 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-Agent Next-Best-View Optimization for Risk-Averse Planning
Jun 02, 2026Multi-agent Next-Best-View (NBV) selection for safe path planning in uncertain and unknown environments requires informative, safety-aware, and efficient coordination. Centralized approaches rely on sharing raw sensor data or significant communication overhead, resulting in limited scalability. We propose a distributed, risk-aware multi-agent NBV framework in which each robot maintains a private local 3D Gaussian Splatting map and the team jointly maximizes expected information gain (EIG) restricted to masked zones along planned trajectories. The resulting distributed objective is solved by Consensus ADMM (C-ADMM) over a communication graph, with each robot exchanging only candidate viewpoints, planned trajectory descriptors, and scalar EIG contributions. Collision risk along each trajectory is modeled via Average Value-at-Risk (AV@R) over the local 3DGS map and used both to shape the masking radius and to score planned paths. Experiments in Gibson environments at multiple team sizes show that the distributed formulation approaches the centralized baseline in mapping quality and trajectory safety while reducing communication by orders of magnitude.
ChannelAgent-Empowered Electromagnetic Space World Model: A Case Study on Agent-Driven Channel Generation for 6G AI-Native Air Interface
May 14, 2026As sixth-generation (6G) wireless networks evolve toward increasingly heterogeneous scenarios, tasks, and service requirements, conventional artificial intelligence (AI) models remain limited in task-aware decision-making and autonomous adaptation. To address this issue, this paper first proposes a ChannelAgent-empowered electromagnetic space world model, in which wireless intelligence is organized into a closed-loop process consisting of multi-modal sensing, ChannelAgent as the intelligent core, and execution with feedback update. As a case study, agent-driven channel generation is instantiated through path loss prediction. Specifically, a task-oriented intelligent feature selection mechanism is designed by integrating reinforcement-learning-inspired policy adaptation with evolutionary search, enabling the agent to iteratively derive compact and task-suitable feature subsets according to the current scenario and performance feedback. Simulation results demonstrate superior performance in both single-scenario and multi-scenario tasks, highlighting the potential of the proposed model for autonomous, adaptive, task-oriented, and closed-loop wireless intelligence.
Paradigm Shift from Statistical Channel Modeling to Digital Twin Prediction: An Environment-Generalizable ChannelLM for 6G AI-enabled Air Interface
Apr 20, 2026As 6G advances, ubiquitous connectivity and higher capacity requirements of the air interface pose substantial challenges for accurate and real-time wireless channel acquisition in diverse environments. Conventional statistical channel modeling relies on offline measurement data from limited environments, struggling to support online applications facing diverse environments. To this end, the digital twin channel (DTC) has emerged as a novel paradigm that constructs a digital replica of the physical environment through high-fidelity sensing and predicts corresponding channel in real time utilizing artificial intelligence (AI) models. As the engine of DTC, existing AI models struggle to simultaneously achieve strong environmental generalization in real-world and end-to-end channel prediction for real time tasks. Therefore, this paper proposes a channel large model (ChannelLM)-driven DTC architecture comprising three modules: low-complexity and high-accuracy environment reconstruction based on dynamic object detection and multimodal alignment of image and point cloud data, physically interpretable environment feature extraction, and a ChannelLM core to mapping these features into generalized environment representations for multi-task channel prediction. Simulation results demonstrate that, in unseen test environments, compared with small-scale AI models, ChannelLM reduces prediction errors by 4.23 dB in channel state information prediction while achieving an end-to-end inference latency of 70 milliseconds in the real world.
UI-Copilot: Advancing Long-Horizon GUI Automation via Tool-Integrated Policy Optimization
Apr 15, 2026MLLM-based GUI agents have demonstrated strong capabilities in complex user interface interaction tasks. However, long-horizon scenarios remain challenging, as these agents are burdened with tasks beyond their intrinsic capabilities, suffering from memory degradation, progress confusion, and math hallucination. To address these challenges, we present UI-Copilot, a collaborative framework where the GUI agent focuses on task execution while a lightweight copilot provides on-demand assistance for memory retrieval and numerical computation. We introduce memory decoupling to separate persistent observations from transient execution context, and train the policy agent to selectively invoke the copilot as Retriever or Calculator based on task demands. To enable effective tool invocation learning, we propose Tool-Integrated Policy Optimization (TIPO), which separately optimizes tool selection through single-turn prediction and task execution through on-policy multi-turn rollouts. Experimental results show that UI-Copilot-7B achieves state-of-the-art performance on challenging MemGUI-Bench, outperforming strong 7B-scale GUI agents such as GUI-Owl-7B and UI-TARS-1.5-7B. Moreover, UI-Copilot-7B delivers a 17.1% absolute improvement on AndroidWorld over the base Qwen model, highlighting UI-Copilot's strong generalization to real-world GUI tasks.
World Reasoning Arena
Mar 26, 2026World models (WMs) are intended to serve as internal simulators of the real world that enable agents to understand, anticipate, and act upon complex environments. Existing WM benchmarks remain narrowly focused on next-state prediction and visual fidelity, overlooking the richer simulation capabilities required for intelligent behavior. To address this gap, we introduce WR-Arena, a comprehensive benchmark for evaluating WMs along three fundamental dimensions of next world simulation: (i) Action Simulation Fidelity, the ability to interpret and follow semantically meaningful, multi-step instructions and generate diverse counterfactual rollouts; (ii) Long-horizon Forecast, the ability to sustain accurate, coherent, and physically plausible simulations across extended interactions; and (iii) Simulative Reasoning and Planning, the ability to support goal-directed reasoning by simulating, comparing, and selecting among alternative futures in both structured and open-ended environments. We build a task taxonomy and curate diverse datasets designed to probe these capabilities, moving beyond single-turn and perceptual evaluations. Through extensive experiments with state-of-the-art WMs, our results expose a substantial gap between current models and human-level hypothetical reasoning, and establish WR-Arena as both a diagnostic tool and a guideline for advancing next-generation world models capable of robust understanding, forecasting, and purposeful action. The code is available at https://github.com/MBZUAI-IFM/WR-Arena.
MAS-on-the-Fly: Dynamic Adaptation of LLM-based Multi-Agent Systems at Test Time
Feb 14, 2026Large Language Model (LLM)-based multi-agent systems (MAS) have emerged as a promising paradigm for solving complex tasks. However, existing works often rely on manual designs or "one-size-fits-all" automation, lacking dynamic adaptability after deployment. Inspired by how biological systems adapt, we introduce MASFly, a novel multi-agent framework enabling dynamic adaptation at test time. To adapt system generation, MASFly employs a retrieval-augmented SOP instantiation mechanism that leverages a self-constructed repository of successful collaboration patterns, enabling the LLM to assemble customized MASs for new queries. For adaptive execution, MASFly incorporates an experience-guided supervision mechanism, where a dedicated Watcher agent monitors system behaviors with reference to a personalized experience pool and provides real-time interventions. Extensive experiments demonstrate that MASFly achieves state-of-the-art performance, most notably a 61.7% success rate on the TravelPlanner benchmark, while exhibiting strong task adaptability and robustness.
A Tutorial on 3GPP Rel-19 Channel Modeling for 6G FR3 (7-24 GHz): From Standard Specification to Simulation Implementation
Feb 07, 2026The upper-mid band (7-24 GHz), designated as Frequency Range 3 (FR3), has emerged as a definitive ``golden band" for 6G networks, strategically balancing the wide coverage of sub-6 GHz with the high capacity of mmWave. To compensate for the severe path loss inherent to this band, the deployment of Extremely Large Aperture Arrays (ELAA) is indispensable. However, the legacy 3GPP TR 38.901 channel model faces critical validity challenges when applied to 6G FR3, stemming from both the distinct propagation characteristics of this frequency band and the fundamental physical paradigm shift induced by ELAA. In response, 3GPP Release 19 (Rel-19) has validated the model through extensive new measurements and introduced significant enhancements. This tutorial provides a comprehensive guide to the Rel-19 channel model for 6G FR3, bridging the gap between standardization specifications and practical simulation implementation. First, we provide a high-level overview of the fundamental principles of the 3GPP channel modeling framework. Second, we detail the specific enhancements and modifications introduced in Rel-19, including the rationale behind the new Suburban Macro (SMa) scenario, the mathematical modeling of ELAA-driven features such as near-field and spatial non-stationarity, and the recalibration of large-scale parameters. Overall, this tutorial serves as an essential guide for researchers and engineers to master the latest 3GPP channel modeling methodology, laying a solid foundation for the accurate design and performance evaluation of future 6G FR3 networks.
PAN: A World Model for General, Interactable, and Long-Horizon World Simulation
Nov 15, 2025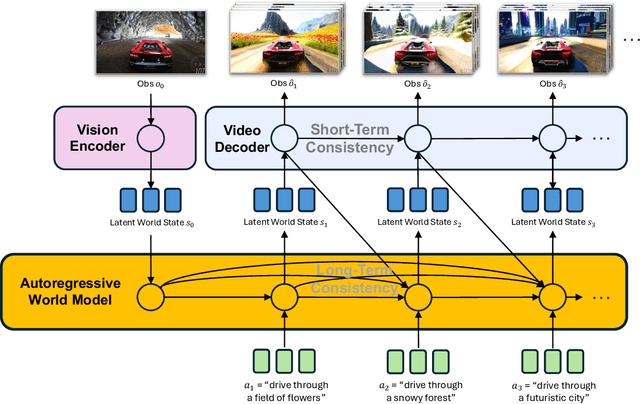
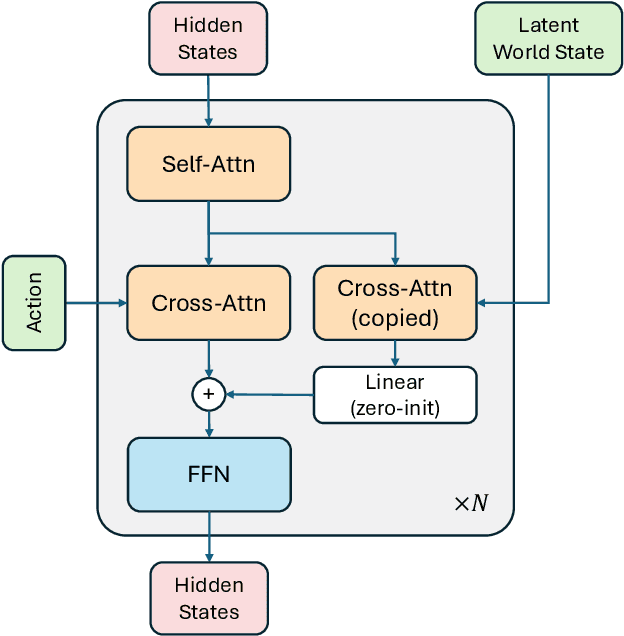
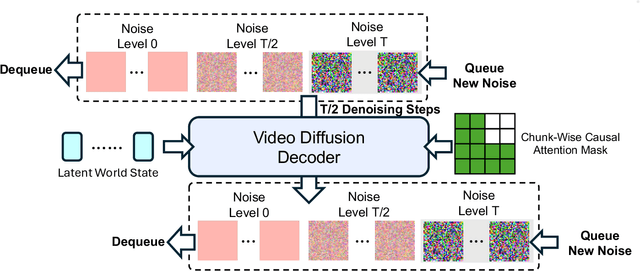
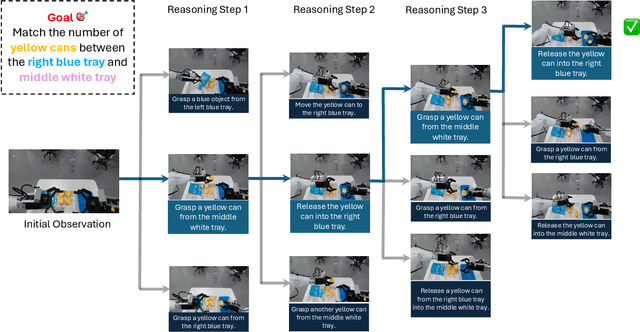
A world model enables an intelligent agent to imagine, predict, and reason about how the world evolves in response to its actions, and accordingly to plan and strategize. While recent video generation models produce realistic visual sequences, they typically operate in the prompt-to-full-video manner without causal control, interactivity, or long-horizon consistency required for purposeful reasoning. Existing world modeling efforts, on the other hand, often focus on restricted domains (e.g., physical, game, or 3D-scene dynamics) with limited depth and controllability, and struggle to generalize across diverse environments and interaction formats. In this work, we introduce PAN, a general, interactable, and long-horizon world model that predicts future world states through high-quality video simulation conditioned on history and natural language actions. PAN employs the Generative Latent Prediction (GLP) architecture that combines an autoregressive latent dynamics backbone based on a large language model (LLM), which grounds simulation in extensive text-based knowledge and enables conditioning on language-specified actions, with a video diffusion decoder that reconstructs perceptually detailed and temporally coherent visual observations, to achieve a unification between latent space reasoning (imagination) and realizable world dynamics (reality). Trained on large-scale video-action pairs spanning diverse domains, PAN supports open-domain, action-conditioned simulation with coherent, long-term dynamics. Extensive experiments show that PAN achieves strong performance in action-conditioned world simulation, long-horizon forecasting, and simulative reasoning compared to other video generators and world models, taking a step towards general world models that enable predictive simulation of future world states for reasoning and acting.
A Novel Multi-Reference-Point Modeling Framework for Monostatic Background Channel: Toward 3GPP ISAC Standardization
Nov 05, 2025Integrated Sensing and Communication (ISAC) has been identified as a key 6G application by ITU and 3GPP. A realistic, standard-compatible channel model is essential for ISAC system design. To characterize the impact of Sensing Targets (STs), 3GPP defines ISAC channel as a combination of target and background channels, comprising multipath components related to STs and those originating solely from the environment, respectively. Although the background channel does not carry direct ST information, its accurate modeling is critical for evaluating sensing performance, especially in complex environments. Existing communication standards characterize propagation between separated transmitter (Tx) and receiver (Rx). However, modeling background channels in the ISAC monostatic mode, where the Tx and Rx are co-located, remains a pressing challenge. In this paper, we firstly conduct ISAC monostatic background channel measurements for an indoor scenario at 28 GHz. Realistic channel parameters are extracted, revealing pronounced single-hop propagation and discrete multipath distribution. Inspired by these properties, a novel stochastic model is proposed to characterizing the ISAC monostatic background channel as the superposition of sub-channels between the monostatic Tx&Rx and multiple communication Rx-like Reference Points (RPs). This model is compatible with standardizations, and a 3GPP-extended implementation framework is introduced. Finally, a genetic algorithm-based method is proposed to extract the optimal number and placement of multi-RPs. The optimization approach and modeling framework are validated by comparing measured and simulated channel parameters. Results demonstrate that the proposed model effectively captures monostatic background channel characteristics, addresses a critical gap in ISAC channel modeling, and supports 6G standardization.
Character Mixing for Video Generation
Oct 06, 2025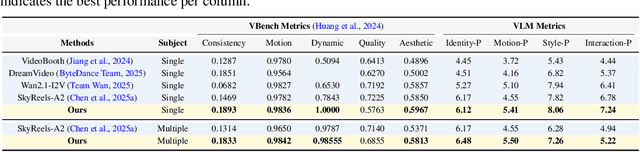


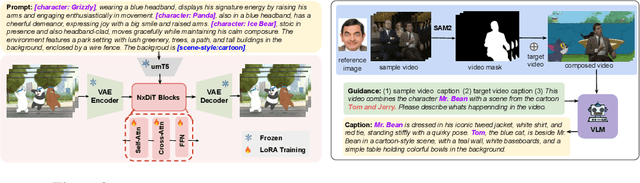
Imagine Mr. Bean stepping into Tom and Jerry--can we generate videos where characters interact naturally across different worlds? We study inter-character interaction in text-to-video generation, where the key challenge is to preserve each character's identity and behaviors while enabling coherent cross-context interaction. This is difficult because characters may never have coexisted and because mixing styles often causes style delusion, where realistic characters appear cartoonish or vice versa. We introduce a framework that tackles these issues with Cross-Character Embedding (CCE), which learns identity and behavioral logic across multimodal sources, and Cross-Character Augmentation (CCA), which enriches training with synthetic co-existence and mixed-style data. Together, these techniques allow natural interactions between previously uncoexistent characters without losing stylistic fidelity. Experiments on a curated benchmark of cartoons and live-action series with 10 characters show clear improvements in identity preservation, interaction quality, and robustness to style delusion, enabling new forms of generative storytelling.Additional results and videos are available on our project page: https://tingtingliao.github.io/mimix/.