 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInnoEval: On Research Idea Evaluation as a Knowledge-Grounded, Multi-Perspective Reasoning Problem
Feb 16, 2026The rapid evolution of Large Language Models has catalyzed a surge in scientific idea production, yet this leap has not been accompanied by a matching advance in idea evaluation. The fundamental nature of scientific evaluation needs knowledgeable grounding, collective deliberation, and multi-criteria decision-making. However, existing idea evaluation methods often suffer from narrow knowledge horizons, flattened evaluation dimensions, and the inherent bias in LLM-as-a-Judge. To address these, we regard idea evaluation as a knowledge-grounded, multi-perspective reasoning problem and introduce InnoEval, a deep innovation evaluation framework designed to emulate human-level idea assessment. We apply a heterogeneous deep knowledge search engine that retrieves and grounds dynamic evidence from diverse online sources. We further achieve review consensus with an innovation review board containing reviewers with distinct academic backgrounds, enabling a multi-dimensional decoupled evaluation across multiple metrics. We construct comprehensive datasets derived from authoritative peer-reviewed submissions to benchmark InnoEval. Experiments demonstrate that InnoEval can consistently outperform baselines in point-wise, pair-wise, and group-wise evaluation tasks, exhibiting judgment patterns and consensus highly aligned with human experts.
Memory-T1: Reinforcement Learning for Temporal Reasoning in Multi-session Agents
Dec 23, 2025Temporal reasoning over long, multi-session dialogues is a critical capability for conversational agents. However, existing works and our pilot study have shown that as dialogue histories grow in length and accumulate noise, current long-context models struggle to accurately identify temporally pertinent information, significantly impairing reasoning performance. To address this, we introduce Memory-T1, a framework that learns a time-aware memory selection policy using reinforcement learning (RL). It employs a coarse-to-fine strategy, first pruning the dialogue history into a candidate set using temporal and relevance filters, followed by an RL agent that selects the precise evidence sessions. The RL training is guided by a multi-level reward function optimizing (i) answer accuracy, (ii) evidence grounding, and (iii) temporal consistency. In particular, the temporal consistency reward provides a dense signal by evaluating alignment with the query time scope at both the session-level (chronological proximity) and the utterance-level (chronological fidelity), enabling the agent to resolve subtle chronological ambiguities. On the Time-Dialog benchmark, Memory-T1 boosts a 7B model to an overall score of 67.0\%, establishing a new state-of-the-art performance for open-source models and outperforming a 14B baseline by 10.2\%. Ablation studies show temporal consistency and evidence grounding rewards jointly contribute to a 15.0\% performance gain. Moreover, Memory-T1 maintains robustness up to 128k tokens, where baseline models collapse, proving effectiveness against noise in extensive dialogue histories. The code and datasets are publicly available at https://github.com/Elvin-Yiming-Du/Memory-T1/
Explore to Evolve: Scaling Evolved Aggregation Logic via Proactive Online Exploration for Deep Research Agents
Oct 16, 2025Deep research web agents not only retrieve information from diverse sources such as web environments, files, and multimodal inputs, but more importantly, they need to rigorously analyze and aggregate knowledge for insightful research. However, existing open-source deep research agents predominantly focus on enhancing information-seeking capabilities of web agents to locate specific information, while overlooking the essential need for information aggregation, which would limit their ability to support in-depth research. We propose an Explore to Evolve paradigm to scalably construct verifiable training data for web agents. Begins with proactive online exploration, an agent sources grounded information by exploring the real web. Using the collected evidence, the agent then self-evolves an aggregation program by selecting, composing, and refining operations from 12 high-level logical types to synthesize a verifiable QA pair. This evolution from high-level guidance to concrete operations allowed us to scalably produce WebAggregatorQA, a dataset of 10K samples across 50K websites and 11 domains. Based on an open-source agent framework, SmolAgents, we collect supervised fine-tuning trajectories to develop a series of foundation models, WebAggregator. WebAggregator-8B matches the performance of GPT-4.1, while the 32B variant surpasses GPT-4.1 by more than 10% on GAIA-text and closely approaches Claude-3.7-sonnet. Moreover, given the limited availability of benchmarks that evaluate web agents' information aggregation abilities, we construct a human-annotated evaluation split of WebAggregatorQA as a challenging test set. On this benchmark, Claude-3.7-sonnet only achieves 28%, and GPT-4.1 scores 25.8%. Even when agents manage to retrieve all references, they still struggle on WebAggregatorQA, highlighting the need to strengthen the information aggregation capabilities of web agent foundations.
Self-Error-Instruct: Generalizing from Errors for LLMs Mathematical Reasoning
May 28, 2025
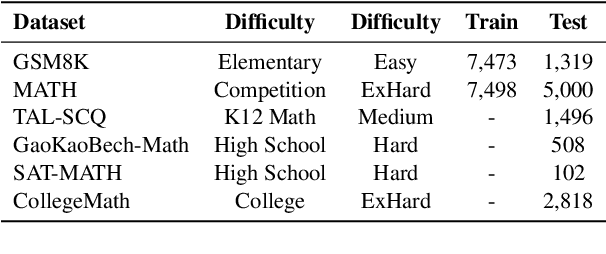

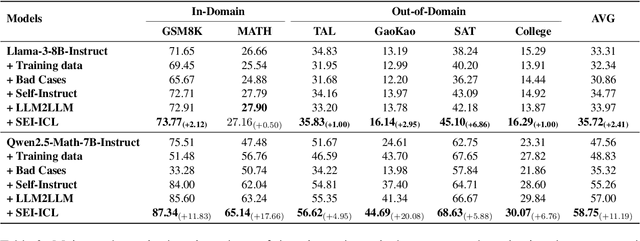
Although large language models demonstrate strong performance across various domains, they still struggle with numerous bad cases in mathematical reasoning. Previous approaches to learning from errors synthesize training data by solely extrapolating from isolated bad cases, thereby failing to generalize the extensive patterns inherent within these cases. This paper presents Self-Error-Instruct (SEI), a framework that addresses these model weaknesses and synthesizes more generalized targeted training data. Specifically, we explore a target model on two mathematical datasets, GSM8K and MATH, to pinpoint bad cases. Then, we generate error keyphrases for these cases based on the instructor model's (GPT-4o) analysis and identify error types by clustering these keyphrases. Next, we sample a few bad cases during each generation for each identified error type and input them into the instructor model, which synthesizes additional training data using a self-instruct approach. This new data is refined through a one-shot learning process to ensure that only the most effective examples are kept. Finally, we use these curated data to fine-tune the target model, iteratively repeating the process to enhance performance. We apply our framework to various models and observe improvements in their reasoning abilities across both in-domain and out-of-domain mathematics datasets. These results demonstrate the effectiveness of self-error instruction in improving LLMs' mathematical reasoning through error generalization.
Harnessing the Reasoning Economy: A Survey of Efficient Reasoning for Large Language Models
Mar 31, 2025Recent advancements in Large Language Models (LLMs) have significantly enhanced their ability to perform complex reasoning tasks, transitioning from fast and intuitive thinking (System 1) to slow and deep reasoning (System 2). While System 2 reasoning improves task accuracy, it often incurs substantial computational costs due to its slow thinking nature and inefficient or unnecessary reasoning behaviors. In contrast, System 1 reasoning is computationally efficient but leads to suboptimal performance. Consequently, it is critical to balance the trade-off between performance (benefits) and computational costs (budgets), giving rise to the concept of reasoning economy. In this survey, we provide a comprehensive analysis of reasoning economy in both the post-training and test-time inference stages of LLMs, encompassing i) the cause of reasoning inefficiency, ii) behavior analysis of different reasoning patterns, and iii) potential solutions to achieve reasoning economy. By offering actionable insights and highlighting open challenges, we aim to shed light on strategies for improving the reasoning economy of LLMs, thereby serving as a valuable resource for advancing research in this evolving area. We also provide a public repository to continually track developments in this fast-evolving field.
TreeSynth: Synthesizing Diverse Data from Scratch via Tree-Guided Subspace Partitioning
Mar 21, 2025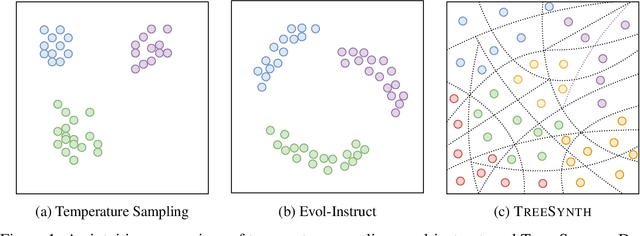
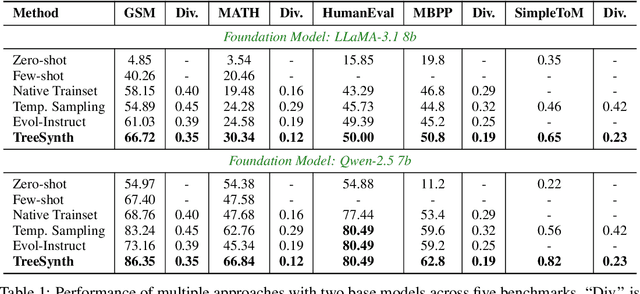
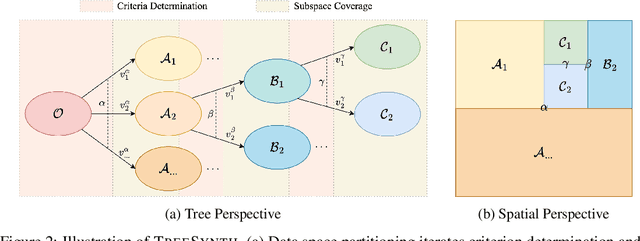
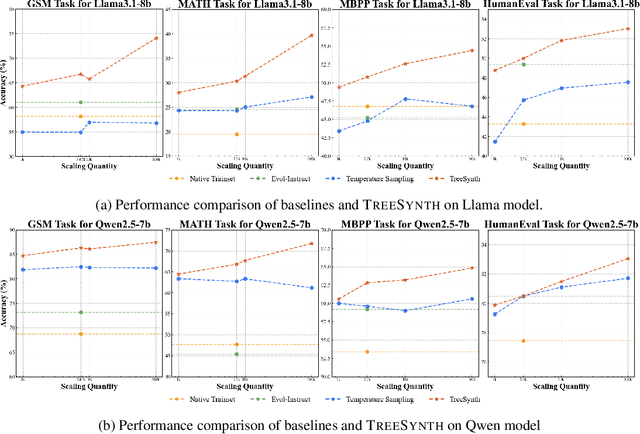
Model customization requires high-quality and diverse datasets, but acquiring such data remains challenging and costly. Although large language models (LLMs) can synthesize training data, current approaches are constrained by limited seed data, model bias and insufficient control over the generation process, resulting in limited diversity and biased distribution with the increase of data scales. To tackle this challenge, we present TreeSynth, a tree-guided subspace-based data synthesis framework that recursively partitions the entire data space into hierar-chical subspaces, enabling comprehensive and diverse scaling of data synthesis. Briefly, given a task-specific description, we construct a data space partitioning tree by iteratively executing criteria determination and subspace coverage steps. This hierarchically divides the whole space (i.e., root node) into mutually exclusive and complementary atomic subspaces (i.e., leaf nodes). By collecting synthesized data according to the attributes of each leaf node, we obtain a diverse dataset that fully covers the data space. Empirically, our extensive experiments demonstrate that TreeSynth surpasses both human-designed datasets and the state-of-the-art data synthesis baselines, achieving maximum improvements of 45.2% in data diversity and 17.6% in downstream task performance across various models and tasks. Hopefully, TreeSynth provides a scalable solution to synthesize diverse and comprehensive datasets from scratch without human intervention.
DAST: Difficulty-Aware Self-Training on Large Language Models
Mar 12, 2025Present Large Language Models (LLM) self-training methods always under-sample on challenging queries, leading to inadequate learning on difficult problems which limits LLMs' ability. Therefore, this work proposes a difficulty-aware self-training (DAST) framework that focuses on improving both the quantity and quality of self-generated responses on challenging queries during self-training. DAST is specified in three components: 1) sampling-based difficulty level estimation, 2) difficulty-aware data augmentation, and 3) the self-training algorithm using SFT and DPO respectively. Experiments on mathematical tasks demonstrate the effectiveness and generalization of DAST, highlighting the critical role of difficulty-aware strategies in advancing LLM self-training.
UAlign: Leveraging Uncertainty Estimations for Factuality Alignment on Large Language Models
Dec 16, 2024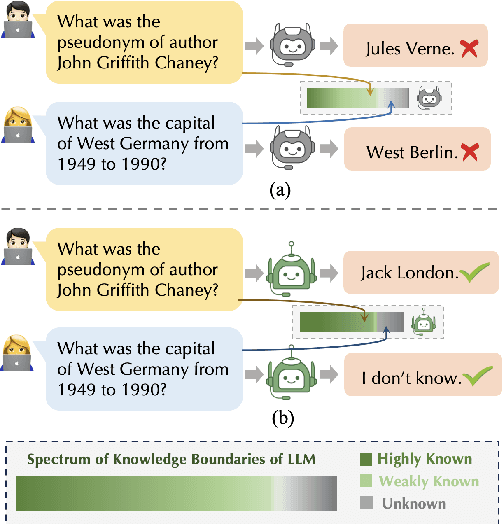
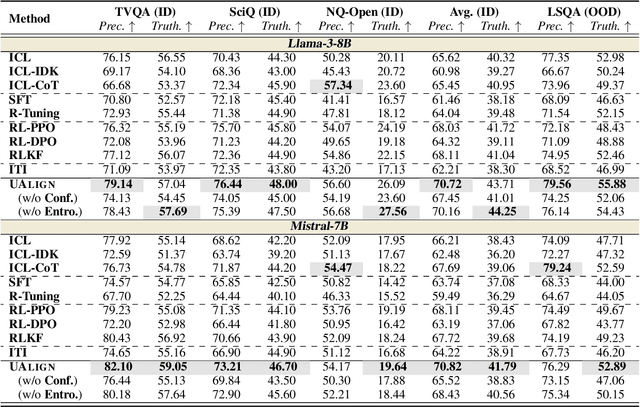

Despite demonstrating impressive capabilities, Large Language Models (LLMs) still often struggle to accurately express the factual knowledge they possess, especially in cases where the LLMs' knowledge boundaries are ambiguous. To improve LLMs' factual expressions, we propose the UAlign framework, which leverages Uncertainty estimations to represent knowledge boundaries, and then explicitly incorporates these representations as input features into prompts for LLMs to Align with factual knowledge. First, we prepare the dataset on knowledge question-answering (QA) samples by calculating two uncertainty estimations, including confidence score and semantic entropy, to represent the knowledge boundaries for LLMs. Subsequently, using the prepared dataset, we train a reward model that incorporates uncertainty estimations and then employ the Proximal Policy Optimization (PPO) algorithm for factuality alignment on LLMs. Experimental results indicate that, by integrating uncertainty representations in LLM alignment, the proposed UAlign can significantly enhance the LLMs' capacities to confidently answer known questions and refuse unknown questions on both in-domain and out-of-domain tasks, showing reliability improvements and good generalizability over various prompt- and training-based baselines.
MlingConf: A Comprehensive Study of Multilingual Confidence Estimation on Large Language Models
Oct 16, 2024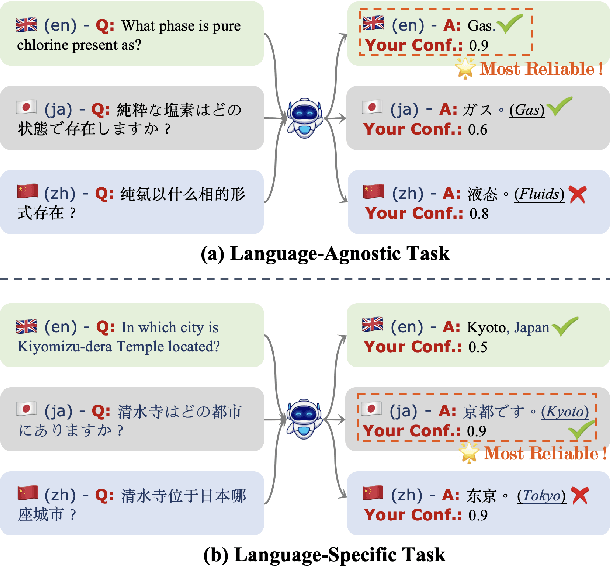

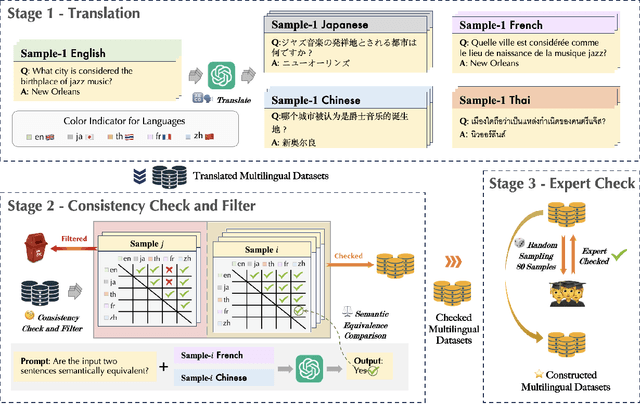
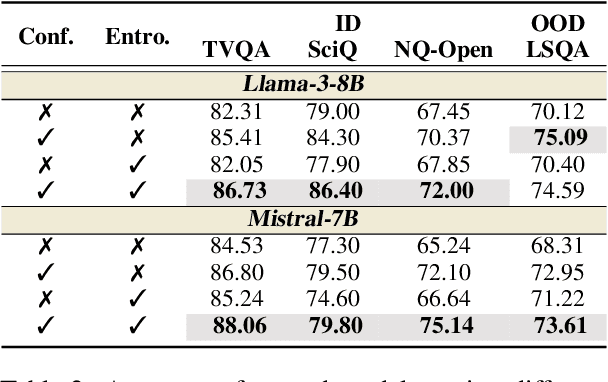
The tendency of Large Language Models (LLMs) to generate hallucinations raises concerns regarding their reliability. Therefore, confidence estimations indicating the extent of trustworthiness of the generations become essential. However, current LLM confidence estimations in languages other than English remain underexplored. This paper addresses this gap by introducing a comprehensive investigation of Multilingual Confidence estimation (MlingConf) on LLMs, focusing on both language-agnostic (LA) and language-specific (LS) tasks to explore the performance and language dominance effects of multilingual confidence estimations on different tasks. The benchmark comprises four meticulously checked and human-evaluate high-quality multilingual datasets for LA tasks and one for the LS task tailored to specific social, cultural, and geographical contexts of a language. Our experiments reveal that on LA tasks English exhibits notable linguistic dominance in confidence estimations than other languages, while on LS tasks, using question-related language to prompt LLMs demonstrates better linguistic dominance in multilingual confidence estimations. The phenomena inspire a simple yet effective native-tone prompting strategy by employing language-specific prompts for LS tasks, effectively improving LLMs' reliability and accuracy on LS tasks.
MoS: Unleashing Parameter Efficiency of Low-Rank Adaptation with Mixture of Shards
Oct 01, 2024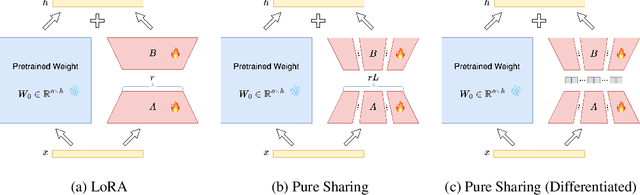

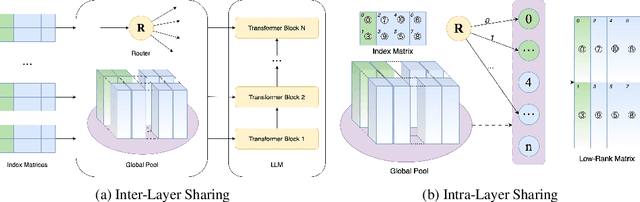
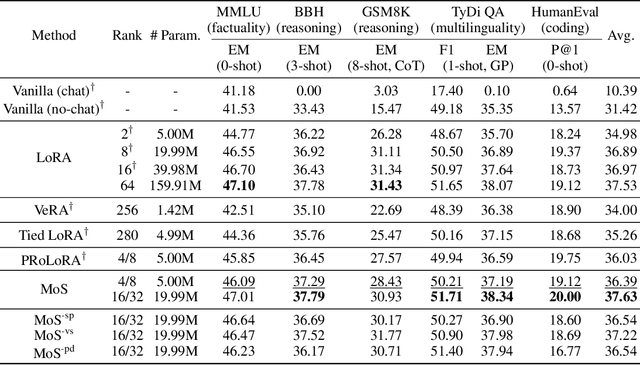
The rapid scaling of large language models necessitates more lightweight finetuning methods to reduce the explosive GPU memory overhead when numerous customized models are served simultaneously. Targeting more parameter-efficient low-rank adaptation (LoRA), parameter sharing presents a promising solution. Empirically, our research into high-level sharing principles highlights the indispensable role of differentiation in reversing the detrimental effects of pure sharing. Guided by this finding, we propose Mixture of Shards (MoS), incorporating both inter-layer and intra-layer sharing schemes, and integrating four nearly cost-free differentiation strategies, namely subset selection, pair dissociation, vector sharding, and shard privatization. Briefly, it selects a designated number of shards from global pools with a Mixture-of-Experts (MoE)-like routing mechanism before sequentially concatenating them to low-rank matrices. Hence, it retains all the advantages of LoRA while offering enhanced parameter efficiency, and effectively circumvents the drawbacks of peer parameter-sharing methods. Our empirical experiments demonstrate approximately 8x parameter savings in a standard LoRA setting. The ablation study confirms the significance of each component. Our insights into parameter sharing and MoS method may illuminate future developments of more parameter-efficient finetuning methods.