 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDon't believe everything you read: Understanding and Measuring MCP Behavior under Misleading Tool Descriptions
Feb 03, 2026The Model Context Protocol (MCP) enables large language models to invoke external tools through natural-language descriptions, forming the foundation of many AI agent applications. However, MCP does not enforce consistency between documented tool behavior and actual code execution, even though MCP Servers often run with broad system privileges. This gap introduces a largely unexplored security risk. We study how mismatches between externally presented tool descriptions and underlying implementations systematically shape the mental models and decision-making behavior of intelligent agents. Specifically, we present the first large-scale study of description-code inconsistency in the MCP ecosystem. We design an automated static analysis framework and apply it to 10,240 real-world MCP Servers across 36 categories. Our results show that while most servers are highly consistent, approximately 13% exhibit substantial mismatches that can enable undocumented privileged operations, hidden state mutations, or unauthorized financial actions. We further observe systematic differences across application categories, popularity levels, and MCP marketplaces. Our findings demonstrate that description-code inconsistency is a concrete and prevalent attack surface in MCP-based AI agents, and motivate the need for systematic auditing and stronger transparency guarantees in future agent ecosystems.
ClusterUCB: Efficient Gradient-Based Data Selection for Targeted Fine-Tuning of LLMs
Jun 12, 2025Gradient-based data influence approximation has been leveraged to select useful data samples in the supervised fine-tuning of large language models. However, the computation of gradients throughout the fine-tuning process requires too many resources to be feasible in practice. In this paper, we propose an efficient gradient-based data selection framework with clustering and a modified Upper Confidence Bound (UCB) algorithm. Based on the intuition that data samples with similar gradient features will have similar influences, we first perform clustering on the training data pool. Then, we frame the inter-cluster data selection as a constrained computing budget allocation problem and consider it a multi-armed bandit problem. A modified UCB algorithm is leveraged to solve this problem. Specifically, during the iterative sampling process, historical data influence information is recorded to directly estimate the distributions of each cluster, and a cold start is adopted to balance exploration and exploitation. Experimental results on various benchmarks show that our proposed framework, ClusterUCB, can achieve comparable results to the original gradient-based data selection methods while greatly reducing computing consumption.
Self-Error-Instruct: Generalizing from Errors for LLMs Mathematical Reasoning
May 28, 2025
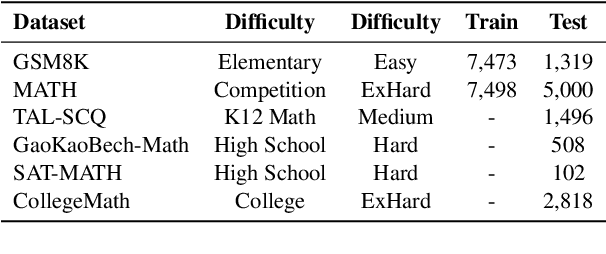

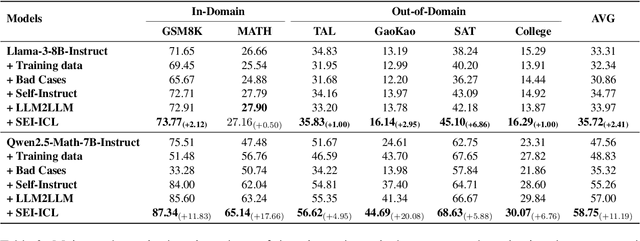
Although large language models demonstrate strong performance across various domains, they still struggle with numerous bad cases in mathematical reasoning. Previous approaches to learning from errors synthesize training data by solely extrapolating from isolated bad cases, thereby failing to generalize the extensive patterns inherent within these cases. This paper presents Self-Error-Instruct (SEI), a framework that addresses these model weaknesses and synthesizes more generalized targeted training data. Specifically, we explore a target model on two mathematical datasets, GSM8K and MATH, to pinpoint bad cases. Then, we generate error keyphrases for these cases based on the instructor model's (GPT-4o) analysis and identify error types by clustering these keyphrases. Next, we sample a few bad cases during each generation for each identified error type and input them into the instructor model, which synthesizes additional training data using a self-instruct approach. This new data is refined through a one-shot learning process to ensure that only the most effective examples are kept. Finally, we use these curated data to fine-tune the target model, iteratively repeating the process to enhance performance. We apply our framework to various models and observe improvements in their reasoning abilities across both in-domain and out-of-domain mathematics datasets. These results demonstrate the effectiveness of self-error instruction in improving LLMs' mathematical reasoning through error generalization.
Say What You Mean: Natural Language Access Control with Large Language Models for Internet of Things
May 28, 2025Access control in the Internet of Things (IoT) is becoming increasingly complex, as policies must account for dynamic and contextual factors such as time, location, user behavior, and environmental conditions. However, existing platforms either offer only coarse-grained controls or rely on rigid rule matching, making them ill-suited for semantically rich or ambiguous access scenarios. Moreover, the policy authoring process remains fragmented: domain experts describe requirements in natural language, but developers must manually translate them into code, introducing semantic gaps and potential misconfiguration. In this work, we present LACE, the Language-based Access Control Engine, a hybrid framework that leverages large language models (LLMs) to bridge the gap between human intent and machine-enforceable logic. LACE combines prompt-guided policy generation, retrieval-augmented reasoning, and formal validation to support expressive, interpretable, and verifiable access control. It enables users to specify policies in natural language, automatically translates them into structured rules, validates semantic correctness, and makes access decisions using a hybrid LLM-rule-based engine. We evaluate LACE in smart home environments through extensive experiments. LACE achieves 100% correctness in verified policy generation and up to 88% decision accuracy with 0.79 F1-score using DeepSeek-V3, outperforming baselines such as GPT-3.5 and Gemini. The system also demonstrates strong scalability under increasing policy volume and request concurrency. Our results highlight LACE's potential to enable secure, flexible, and user-friendly access control across real-world IoT platforms.
Pangu Ultra: Pushing the Limits of Dense Large Language Models on Ascend NPUs
Apr 10, 2025



We present Pangu Ultra, a Large Language Model (LLM) with 135 billion parameters and dense Transformer modules trained on Ascend Neural Processing Units (NPUs). Although the field of LLM has been witnessing unprecedented advances in pushing the scale and capability of LLM in recent years, training such a large-scale model still involves significant optimization and system challenges. To stabilize the training process, we propose depth-scaled sandwich normalization, which effectively eliminates loss spikes during the training process of deep models. We pre-train our model on 13.2 trillion diverse and high-quality tokens and further enhance its reasoning capabilities during post-training. To perform such large-scale training efficiently, we utilize 8,192 Ascend NPUs with a series of system optimizations. Evaluations on multiple diverse benchmarks indicate that Pangu Ultra significantly advances the state-of-the-art capabilities of dense LLMs such as Llama 405B and Mistral Large 2, and even achieves competitive results with DeepSeek-R1, whose sparse model structure contains much more parameters. Our exploration demonstrates that Ascend NPUs are capable of efficiently and effectively training dense models with more than 100 billion parameters. Our model and system will be available for our commercial customers.
Upcycling Noise for Federated Unlearning
Dec 07, 2024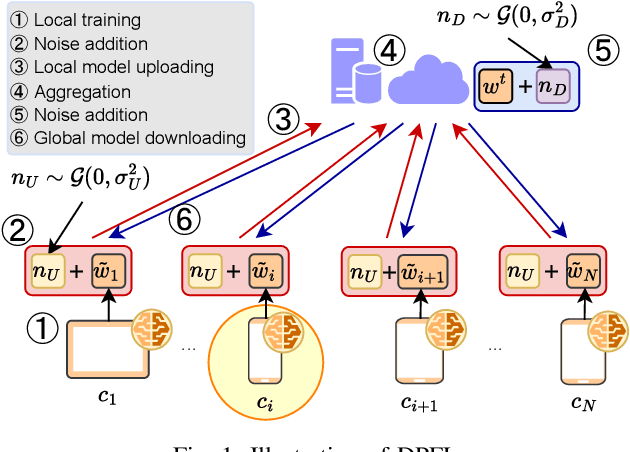
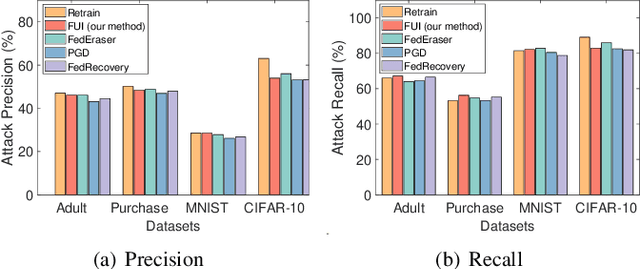
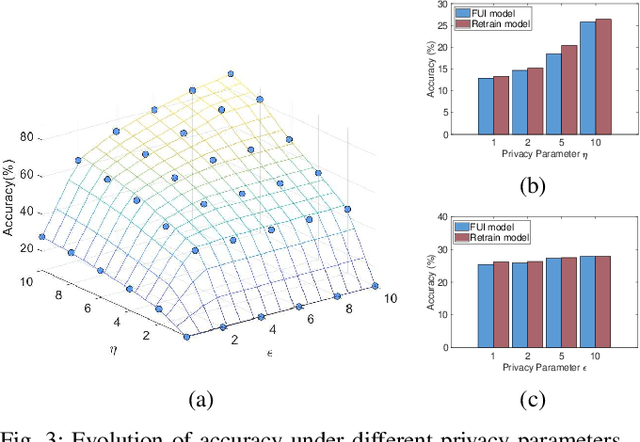
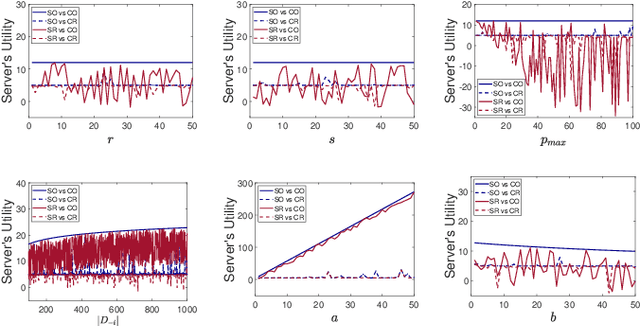
In Federated Learning (FL), multiple clients collaboratively train a model without sharing raw data. This paradigm can be further enhanced by Differential Privacy (DP) to protect local data from information inference attacks and is thus termed DPFL. An emerging privacy requirement, ``the right to be forgotten'' for clients, poses new challenges to DPFL but remains largely unexplored. Despite numerous studies on federated unlearning (FU), they are inapplicable to DPFL because the noise introduced by the DP mechanism compromises their effectiveness and efficiency. In this paper, we propose Federated Unlearning with Indistinguishability (FUI) to unlearn the local data of a target client in DPFL for the first time. FUI consists of two main steps: local model retraction and global noise calibration, resulting in an unlearning model that is statistically indistinguishable from the retrained model. Specifically, we demonstrate that the noise added in DPFL can endow the unlearning model with a certain level of indistinguishability after local model retraction, and then fortify the degree of unlearning through global noise calibration. Additionally, for the efficient and consistent implementation of the proposed FUI, we formulate a two-stage Stackelberg game to derive optimal unlearning strategies for both the server and the target client. Privacy and convergence analyses confirm theoretical guarantees, while experimental results based on four real-world datasets illustrate that our proposed FUI achieves superior model performance and higher efficiency compared to mainstream FU schemes. Simulation results further verify the optimality of the derived unlearning strategies.
VMID: A Multimodal Fusion LLM Framework for Detecting and Identifying Misinformation of Short Videos
Nov 15, 2024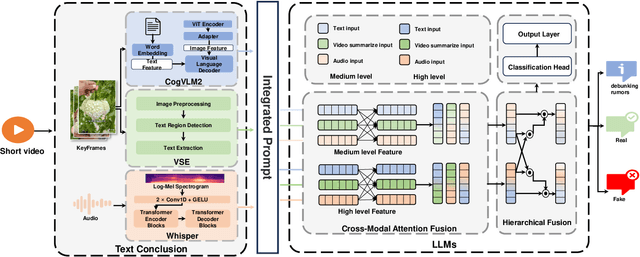
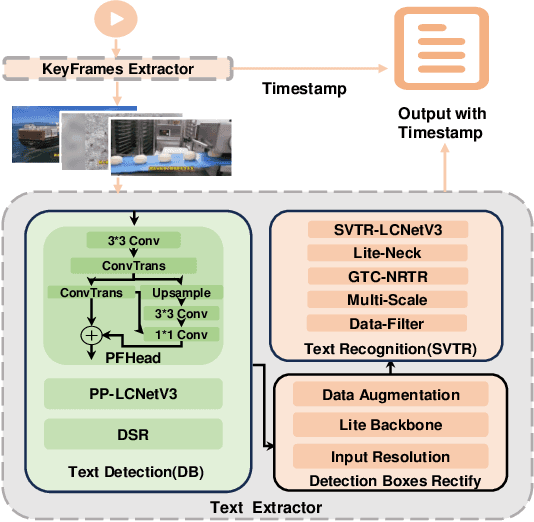

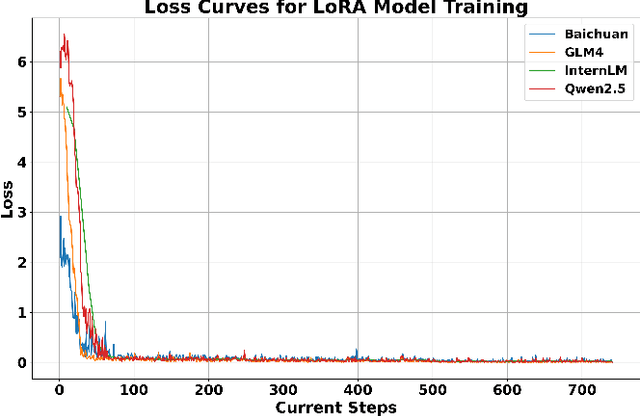
Short video platforms have become important channels for news dissemination, offering a highly engaging and immediate way for users to access current events and share information. However, these platforms have also emerged as significant conduits for the rapid spread of misinformation, as fake news and rumors can leverage the visual appeal and wide reach of short videos to circulate extensively among audiences. Existing fake news detection methods mainly rely on single-modal information, such as text or images, or apply only basic fusion techniques, limiting their ability to handle the complex, multi-layered information inherent in short videos. To address these limitations, this paper presents a novel fake news detection method based on multimodal information, designed to identify misinformation through a multi-level analysis of video content. This approach effectively utilizes different modal representations to generate a unified textual description, which is then fed into a large language model for comprehensive evaluation. The proposed framework successfully integrates multimodal features within videos, significantly enhancing the accuracy and reliability of fake news detection. Experimental results demonstrate that the proposed approach outperforms existing models in terms of accuracy, robustness, and utilization of multimodal information, achieving an accuracy of 90.93%, which is significantly higher than the best baseline model (SV-FEND) at 81.05%. Furthermore, case studies provide additional evidence of the effectiveness of the approach in accurately distinguishing between fake news, debunking content, and real incidents, highlighting its reliability and robustness in real-world applications.
Modeling Unified Semantic Discourse Structure for High-quality Headline Generation
Mar 23, 2024



Headline generation aims to summarize a long document with a short, catchy title that reflects the main idea. This requires accurately capturing the core document semantics, which is challenging due to the lengthy and background information-rich na ture of the texts. In this work, We propose using a unified semantic discourse structure (S3) to represent document semantics, achieved by combining document-level rhetorical structure theory (RST) trees with sentence-level abstract meaning representation (AMR) graphs to construct S3 graphs. The hierarchical composition of sentence, clause, and word intrinsically characterizes the semantic meaning of the overall document. We then develop a headline generation framework, in which the S3 graphs are encoded as contextual features. To consolidate the efficacy of S3 graphs, we further devise a hierarchical structure pruning mechanism to dynamically screen the redundant and nonessential nodes within the graph. Experimental results on two headline generation datasets demonstrate that our method outperforms existing state-of-art methods consistently. Our work can be instructive for a broad range of document modeling tasks, more than headline or summarization generation.
FedRFQ: Prototype-Based Federated Learning with Reduced Redundancy, Minimal Failure, and Enhanced Quality
Jan 15, 2024


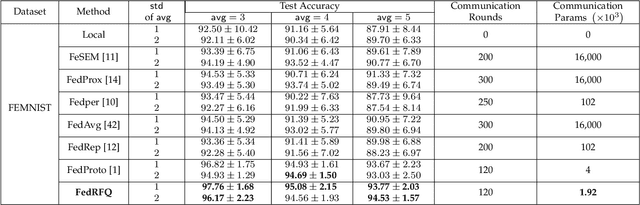
Federated learning is a powerful technique that enables collaborative learning among different clients. Prototype-based federated learning is a specific approach that improves the performance of local models under non-IID (non-Independently and Identically Distributed) settings by integrating class prototypes. However, prototype-based federated learning faces several challenges, such as prototype redundancy and prototype failure, which limit its accuracy. It is also susceptible to poisoning attacks and server malfunctions, which can degrade the prototype quality. To address these issues, we propose FedRFQ, a prototype-based federated learning approach that aims to reduce redundancy, minimize failures, and improve \underline{q}uality. FedRFQ leverages a SoftPool mechanism, which effectively mitigates prototype redundancy and prototype failure on non-IID data. Furthermore, we introduce the BFT-detect, a BFT (Byzantine Fault Tolerance) detectable aggregation algorithm, to ensure the security of FedRFQ against poisoning attacks and server malfunctions. Finally, we conduct experiments on three different datasets, namely MNIST, FEMNIST, and CIFAR-10, and the results demonstrate that FedRFQ outperforms existing baselines in terms of accuracy when handling non-IID data.
DEPN: Detecting and Editing Privacy Neurons in Pretrained Language Models
Oct 31, 2023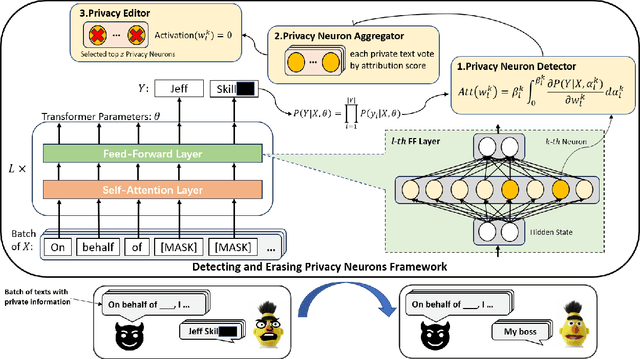

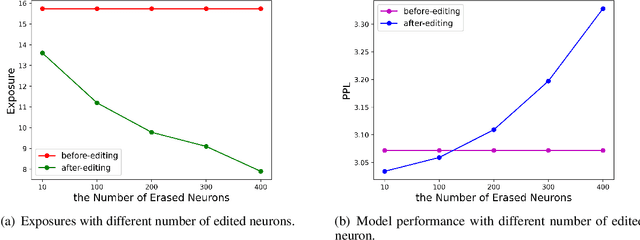

Large language models pretrained on a huge amount of data capture rich knowledge and information in the training data. The ability of data memorization and regurgitation in pretrained language models, revealed in previous studies, brings the risk of data leakage. In order to effectively reduce these risks, we propose a framework DEPN to Detect and Edit Privacy Neurons in pretrained language models, partially inspired by knowledge neurons and model editing. In DEPN, we introduce a novel method, termed as privacy neuron detector, to locate neurons associated with private information, and then edit these detected privacy neurons by setting their activations to zero. Furthermore, we propose a privacy neuron aggregator dememorize private information in a batch processing manner. Experimental results show that our method can significantly and efficiently reduce the exposure of private data leakage without deteriorating the performance of the model. Additionally, we empirically demonstrate the relationship between model memorization and privacy neurons, from multiple perspectives, including model size, training time, prompts, privacy neuron distribution, illustrating the robustness of our approach.