 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeERNIE 5.0 Technical Report
Feb 04, 2026In this report, we introduce ERNIE 5.0, a natively autoregressive foundation model desinged for unified multimodal understanding and generation across text, image, video, and audio. All modalities are trained from scratch under a unified next-group-of-tokens prediction objective, based on an ultra-sparse mixture-of-experts (MoE) architecture with modality-agnostic expert routing. To address practical challenges in large-scale deployment under diverse resource constraints, ERNIE 5.0 adopts a novel elastic training paradigm. Within a single pre-training run, the model learns a family of sub-models with varying depths, expert capacities, and routing sparsity, enabling flexible trade-offs among performance, model size, and inference latency in memory- or time-constrained scenarios. Moreover, we systematically address the challenges of scaling reinforcement learning to unified foundation models, thereby guaranteeing efficient and stable post-training under ultra-sparse MoE architectures and diverse multimodal settings. Extensive experiments demonstrate that ERNIE 5.0 achieves strong and balanced performance across multiple modalities. To the best of our knowledge, among publicly disclosed models, ERNIE 5.0 represents the first production-scale realization of a trillion-parameter unified autoregressive model that supports both multimodal understanding and generation. To facilitate further research, we present detailed visualizations of modality-agnostic expert routing in the unified model, alongside comprehensive empirical analysis of elastic training, aiming to offer profound insights to the community.
Analyzing and Improving Diffusion Models for Time-Series Data Imputation: A Proximal Recursion Perspective
Feb 01, 2026Diffusion models (DMs) have shown promise for Time-Series Data Imputation (TSDI); however, their performance remains inconsistent in complex scenarios. We attribute this to two primary obstacles: (1) non-stationary temporal dynamics, which can bias the inference trajectory and lead to outlier-sensitive imputations; and (2) objective inconsistency, since imputation favors accurate pointwise recovery whereas DMs are inherently trained to generate diverse samples. To better understand these issues, we analyze DM-based TSDI process through a proximal-operator perspective and uncover that an implicit Wasserstein distance regularization inherent in the process hinders the model's ability to counteract non-stationarity and dissipative regularizer, thereby amplifying diversity at the expense of fidelity. Building on this insight, we propose a novel framework called SPIRIT (Semi-Proximal Transport Regularized time-series Imputation). Specifically, we introduce entropy-induced Bregman divergence to relax the mass preserving constraint in the Wasserstein distance, formulate the semi-proximal transport (SPT) discrepancy, and theoretically prove the robustness of SPT against non-stationarity. Subsequently, we remove the dissipative structure and derive the complete SPIRIT workflow, with SPT serving as the proximal operator. Extensive experiments demonstrate the effectiveness of the proposed SPIRIT approach.
Rethinking the Flow-Based Gradual Domain Adaption: A Semi-Dual Optimal Transport Perspective
Feb 01, 2026Gradual domain adaptation (GDA) aims to mitigate domain shift by progressively adapting models from the source domain to the target domain via intermediate domains. However, real intermediate domains are often unavailable or ineffective, necessitating the synthesis of intermediate samples. Flow-based models have recently been used for this purpose by interpolating between source and target distributions; however, their training typically relies on sample-based log-likelihood estimation, which can discard useful information and thus degrade GDA performance. The key to addressing this limitation is constructing the intermediate domains via samples directly. To this end, we propose an Entropy-regularized Semi-dual Unbalanced Optimal Transport (E-SUOT) framework to construct intermediate domains. Specifically, we reformulate flow-based GDA as a Lagrangian dual problem and derive an equivalent semi-dual objective that circumvents the need for likelihood estimation. However, the dual problem leads to an unstable min-max training procedure. To alleviate this issue, we further introduce entropy regularization to convert it into a more stable alternative optimization procedure. Based on this, we propose a novel GDA training framework and provide theoretical analysis in terms of stability and generalization. Finally, extensive experiments are conducted to demonstrate the efficacy of the E-SUOT framework.
Deep Time-series Forecasting Needs Kernelized Moment Balancing
Jan 31, 2026Deep time-series forecasting can be formulated as a distribution balancing problem aimed at aligning the distribution of the forecasts and ground truths. According to Imbens' criterion, true distribution balance requires matching the first moments with respect to any balancing function. We demonstrate that existing objectives fail to meet this criterion, as they enforce moment matching only for one or two predefined balancing functions, thus failing to achieve full distribution balance. To address this limitation, we propose direct forecasting with kernelized moment balancing (KMB-DF). Unlike existing objectives, KMB-DF adaptively selects the most informative balancing functions from a reproducing kernel hilbert space (RKHS) to enforce sufficient distribution balancing. We derive a tractable and differentiable objective that enables efficient estimation from empirical samples and seamless integration into gradient-based training pipelines. Extensive experiments across multiple models and datasets show that KMB-DF consistently improves forecasting accuracy and achieves state-of-the-art performance. Code is available at https://anonymous.4open.science/r/KMB-DF-403C.
TransDF: Time-Series Forecasting Needs Transformed Label Alignment
May 23, 2025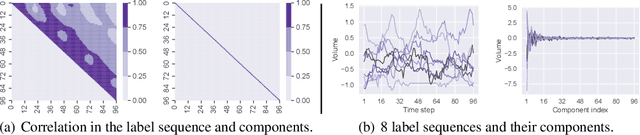
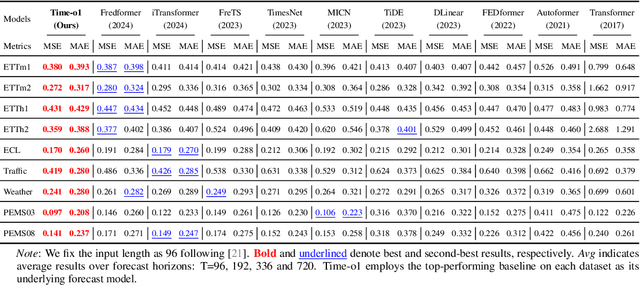
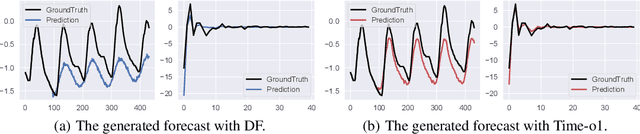
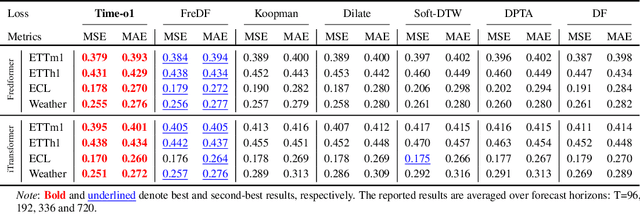
Training time-series forecasting models presents unique challenges in designing effective learning objectives. Existing methods predominantly utilize the temporal mean squared error, which faces two critical challenges: (1) label autocorrelation, which leads to bias from the label sequence likelihood; (2) excessive amount of tasks, which increases with the forecast horizon and complicates optimization. To address these challenges, we propose Transform-enhanced Direct Forecast (TransDF), which transforms the label sequence into decorrelated components with discriminated significance. Models are trained to align the most significant components, thereby effectively mitigating label autocorrelation and reducing task amount. Extensive experiments demonstrate that TransDF achieves state-of-the-art performance and is compatible with various forecasting models. Code is available at https://anonymous.4open.science/r/TransDF-88CF.
Mixture of Low Rank Adaptation with Partial Parameter Sharing for Time Series Forecasting
May 23, 2025Multi-task forecasting has become the standard approach for time-series forecasting (TSF). However, we show that it suffers from an Expressiveness Bottleneck, where predictions at different time steps share the same representation, leading to unavoidable errors even with optimal representations. To address this issue, we propose a two-stage framework: first, pre-train a foundation model for one-step-ahead prediction; then, adapt it using step-specific LoRA modules.This design enables the foundation model to handle any number of forecast steps while avoiding the expressiveness bottleneck. We further introduce the Mixture-of-LoRA (MoLA) model, which employs adaptively weighted LoRA experts to achieve partial parameter sharing across steps. This approach enhances both efficiency and forecasting performance by exploiting interdependencies between forecast steps. Experiments show that MoLA significantly improves model expressiveness and outperforms state-of-the-art time-series forecasting methods. Code is available at https://anonymous.4open.science/r/MoLA-BC92.
Image-Goal Navigation Using Refined Feature Guidance and Scene Graph Enhancement
Mar 14, 2025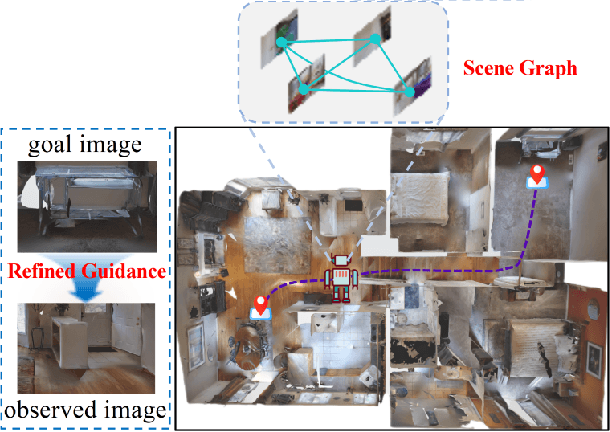
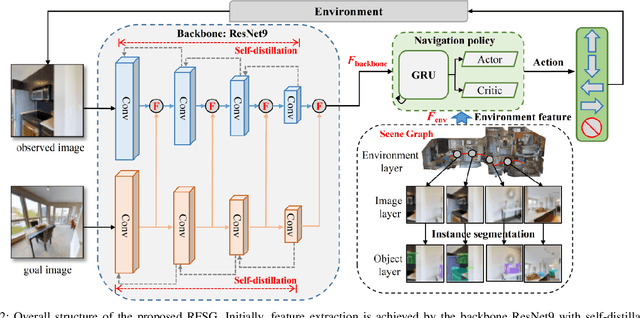
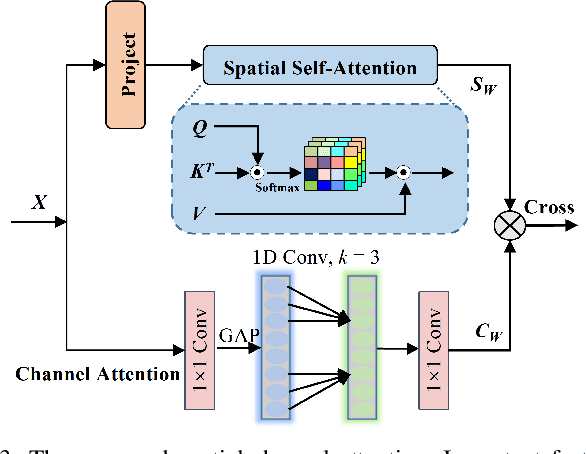
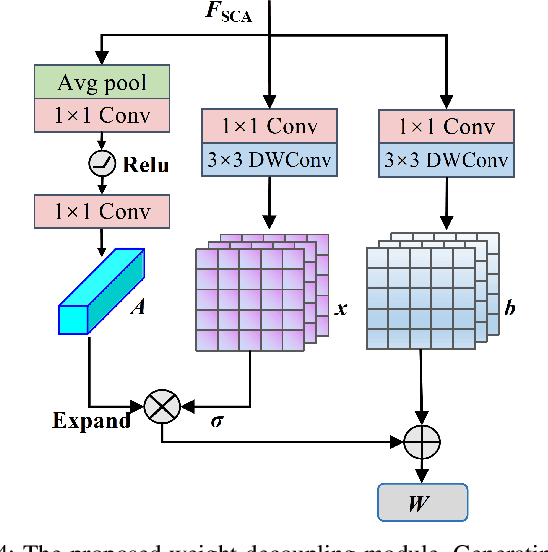
In this paper, we introduce a novel image-goal navigation approach, named RFSG. Our focus lies in leveraging the fine-grained connections between goals, observations, and the environment within limited image data, all the while keeping the navigation architecture simple and lightweight. To this end, we propose the spatial-channel attention mechanism, enabling the network to learn the importance of multi-dimensional features to fuse the goal and observation features. In addition, a selfdistillation mechanism is incorporated to further enhance the feature representation capabilities. Given that the navigation task needs surrounding environmental information for more efficient navigation, we propose an image scene graph to establish feature associations at both the image and object levels, effectively encoding the surrounding scene information. Crossscene performance validation was conducted on the Gibson and HM3D datasets, and the proposed method achieved stateof-the-art results among mainstream methods, with a speed of up to 53.5 frames per second on an RTX3080. This contributes to the realization of end-to-end image-goal navigation in realworld scenarios. The implementation and model of our method have been released at: https://github.com/nubot-nudt/RFSG.
DeepFilter: An Instrumental Baseline for Accurate and Efficient Process Monitoring
Jan 02, 2025



Effective process monitoring is increasingly vital in industrial automation for ensuring operational safety, necessitating both high accuracy and efficiency. Although Transformers have demonstrated success in various fields, their canonical form based on the self-attention mechanism is inadequate for process monitoring due to two primary limitations: (1) the step-wise correlations captured by self-attention mechanism are difficult to capture discriminative patterns in monitoring logs due to the lacking semantics of each step, thus compromising accuracy; (2) the quadratic computational complexity of self-attention hampers efficiency. To address these issues, we propose DeepFilter, a Transformer-style framework for process monitoring. The core innovation is an efficient filtering layer that excel capturing long-term and periodic patterns with reduced complexity. Equipping with the global filtering layer, DeepFilter enhances both accuracy and efficiency, meeting the stringent demands of process monitoring. Experimental results on real-world process monitoring datasets validate DeepFilter's superiority in terms of accuracy and efficiency compared to existing state-of-the-art models.
Proximity Matters: Local Proximity Preserved Balancing for Treatment Effect Estimation
Jul 01, 2024



Heterogeneous treatment effect (HTE) estimation from observational data poses significant challenges due to treatment selection bias. Existing methods address this bias by minimizing distribution discrepancies between treatment groups in latent space, focusing on global alignment. However, the fruitful aspect of local proximity, where similar units exhibit similar outcomes, is often overlooked. In this study, we propose Proximity-aware Counterfactual Regression (PCR) to exploit proximity for representation balancing within the HTE estimation context. Specifically, we introduce a local proximity preservation regularizer based on optimal transport to depict the local proximity in discrepancy calculation. Furthermore, to overcome the curse of dimensionality that renders the estimation of discrepancy ineffective, exacerbated by limited data availability for HTE estimation, we develop an informative subspace projector, which trades off minimal distance precision for improved sample complexity. Extensive experiments demonstrate that PCR accurately matches units across different treatment groups, effectively mitigates treatment selection bias, and significantly outperforms competitors. Code is available at https://anonymous.4open.science/status/ncr-B697.
Rethinking the Diffusion Models for Numerical Tabular Data Imputation from the Perspective of Wasserstein Gradient Flow
Jun 22, 2024



Diffusion models (DMs) have gained attention in Missing Data Imputation (MDI), but there remain two long-neglected issues to be addressed: (1). Inaccurate Imputation, which arises from inherently sample-diversification-pursuing generative process of DMs. (2). Difficult Training, which stems from intricate design required for the mask matrix in model training stage. To address these concerns within the realm of numerical tabular datasets, we introduce a novel principled approach termed Kernelized Negative Entropy-regularized Wasserstein gradient flow Imputation (KnewImp). Specifically, based on Wasserstein gradient flow (WGF) framework, we first prove that issue (1) stems from the cost functionals implicitly maximized in DM-based MDI are equivalent to the MDI's objective plus diversification-promoting non-negative terms. Based on this, we then design a novel cost functional with diversification-discouraging negative entropy and derive our KnewImp approach within WGF framework and reproducing kernel Hilbert space. After that, we prove that the imputation procedure of KnewImp can be derived from another cost functional related to the joint distribution, eliminating the need for the mask matrix and hence naturally addressing issue (2). Extensive experiments demonstrate that our proposed KnewImp approach significantly outperforms existing state-of-the-art methods.