pre-training with Self-supervised Learning to enhance the adaptability of SR models to real-world images. Our approach utilizes a low-resolution (LR) reconstruction network to extract degradation embeddings from LR images, merging them with super-resolved outputs for LR reconstruction. Leveraging unseen LR images for self-supervised learning guides the model to adapt its modeling space to the target domain, facilitating fine-tuning of SR models without requiring paired high-resolution (HR) images. The integration of Discrete Wavelet Transform (DWT) further refines the focus on high-frequency details. Extensive evaluations show that our method significantly improves the generalization and detail restoration capabilities of SR models on unseen real-world datasets, outperforming existing methods. Our training regime is universally compatible, requiring no network architecture modifications, making it a practical solution for real-world SR applications.
CoSeR: Bridging Image and Language for Cognitive Super-Resolution
Dec 02, 2023Existing super-resolution (SR) models primarily focus on restoring local texture details, often neglecting the global semantic information within the scene. This oversight can lead to the omission of crucial semantic details or the introduction of inaccurate textures during the recovery process. In our work, we introduce the Cognitive Super-Resolution (CoSeR) framework, empowering SR models with the capacity to comprehend low-resolution images. We achieve this by marrying image appearance and language understanding to generate a cognitive embedding, which not only activates prior information from large text-to-image diffusion models but also facilitates the generation of high-quality reference images to optimize the SR process. To further improve image fidelity, we propose a novel condition injection scheme called "All-in-Attention", consolidating all conditional information into a single module. Consequently, our method successfully restores semantically correct and photorealistic details, demonstrating state-of-the-art performance across multiple benchmarks. Code: https://github.com/VINHYU/CoSeR
AsConvSR: Fast and Lightweight Super-Resolution Network with Assembled Convolutions
May 05, 2023



In recent years, videos and images in 720p (HD), 1080p (FHD) and 4K (UHD) resolution have become more popular for display devices such as TVs, mobile phones and VR. However, these high resolution images cannot achieve the expected visual effect due to the limitation of the internet bandwidth, and bring a great challenge for super-resolution networks to achieve real-time performance. Following this challenge, we explore multiple efficient network designs, such as pixel-unshuffle, repeat upscaling, and local skip connection removal, and propose a fast and lightweight super-resolution network. Furthermore, by analyzing the applications of the idea of divide-and-conquer in super-resolution, we propose assembled convolutions which can adapt convolution kernels according to the input features. Experiments suggest that our method outperforms all the state-of-the-art efficient super-resolution models, and achieves optimal results in terms of runtime and quality. In addition, our method also wins the first place in NTIRE 2023 Real-Time Super-Resolution - Track 1 ($\times$2). The code will be available at https://gitee.com/mindspore/models/tree/master/research/cv/AsConvSR
A Codec Information Assisted Framework for Efficient Compressed Video Super-Resolution
Oct 15, 2022

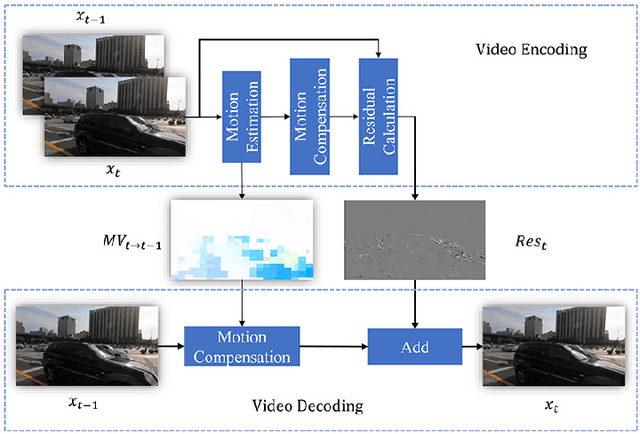
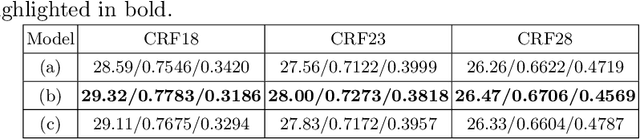
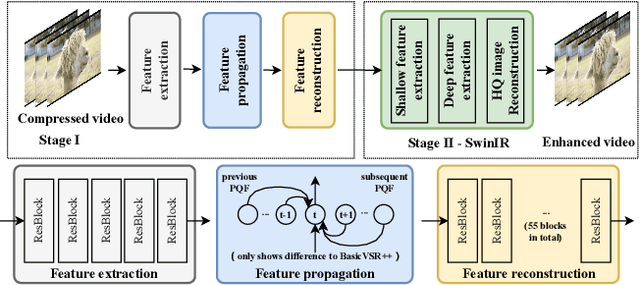
Online processing of compressed videos to increase their resolutions attracts increasing and broad attention. Video Super-Resolution (VSR) using recurrent neural network architecture is a promising solution due to its efficient modeling of long-range temporal dependencies. However, state-of-the-art recurrent VSR models still require significant computation to obtain a good performance, mainly because of the complicated motion estimation for frame/feature alignment and the redundant processing of consecutive video frames. In this paper, considering the characteristics of compressed videos, we propose a Codec Information Assisted Framework (CIAF) to boost and accelerate recurrent VSR models for compressed videos. Firstly, the framework reuses the coded video information of Motion Vectors to model the temporal relationships between adjacent frames. Experiments demonstrate that the models with Motion Vector based alignment can significantly boost the performance with negligible additional computation, even comparable to those using more complex optical flow based alignment. Secondly, by further making use of the coded video information of Residuals, the framework can be informed to skip the computation on redundant pixels. Experiments demonstrate that the proposed framework can save up to 70% of the computation without performance drop on the REDS4 test videos encoded by H.264 when CRF is 23.
AIM 2022 Challenge on Super-Resolution of Compressed Image and Video: Dataset, Methods and Results
Aug 25, 2022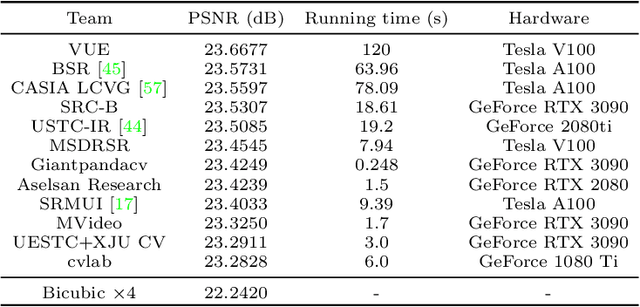

This paper reviews the Challenge on Super-Resolution of Compressed Image and Video at AIM 2022. This challenge includes two tracks. Track 1 aims at the super-resolution of compressed image, and Track~2 targets the super-resolution of compressed video. In Track 1, we use the popular dataset DIV2K as the training, validation and test sets. In Track 2, we propose the LDV 3.0 dataset, which contains 365 videos, including the LDV 2.0 dataset (335 videos) and 30 additional videos. In this challenge, there are 12 teams and 2 teams that submitted the final results to Track 1 and Track 2, respectively. The proposed methods and solutions gauge the state-of-the-art of super-resolution on compressed image and video. The proposed LDV 3.0 dataset is available at https://github.com/RenYang-home/LDV_dataset. The homepage of this challenge is at https://github.com/RenYang-home/AIM22_CompressSR.
Adaptive Local Implicit Image Function for Arbitrary-scale Super-resolution
Aug 07, 2022



Image representation is critical for many visual tasks. Instead of representing images discretely with 2D arrays of pixels, a recent study, namely local implicit image function (LIIF), denotes images as a continuous function where pixel values are expansion by using the corresponding coordinates as inputs. Due to its continuous nature, LIIF can be adopted for arbitrary-scale image super-resolution tasks, resulting in a single effective and efficient model for various up-scaling factors. However, LIIF often suffers from structural distortions and ringing artifacts around edges, mostly because all pixels share the same model, thus ignoring the local properties of the image. In this paper, we propose a novel adaptive local image function (A-LIIF) to alleviate this problem. Specifically, our A-LIIF consists of two main components: an encoder and a expansion network. The former captures cross-scale image features, while the latter models the continuous up-scaling function by a weighted combination of multiple local implicit image functions. Accordingly, our A-LIIF can reconstruct the high-frequency textures and structures more accurately. Experiments on multiple benchmark datasets verify the effectiveness of our method. Our codes are available at \url{https://github.com/LeeHW-THU/A-LIIF}.
Unsupervised Flow-Aligned Sequence-to-Sequence Learning for Video Restoration
May 20, 2022
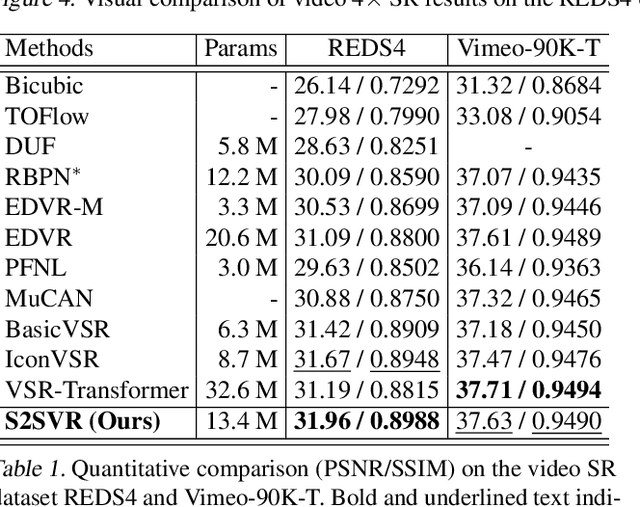
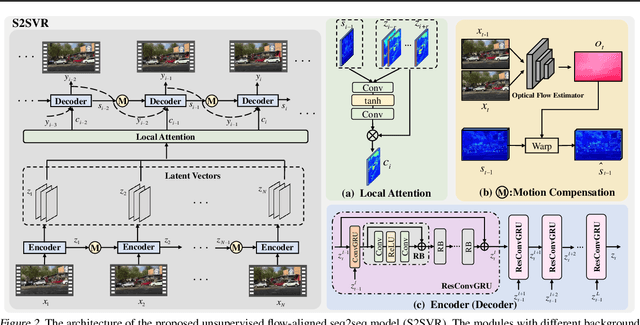
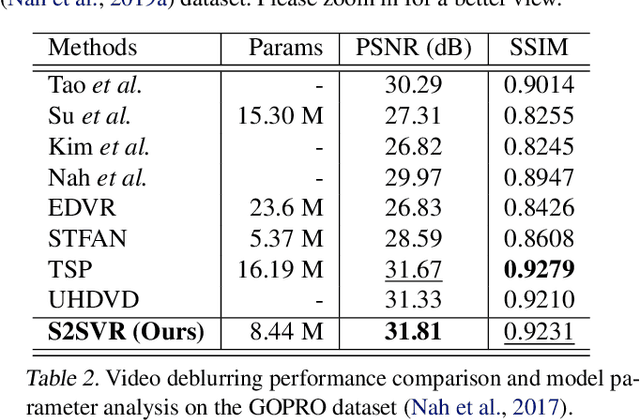
How to properly model the inter-frame relation within the video sequence is an important but unsolved challenge for video restoration (VR). In this work, we propose an unsupervised flow-aligned sequence-to-sequence model (S2SVR) to address this problem. On the one hand, the sequence-to-sequence model, which has proven capable of sequence modeling in the field of natural language processing, is explored for the first time in VR. Optimized serialization modeling shows potential in capturing long-range dependencies among frames. On the other hand, we equip the sequence-to-sequence model with an unsupervised optical flow estimator to maximize its potential. The flow estimator is trained with our proposed unsupervised distillation loss, which can alleviate the data discrepancy and inaccurate degraded optical flow issues of previous flow-based methods. With reliable optical flow, we can establish accurate correspondence among multiple frames, narrowing the domain difference between 1D language and 2D misaligned frames and improving the potential of the sequence-to-sequence model. S2SVR shows superior performance in multiple VR tasks, including video deblurring, video super-resolution, and compressed video quality enhancement. Code and models are publicly available at https://github.com/linjing7/VR-Baseline
NTIRE 2022 Challenge on Super-Resolution and Quality Enhancement of Compressed Video: Dataset, Methods and Results
Apr 25, 2022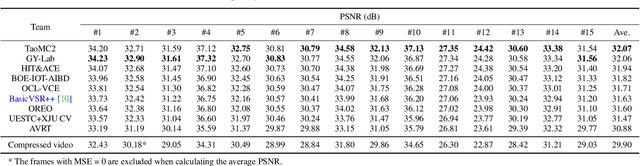
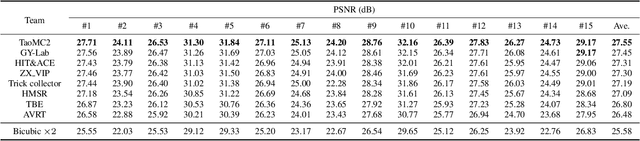

This paper reviews the NTIRE 2022 Challenge on Super-Resolution and Quality Enhancement of Compressed Video. In this challenge, we proposed the LDV 2.0 dataset, which includes the LDV dataset (240 videos) and 95 additional videos. This challenge includes three tracks. Track 1 aims at enhancing the videos compressed by HEVC at a fixed QP. Track 2 and Track 3 target both the super-resolution and quality enhancement of HEVC compressed video. They require x2 and x4 super-resolution, respectively. The three tracks totally attract more than 600 registrations. In the test phase, 8 teams, 8 teams and 12 teams submitted the final results to Tracks 1, 2 and 3, respectively. The proposed methods and solutions gauge the state-of-the-art of super-resolution and quality enhancement of compressed video. The proposed LDV 2.0 dataset is available at https://github.com/RenYang-home/LDV_dataset. The homepage of this challenge (including open-sourced codes) is at https://github.com/RenYang-home/NTIRE22_VEnh_SR.
Flow-Guided Sparse Transformer for Video Deblurring
Jan 06, 2022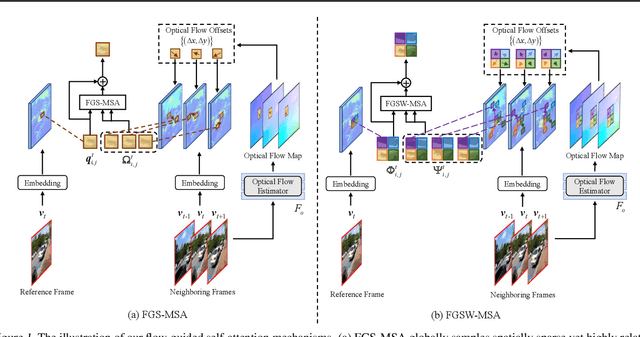
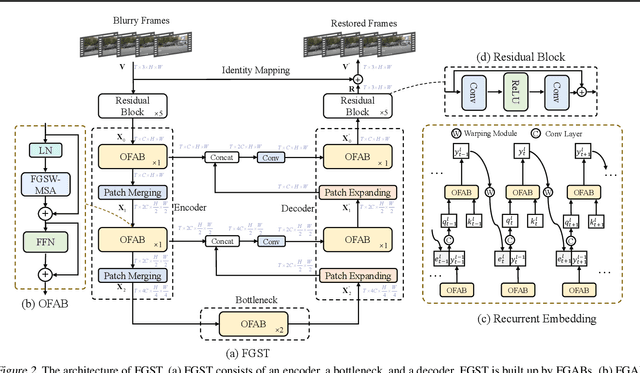

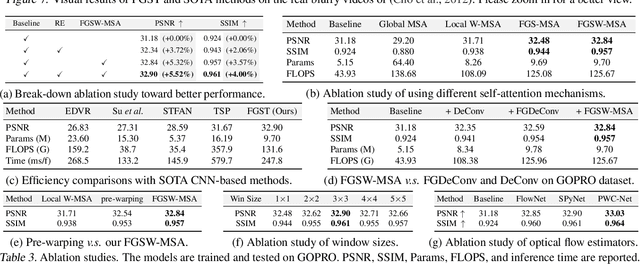
Exploiting similar and sharper scene patches in spatio-temporal neighborhoods is critical for video deblurring. However, CNN-based methods show limitations in capturing long-range dependencies and modeling non-local self-similarity. In this paper, we propose a novel framework, Flow-Guided Sparse Transformer (FGST), for video deblurring. In FGST, we customize a self-attention module, Flow-Guided Sparse Window-based Multi-head Self-Attention (FGSW-MSA). For each $query$ element on the blurry reference frame, FGSW-MSA enjoys the guidance of the estimated optical flow to globally sample spatially sparse yet highly related $key$ elements corresponding to the same scene patch in neighboring frames. Besides, we present a Recurrent Embedding (RE) mechanism to transfer information from past frames and strengthen long-range temporal dependencies. Comprehensive experiments demonstrate that our proposed FGST outperforms state-of-the-art (SOTA) methods on both DVD and GOPRO datasets and even yields more visually pleasing results in real video deblurring. Code and models will be released to the public.
Locally Adaptive Structure and Texture Similarity for Image Quality Assessment
Oct 16, 2021



The latest advances in full-reference image quality assessment (IQA) involve unifying structure and texture similarity based on deep representations. The resulting Deep Image Structure and Texture Similarity (DISTS) metric, however, makes rather global quality measurements, ignoring the fact that natural photographic images are locally structured and textured across space and scale. In this paper, we describe a locally adaptive structure and texture similarity index for full-reference IQA, which we term A-DISTS. Specifically, we rely on a single statistical feature, namely the dispersion index, to localize texture regions at different scales. The estimated probability (of one patch being texture) is in turn used to adaptively pool local structure and texture measurements. The resulting A-DISTS is adapted to local image content, and is free of expensive human perceptual scores for supervised training. We demonstrate the advantages of A-DISTS in terms of correlation with human data on ten IQA databases and optimization of single image super-resolution methods.