 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBridging the Agent-World Gap: Text World Models for LLM-based Agents
Jun 08, 2026Large language model (LLM)-based agents are increasingly used in interactive textual environments, from web navigation and code editing to tool use and long-horizon dialogue. Yet many remain largely reactive, mapping observations to actions without an explicit model of how these environments are structured and evolve. This motivates text world models (TWMs): transition models over textual states that, given a state and a candidate action, predict the resulting webpage, terminal output, API response, or user reply, thereby supporting planning, efficient learning, and principled evaluation. We systematically review text world models for LLM-based agents, organized around a formal framework and the agent lifecycle: (1) Foundations, defining text world models and characterizing them by state representation and grounding domain; (2) Construction, taxonomizing LLM-as-WM and code-as-WM paradigms and reviewing methods for building them; (3) Application, examining how world models support agents at training time through experience synthesis and at inference time through planning, verification, and adaptation; and (4) Evaluation, covering both evaluation of the world model itself and its use as an evaluation environment for agents. We aim to consolidate this rapidly developing area, clarify its design space, and highlight open challenges for future research.
Dynamic Mixture of Latent Memories for Self-Evolving Agents
May 21, 2026Achieving self-evolution in intelligent agents requires the continual accumulation of new knowledge across changing task sequences without forgetting previously acquired abilities. Existing approaches either internalize knowledge by updating model parameters, which induces catastrophic forgetting, or rely on external memory, which fails to genuinely enhance the model's intrinsic capabilities. We propose MoLEM, a generative mixture of latent memory framework based on a dynamic mixture-of-experts (MoE). We treat multiple experts as independent carriers to generate memory. A router selects and weights experts through key-query matching, and the aggregated latent memory is injected into the reasoning process. The base model for reasoning remains entirely frozen, with all experiential knowledge internalized into the additional modules, avoiding catastrophic forgetting. For continual learning, each training stage is paired with a lightweight autoencoder that selects the appropriate routing group at inference, and inputs that match no stage fall back to the pretrained model. Experiments train the framework on continual-learning sequences spanning math, science, and code domains. After training, we evaluate the framework on the corresponding test sets to measure task learning and competence preservation across continual adaptation stages. After the full continual-learning sequence, our method improves the average accuracy by 10.40% over the Vanilla pretrained baseline, while none of the competing methods consistently exceed this baseline across different training orders.
PlanningBench: Generating Scalable and Verifiable Planning Data for Evaluating and Training Large Language Models
May 20, 2026Planning is a fundamental capability for large language models (LLMs) because such complex tasks require models to coordinate goals, constraints, resources, and long-term consequences into executable and verifiable solutions. Existing planning benchmarks, however, usually treat planning data as fixed collections of instances rather than controllable generation targets. This limits scenario coverage, ties difficulty to surface-level proxies rather than structural sources, and offers limited support for scalable generation, automatic verification, or planning-oriented training. We introduce PlanningBench, a framework for generating scalable, diverse, and verifiable planning data for both evaluation and training. PlanningBench starts from real planning scenarios and abstracts practical workflows into a structured taxonomy of more than 30 task types, subtasks, constraint families, and difficulty factors. Guided by this taxonomy, a constraint-driven synthesis pipeline instantiates self-contained planning problems with adaptive difficulty control, quality filtering, and instance-level verification checklists. This shifts planning data construction from fixed benchmark collection to controllable generation while preserving realistic task grounding. We use PlanningBench to evaluate open-source and closed-source frontier LLMs, and find that current models still struggle to produce complete solutions under coupled constraints. Beyond evaluation, reinforcement learning on verified PlanningBench data improves performance on unseen planning benchmarks and broader instruction-following tasks. Further analysis suggests that determinate or well-specified optimal solutions provide clearer reward signals and more stable training dynamics. Overall, PlanningBench provides a controllable source of planning data for diagnosing and improving generalizable planning abilities in LLMs.
Saliency-R1: Enforcing Interpretable and Faithful Vision-language Reasoning via Saliency-map Alignment Reward
Apr 06, 2026Vision-language models (VLMs) have achieved remarkable success across diverse tasks. However, concerns about their trustworthiness persist, particularly regarding tendencies to lean more on textual cues than visual evidence and the risk of producing ungrounded or fabricated responses. To address these issues, we propose Saliency-R1, a framework for improving the interpretability and faithfulness of VLMs reasoning. Specifically, we introduce a novel saliency map technique that efficiently highlights critical image regions contributing to generated tokens without additional computational overhead. This can further be extended to trace how visual information flows through the reasoning process to the final answers, revealing the alignment between the thinking process and the visual context. We use the overlap between the saliency maps and human-annotated bounding boxes as the reward function, and apply Group Relative Policy Optimization (GRPO) to align the salient parts and critical regions, encouraging models to focus on relevant areas when conduct reasoning. Experiments show Saliency-R1 improves reasoning faithfulness, interpretability, and overall task performance.
Search-R2: Enhancing Search-Integrated Reasoning via Actor-Refiner Collaboration
Feb 03, 2026Search-integrated reasoning enables language agents to transcend static parametric knowledge by actively querying external sources. However, training these agents via reinforcement learning is hindered by the multi-scale credit assignment problem: existing methods typically rely on sparse, trajectory-level rewards that fail to distinguish between high-quality reasoning and fortuitous guesses, leading to redundant or misleading search behaviors. To address this, we propose Search-R2, a novel Actor-Refiner collaboration framework that enhances reasoning through targeted intervention, with both components jointly optimized during training. Our approach decomposes the generation process into an Actor, which produces initial reasoning trajectories, and a Meta-Refiner, which selectively diagnoses and repairs flawed steps via a 'cut-and-regenerate' mechanism. To provide fine-grained supervision, we introduce a hybrid reward design that couples outcome correctness with a dense process reward quantifying the information density of retrieved evidence. Theoretically, we formalize the Actor-Refiner interaction as a smoothed mixture policy, proving that selective correction yields strict performance gains over strong baselines. Extensive experiments across various general and multi-hop QA datasets demonstrate that Search-R2 consistently outperforms strong RAG and RL-based baselines across model scales, achieving superior reasoning accuracy with minimal overhead.
Probability-Entropy Calibration: An Elastic Indicator for Adaptive Fine-tuning
Feb 02, 2026Token-level reweighting is a simple yet effective mechanism for controlling supervised fine-tuning, but common indicators are largely one-dimensional: the ground-truth probability reflects downstream alignment, while token entropy reflects intrinsic uncertainty induced by the pre-training prior. Ignoring entropy can misidentify noisy or easily replaceable tokens as learning-critical, while ignoring probability fails to reflect target-specific alignment. RankTuner introduces a probability--entropy calibration signal, the Relative Rank Indicator, which compares the rank of the ground-truth token with its expected rank under the prediction distribution. The inverse indicator is used as a token-wise Relative Scale to reweight the fine-tuning objective, focusing updates on truly under-learned tokens without over-penalizing intrinsically uncertain positions. Experiments on multiple backbones show consistent improvements on mathematical reasoning benchmarks, transfer gains on out-of-distribution reasoning, and pre code generation performance over probability-only or entropy-only reweighting baselines.
ConMax: Confidence-Maximizing Compression for Efficient Chain-of-Thought Reasoning
Jan 08, 2026Recent breakthroughs in Large Reasoning Models (LRMs) have demonstrated that extensive Chain-of-Thought (CoT) generation is critical for enabling intricate cognitive behaviors, such as self-verification and backtracking, to solve complex tasks. However, this capability often leads to ``overthinking'', where models generate redundant reasoning paths that inflate computational costs without improving accuracy. While Supervised Fine-Tuning (SFT) on reasoning traces is a standard paradigm for the 'cold start' phase, applying existing compression techniques to these traces often compromises logical coherence or incurs prohibitive sampling costs. In this paper, we introduce ConMax (Confidence-Maximizing Compression), a novel reinforcement learning framework designed to automatically compress reasoning traces while preserving essential reasoning patterns. ConMax formulates compression as a reward-driven optimization problem, training a policy to prune redundancy by maximizing a weighted combination of answer confidence for predictive fidelity and thinking confidence for reasoning validity through a frozen auxiliary LRM. Extensive experiments across five reasoning datasets demonstrate that ConMax achieves a superior efficiency-performance trade-off. Specifically, it reduces inference length by 43% over strong baselines at the cost of a mere 0.7% dip in accuracy, proving its effectiveness in generating high-quality, efficient training data for LRMs.
A Survey of Self-Evolving Agents: On Path to Artificial Super Intelligence
Jul 28, 2025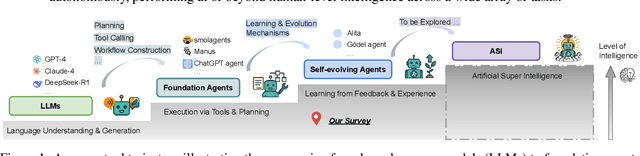

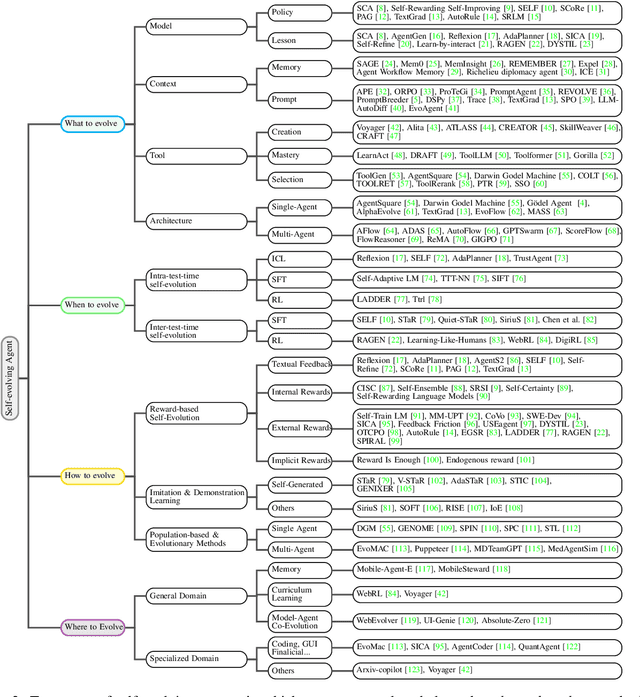
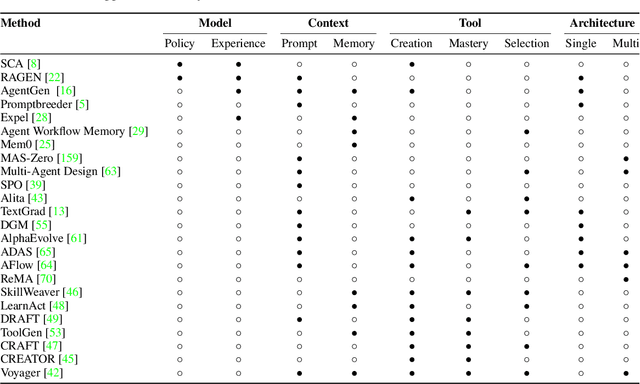
Large Language Models (LLMs) have demonstrated strong capabilities but remain fundamentally static, unable to adapt their internal parameters to novel tasks, evolving knowledge domains, or dynamic interaction contexts. As LLMs are increasingly deployed in open-ended, interactive environments, this static nature has become a critical bottleneck, necessitating agents that can adaptively reason, act, and evolve in real time. This paradigm shift -- from scaling static models to developing self-evolving agents -- has sparked growing interest in architectures and methods enabling continual learning and adaptation from data, interactions, and experiences. This survey provides the first systematic and comprehensive review of self-evolving agents, organized around three foundational dimensions -- what to evolve, when to evolve, and how to evolve. We examine evolutionary mechanisms across agent components (e.g., models, memory, tools, architecture), categorize adaptation methods by stages (e.g., intra-test-time, inter-test-time), and analyze the algorithmic and architectural designs that guide evolutionary adaptation (e.g., scalar rewards, textual feedback, single-agent and multi-agent systems). Additionally, we analyze evaluation metrics and benchmarks tailored for self-evolving agents, highlight applications in domains such as coding, education, and healthcare, and identify critical challenges and research directions in safety, scalability, and co-evolutionary dynamics. By providing a structured framework for understanding and designing self-evolving agents, this survey establishes a roadmap for advancing adaptive agentic systems in both research and real-world deployments, ultimately shedding lights to pave the way for the realization of Artificial Super Intelligence (ASI), where agents evolve autonomously, performing at or beyond human-level intelligence across a wide array of tasks.
WebCoT: Enhancing Web Agent Reasoning by Reconstructing Chain-of-Thought in Reflection, Branching, and Rollback
May 26, 2025Web agents powered by Large Language Models (LLMs) show promise for next-generation AI, but their limited reasoning in uncertain, dynamic web environments hinders robust deployment. In this paper, we identify key reasoning skills essential for effective web agents, i.e., reflection & lookahead, branching, and rollback, and curate trajectory data that exemplifies these abilities by reconstructing the agent's (inference-time) reasoning algorithms into chain-of-thought rationales. We conduct experiments in the agent self-improving benchmark, OpenWebVoyager, and demonstrate that distilling salient reasoning patterns into the backbone LLM via simple fine-tuning can substantially enhance its performance. Our approach yields significant improvements across multiple benchmarks, including WebVoyager, Mind2web-live, and SimpleQA (web search), highlighting the potential of targeted reasoning skill enhancement for web agents.
A Survey of Personalized Large Language Models: Progress and Future Directions
Feb 17, 2025Large Language Models (LLMs) excel in handling general knowledge tasks, yet they struggle with user-specific personalization, such as understanding individual emotions, writing styles, and preferences. Personalized Large Language Models (PLLMs) tackle these challenges by leveraging individual user data, such as user profiles, historical dialogues, content, and interactions, to deliver responses that are contextually relevant and tailored to each user's specific needs. This is a highly valuable research topic, as PLLMs can significantly enhance user satisfaction and have broad applications in conversational agents, recommendation systems, emotion recognition, medical assistants, and more. This survey reviews recent advancements in PLLMs from three technical perspectives: prompting for personalized context (input level), finetuning for personalized adapters (model level), and alignment for personalized preferences (objective level). To provide deeper insights, we also discuss current limitations and outline several promising directions for future research. Updated information about this survey can be found at the https://github.com/JiahongLiu21/Awesome-Personalized-Large-Language-Models.