 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Coarse to Fine: Self-Adaptive Hierarchical Planning for LLM Agents
Apr 25, 2026Large language model-based agents have recently emerged as powerful approaches for solving dynamic and multi-step tasks. Most existing agents employ planning mechanisms to guide long-term actions in dynamic environments. However, current planning approaches face a fundamental limitation that they operate at a fixed granularity level. Specifically, they either provide excessive detail for simple tasks or insufficient detail for complex ones, failing to achieve an optimal balance between simplicity and complexity. Drawing inspiration from the principle of \textit{progressive refinement} in cognitive science, we propose \textbf{AdaPlan-H}, a self-adaptive hierarchical planning mechanism that mimics human planning strategies. Our method initiates with a coarse-grained macro plan and progressively refines it based on task complexity. It generates self-adaptive hierarchical plans tailored to the varying difficulty levels of different tasks, which can be optimized by imitation learning and capability enhancement. Experimental results demonstrate that our method significantly improves task execution success rates while mitigating overplanning at the planning level, providing a flexible and efficient solution for multi-step complex decision-making tasks. To contribute to the community, our code and data will be made publicly available at https://github.com/import-myself/AHP.
Towards Adaptive, Scalable, and Robust Coordination of LLM Agents: A Dynamic Ad-Hoc Networking Perspective
Feb 08, 2026Multi-agent architectures built on large language models (LLMs) have demonstrated the potential to realize swarm intelligence through well-crafted collaboration. However, the substantial burden of manual orchestration inherently raises an imperative to automate the design of agentic workflows. We frame such an agent coordination challenge as a classic problem in dynamic ad-hoc networking: How to establish adaptive and reliable communication among a scalable number of agentic hosts? In response to this unresolved dilemma, we introduce RAPS, a reputation-aware publish-subscribe paradigm for adaptive, scalable, and robust coordination of LLM agents. RAPS is grounded in the Distributed Publish-Subscribe Protocol, allowing LLM agents to exchange messages based on their declared intents rather than predefined topologies. Beyond this substrate, RAPS further incorporates two coherent overlays: (i) Reactive Subscription, enabling agents to dynamically refine their intents; and (ii) Bayesian Reputation, empowering each agent with a local watchdog to detect and isolate malicious peers. Extensive experiments over five benchmarks showcase that our design effectively reconciles adaptivity, scalability, and robustness in a unified multi-agent coordination framework.
MALLOC: Benchmarking the Memory-aware Long Sequence Compression for Large Sequential Recommendation
Jan 29, 2026The scaling law, which indicates that model performance improves with increasing dataset and model capacity, has fueled a growing trend in expanding recommendation models in both industry and academia. However, the advent of large-scale recommenders also brings significantly higher computational costs, particularly under the long-sequence dependencies inherent in the user intent of recommendation systems. Current approaches often rely on pre-storing the intermediate states of the past behavior for each user, thereby reducing the quadratic re-computation cost for the following requests. Despite their effectiveness, these methods often treat memory merely as a medium for acceleration, without adequately considering the space overhead it introduces. This presents a critical challenge in real-world recommendation systems with billions of users, each of whom might initiate thousands of interactions and require massive memory for state storage. Fortunately, there have been several memory management strategies examined for compression in LLM, while most have not been evaluated on the recommendation task. To mitigate this gap, we introduce MALLOC, a comprehensive benchmark for memory-aware long sequence compression. MALLOC presents a comprehensive investigation and systematic classification of memory management techniques applicable to large sequential recommendations. These techniques are integrated into state-of-the-art recommenders, enabling a reproducible and accessible evaluation platform. Through extensive experiments across accuracy, efficiency, and complexity, we demonstrate the holistic reliability of MALLOC in advancing large-scale recommendation. Code is available at https://anonymous.4open.science/r/MALLOC.
How Does Personalized Memory Shape LLM Behavior? Benchmarking Rational Preference Utilization in Personalized Assistants
Jan 23, 2026Large language model (LLM)-powered assistants have recently integrated memory mechanisms that record user preferences, leading to more personalized and user-aligned responses. However, irrelevant personalized memories are often introduced into the context, interfering with the LLM's intent understanding. To comprehensively investigate the dual effects of personalization, we develop RPEval, a benchmark comprising a personalized intent reasoning dataset and a multi-granularity evaluation protocol. RPEval reveals the widespread phenomenon of irrational personalization in existing LLMs and, through error pattern analysis, illustrates its negative impact on user experience. Finally, we introduce RP-Reasoner, which treats memory utilization as a pragmatic reasoning process, enabling the selective integration of personalized information. Experimental results demonstrate that our method significantly outperforms carefully designed baselines on RPEval, and resolves 80% of the bad cases observed in a large-scale commercial personalized assistant, highlighting the potential of pragmatic reasoning to mitigate irrational personalization. Our benchmark is publicly available at https://github.com/XueyangFeng/RPEval.
Think Socially via Cognitive Reasoning
Sep 26, 2025LLMs trained for logical reasoning excel at step-by-step deduction to reach verifiable answers. However, this paradigm is ill-suited for navigating social situations, which induce an interpretive process of analyzing ambiguous cues that rarely yield a definitive outcome. To bridge this gap, we introduce Cognitive Reasoning, a paradigm modeled on human social cognition. It formulates the interpretive process into a structured cognitive flow of interconnected cognitive units (e.g., observation or attribution), which combine adaptively to enable effective social thinking and responses. We then propose CogFlow, a complete framework that instills this capability in LLMs. CogFlow first curates a dataset of cognitive flows by simulating the associative and progressive nature of human thought via tree-structured planning. After instilling the basic cognitive reasoning capability via supervised fine-tuning, CogFlow adopts reinforcement learning to enable the model to improve itself via trial and error, guided by a multi-objective reward that optimizes both cognitive flow and response quality. Extensive experiments show that CogFlow effectively enhances the social cognitive capabilities of LLMs, and even humans, leading to more effective social decision-making.
Expectation Confirmation Preference Optimization for Multi-Turn Conversational Recommendation Agent
Jun 17, 2025Recent advancements in Large Language Models (LLMs) have significantly propelled the development of Conversational Recommendation Agents (CRAs). However, these agents often generate short-sighted responses that fail to sustain user guidance and meet expectations. Although preference optimization has proven effective in aligning LLMs with user expectations, it remains costly and performs poorly in multi-turn dialogue. To address this challenge, we introduce a novel multi-turn preference optimization (MTPO) paradigm ECPO, which leverages Expectation Confirmation Theory to explicitly model the evolution of user satisfaction throughout multi-turn dialogues, uncovering the underlying causes of dissatisfaction. These causes can be utilized to support targeted optimization of unsatisfactory responses, thereby achieving turn-level preference optimization. ECPO ingeniously eliminates the significant sampling overhead of existing MTPO methods while ensuring the optimization process drives meaningful improvements. To support ECPO, we introduce an LLM-based user simulator, AILO, to simulate user feedback and perform expectation confirmation during conversational recommendations. Experimental results show that ECPO significantly enhances CRA's interaction capabilities, delivering notable improvements in both efficiency and effectiveness over existing MTPO methods.
KnowTrace: Bootstrapping Iterative Retrieval-Augmented Generation with Structured Knowledge Tracing
May 26, 2025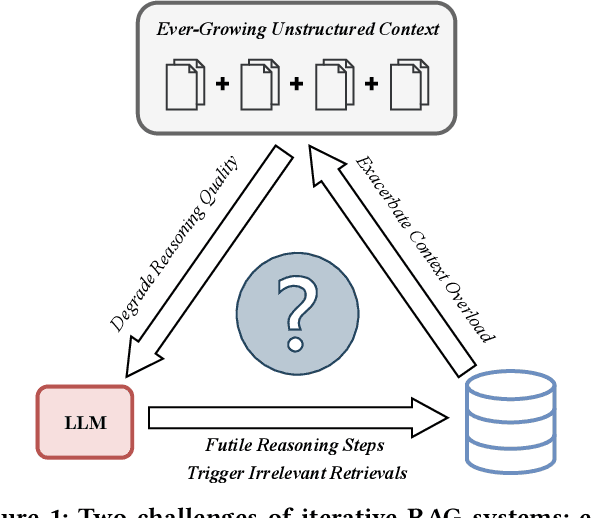
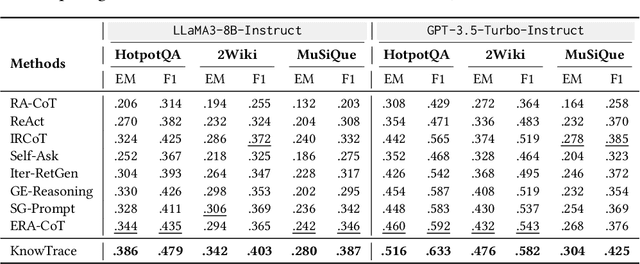
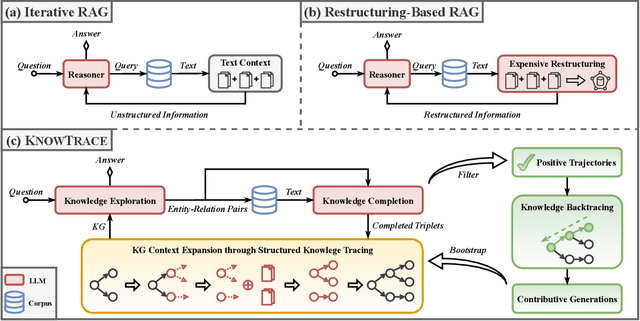
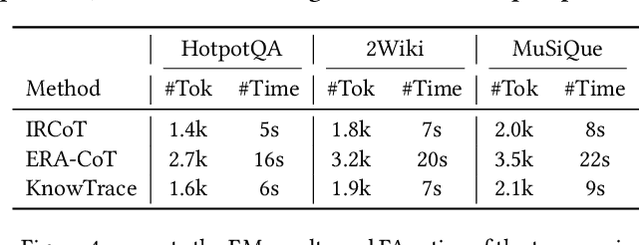
Recent advances in retrieval-augmented generation (RAG) furnish large language models (LLMs) with iterative retrievals of relevant information to handle complex multi-hop questions. These methods typically alternate between LLM reasoning and retrieval to accumulate external information into the LLM's context. However, the ever-growing context inherently imposes an increasing burden on the LLM to perceive connections among critical information pieces, with futile reasoning steps further exacerbating this overload issue. In this paper, we present KnowTrace, an elegant RAG framework to (1) mitigate the context overload and (2) bootstrap higher-quality multi-step reasoning. Instead of simply piling the retrieved contents, KnowTrace autonomously traces out desired knowledge triplets to organize a specific knowledge graph relevant to the input question. Such a structured workflow not only empowers the LLM with an intelligible context for inference, but also naturally inspires a reflective mechanism of knowledge backtracing to identify contributive LLM generations as process supervision data for self-bootstrapping. Extensive experiments show that KnowTrace consistently surpasses existing methods across three multi-hop question answering benchmarks, and the bootstrapped version further amplifies the gains.
Beyond Single-Point Judgment: Distribution Alignment for LLM-as-a-Judge
May 18, 2025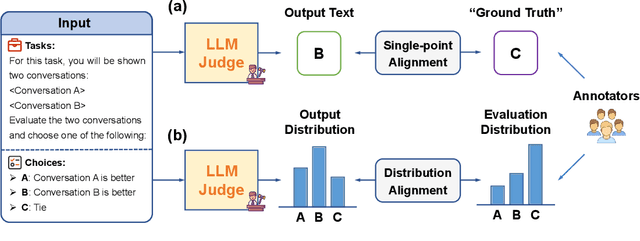
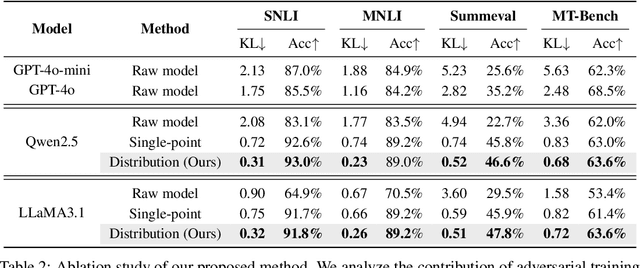
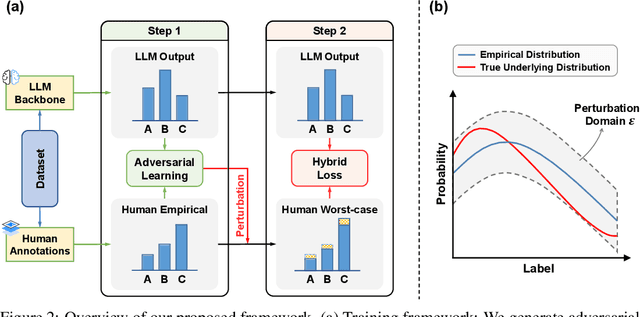
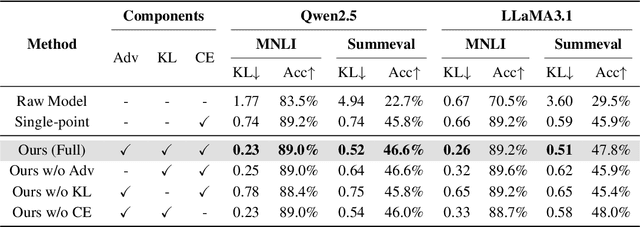
LLMs have emerged as powerful evaluators in the LLM-as-a-Judge paradigm, offering significant efficiency and flexibility compared to human judgments. However, previous methods primarily rely on single-point evaluations, overlooking the inherent diversity and uncertainty in human evaluations. This approach leads to information loss and decreases the reliability of evaluations. To address this limitation, we propose a novel training framework that explicitly aligns the LLM-generated judgment distribution with empirical human distributions. Specifically, we propose a distributional alignment objective based on KL divergence, combined with an auxiliary cross-entropy regularization to stabilize the training process. Furthermore, considering that empirical distributions may derive from limited human annotations, we incorporate adversarial training to enhance model robustness against distribution perturbations. Extensive experiments across various LLM backbones and evaluation tasks demonstrate that our framework significantly outperforms existing closed-source LLMs and conventional single-point alignment methods, with improved alignment quality, evaluation accuracy, and robustness.
MemEngine: A Unified and Modular Library for Developing Advanced Memory of LLM-based Agents
May 04, 2025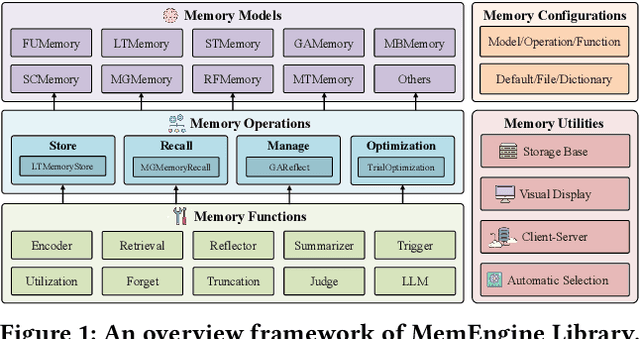
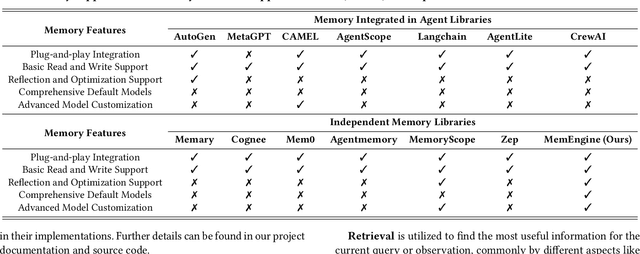
Recently, large language model based (LLM-based) agents have been widely applied across various fields. As a critical part, their memory capabilities have captured significant interest from both industrial and academic communities. Despite the proposal of many advanced memory models in recent research, however, there remains a lack of unified implementations under a general framework. To address this issue, we develop a unified and modular library for developing advanced memory models of LLM-based agents, called MemEngine. Based on our framework, we implement abundant memory models from recent research works. Additionally, our library facilitates convenient and extensible memory development, and offers user-friendly and pluggable memory usage. For benefiting our community, we have made our project publicly available at https://github.com/nuster1128/MemEngine.
Improving Retrospective Language Agents via Joint Policy Gradient Optimization
Mar 03, 2025In recent research advancements within the community, large language models (LLMs) have sparked great interest in creating autonomous agents. However, current prompt-based agents often heavily rely on large-scale LLMs. Meanwhile, although fine-tuning methods significantly enhance the capabilities of smaller LLMs, the fine-tuned agents often lack the potential for self-reflection and self-improvement. To address these challenges, we introduce a novel agent framework named RetroAct, which is a framework that jointly optimizes both task-planning and self-reflective evolution capabilities in language agents. Specifically, we develop a two-stage joint optimization process that integrates imitation learning and reinforcement learning, and design an off-policy joint policy gradient optimization algorithm with imitation learning regularization to enhance the data efficiency and training stability in agent tasks. RetroAct significantly improves the performance of open-source models, reduces dependency on closed-source LLMs, and enables fine-tuned agents to learn and evolve continuously. We conduct extensive experiments across various testing environments, demonstrating RetroAct has substantial improvements in task performance and decision-making processes.