 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRRNet: Configurable Real-Time Video Enhancement with Arbitrary Local Lighting Variations
Jan 05, 2026With the growing demand for real-time video enhancement in live applications, existing methods often struggle to balance speed and effective exposure control, particularly under uneven lighting. We introduce RRNet (Rendering Relighting Network), a lightweight and configurable framework that achieves a state-of-the-art tradeoff between visual quality and efficiency. By estimating parameters for a minimal set of virtual light sources, RRNet enables localized relighting through a depth-aware rendering module without requiring pixel-aligned training data. This object-aware formulation preserves facial identity and supports real-time, high-resolution performance using a streamlined encoder and lightweight prediction head. To facilitate training, we propose a generative AI-based dataset creation pipeline that synthesizes diverse lighting conditions at low cost. With its interpretable lighting control and efficient architecture, RRNet is well suited for practical applications such as video conferencing, AR-based portrait enhancement, and mobile photography. Experiments show that RRNet consistently outperforms prior methods in low-light enhancement, localized illumination adjustment, and glare removal.
VideoGen: A Reference-Guided Latent Diffusion Approach for High Definition Text-to-Video Generation
Sep 07, 2023



In this paper, we present VideoGen, a text-to-video generation approach, which can generate a high-definition video with high frame fidelity and strong temporal consistency using reference-guided latent diffusion. We leverage an off-the-shelf text-to-image generation model, e.g., Stable Diffusion, to generate an image with high content quality from the text prompt, as a reference image to guide video generation. Then, we introduce an efficient cascaded latent diffusion module conditioned on both the reference image and the text prompt, for generating latent video representations, followed by a flow-based temporal upsampling step to improve the temporal resolution. Finally, we map latent video representations into a high-definition video through an enhanced video decoder. During training, we use the first frame of a ground-truth video as the reference image for training the cascaded latent diffusion module. The main characterises of our approach include: the reference image generated by the text-to-image model improves the visual fidelity; using it as the condition makes the diffusion model focus more on learning the video dynamics; and the video decoder is trained over unlabeled video data, thus benefiting from high-quality easily-available videos. VideoGen sets a new state-of-the-art in text-to-video generation in terms of both qualitative and quantitative evaluation. See \url{https://videogen.github.io/VideoGen/} for more samples.
AIM 2022 Challenge on Super-Resolution of Compressed Image and Video: Dataset, Methods and Results
Aug 25, 2022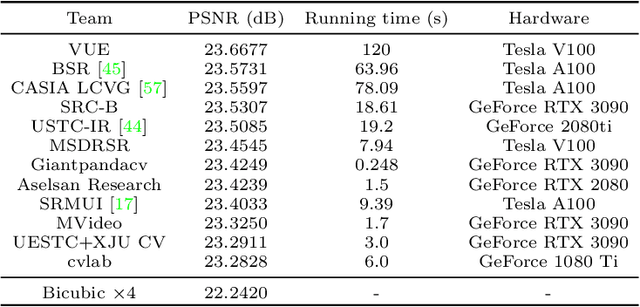
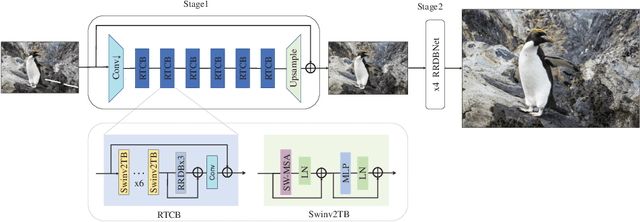

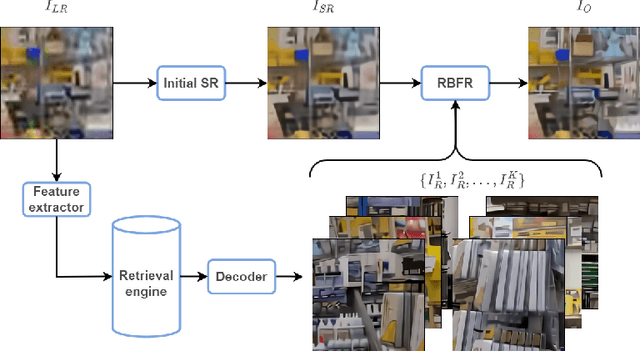
This paper reviews the Challenge on Super-Resolution of Compressed Image and Video at AIM 2022. This challenge includes two tracks. Track 1 aims at the super-resolution of compressed image, and Track~2 targets the super-resolution of compressed video. In Track 1, we use the popular dataset DIV2K as the training, validation and test sets. In Track 2, we propose the LDV 3.0 dataset, which contains 365 videos, including the LDV 2.0 dataset (335 videos) and 30 additional videos. In this challenge, there are 12 teams and 2 teams that submitted the final results to Track 1 and Track 2, respectively. The proposed methods and solutions gauge the state-of-the-art of super-resolution on compressed image and video. The proposed LDV 3.0 dataset is available at https://github.com/RenYang-home/LDV_dataset. The homepage of this challenge is at https://github.com/RenYang-home/AIM22_CompressSR.
Task Modifiers for HTN Planning and Acting
Feb 09, 2022
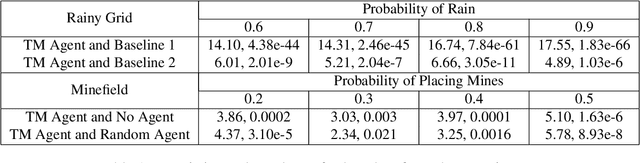
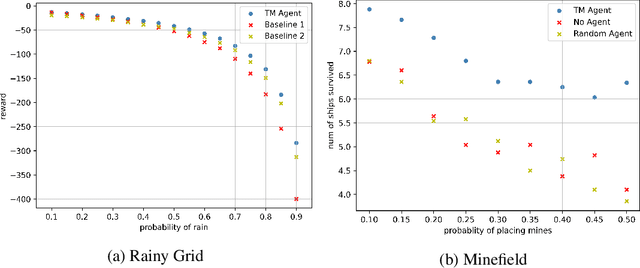
The ability of an agent to change its objectives in response to unexpected events is desirable in dynamic environments. In order to provide this capability to hierarchical task network (HTN) planning, we propose an extension of the paradigm called task modifiers, which are functions that receive a task list and a state and produce a new task list. We focus on a particular type of problems in which planning and execution are interleaved and the ability to handle exogenous events is crucial. To determine the efficacy of this approach, we evaluate the performance of our task modifier implementation in two environments, one of which is a simulation that differs substantially from traditional HTN domains.
Hierarchical Reinforcement Learning for Deep Goal Reasoning: An Expressiveness Analysis
Jun 21, 2020
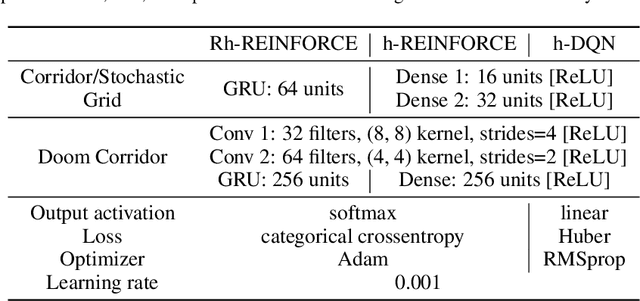
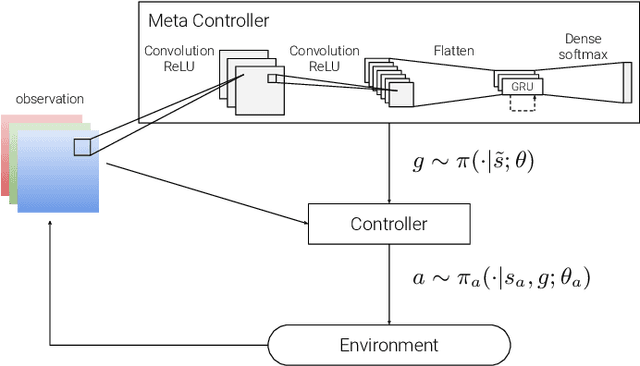
Hierarchical DQN (h-DQN) is a two-level architecture of feedforward neural networks where the meta level selects goals and the lower level takes actions to achieve the goals. We show tasks that cannot be solved by h-DQN, exemplifying the limitation of this type of hierarchical framework (HF). We describe the recurrent hierarchical framework (RHF), generalizing architectures that use a recurrent neural network at the meta level. We analyze the expressiveness of HF and RHF using context-sensitive grammars. We show that RHF is more expressive than HF. We perform experiments comparing an implementation of RHF with two HF baselines; the results corroborate our theoretical findings.
A Layered Architecture for Active Perception: Image Classification using Deep Reinforcement Learning
Sep 20, 2019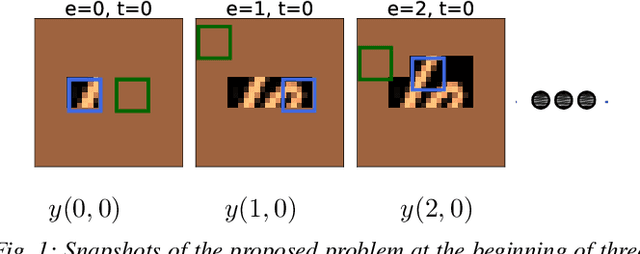
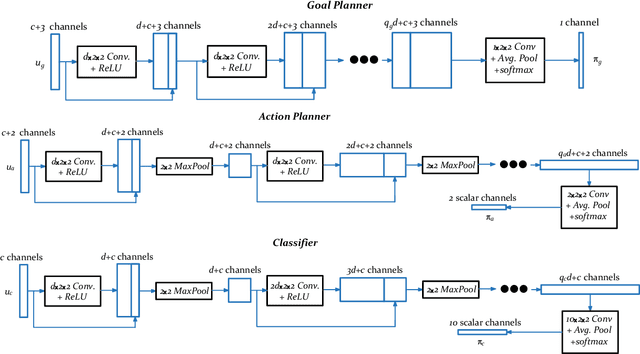

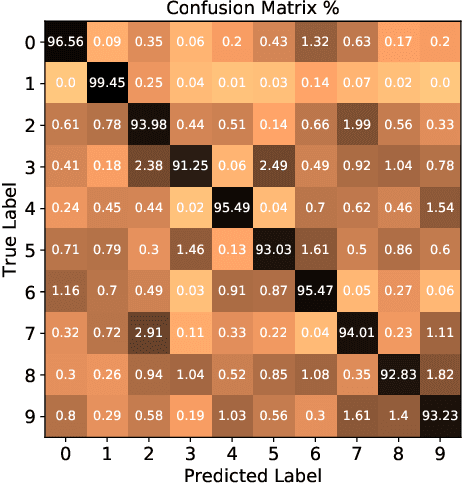
We propose a planning and perception mechanism for a robot (agent), that can only observe the underlying environment partially, in order to solve an image classification problem. A three-layer architecture is suggested that consists of a meta-layer that decides the intermediate goals, an action-layer that selects local actions as the agent navigates towards a goal, and a classification-layer that evaluates the reward and makes a prediction. We design and implement these layers using deep reinforcement learning. A generalized policy gradient algorithm is utilized to learn the parameters of these layers to maximize the expected reward. Our proposed methodology is tested on the MNIST dataset of handwritten digits, which provides us with a level of explainability while interpreting the agent's intermediate goals and course of action.