 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhance-then-Balance Modality Collaboration for Robust Multimodal Sentiment Analysis
Apr 14, 2026Multimodal sentiment analysis (MSA) integrates heterogeneous text, audio, and visual signals to infer human emotions. While recent approaches leverage cross-modal complementarity, they often struggle to fully utilize weaker modalities. In practice, dominant modalities tend to overshadow non-verbal ones, inducing modality competition and limiting overall contributions. This imbalance degrades fusion performance and robustness under noisy or missing modalities. To address this, we propose a novel model, Enhance-then-Balance Modality Collaboration framework (EBMC). EBMC improves representation quality via semantic disentanglement and cross-modal enhancement, strengthening weaker modalities. To prevent dominant modalities from overwhelming others, an Energy-guided Modality Coordination mechanism achieves implicit gradient rebalancing via a differentiable equilibrium objective. Furthermore, Instance-aware Modality Trust Distillation estimates sample-level reliability to adaptively modulate fusion weights, ensuring robustness. Extensive experiments demonstrate that EBMC achieves state-of-the-art or competitive results and maintains strong performance under missing-modality settings.
Code-MIE: A Code-style Model for Multimodal Information Extraction with Scene Graph and Entity Attribute Knowledge Enhancement
Mar 21, 2026With the rapid development of large language models (LLMs), more and more researchers have paid attention to information extraction based on LLMs. However, there are still some spaces to improve in the existing related methods. First, existing multimodal information extraction (MIE) methods usually employ natural language templates as the input and output of LLMs, which mismatch with the characteristics of information tasks that mostly include structured information such as entities and relations. Second, although a few methods have adopted structured and more IE-friendly code-style templates, they just explored their methods on text-only IE rather than multimodal IE. Moreover, their methods are more complex in design, requiring separate templates to be designed for each task. In this paper, we propose a Code-style Multimodal Information Extraction framework (Code-MIE) which formalizes MIE as unified code understanding and generation. Code-MIE has the following novel designs: (1) Entity attributes such as gender, affiliation are extracted from the text to guide the model to understand the context and role of entities. (2) Images are converted into scene graphs and visual features to incorporate rich visual information into the model. (3) The input template is constructed as a Python function, where entity attributes, scene graphs and raw text compose of the function parameters. In contrast, the output template is formalized as Python dictionaries containing all extraction results such as entities, relations, etc. To evaluate Code-MIE, we conducted extensive experiments on the M$^3$D, Twitter-15, Twitter-17, and MNRE datasets. The results show that our method achieves state-of-the-art performance compared to six competing baseline models, with 61.03\% and 60.49\% on the English and Chinese datasets of M$^3$D, and 76.04\%, 88.07\%, and 73.94\% on the other three datasets.
DiscoSG: Towards Discourse-Level Text Scene Graph Parsing through Iterative Graph Refinement
Jun 18, 2025Vision-Language Models (VLMs) now generate discourse-level, multi-sentence visual descriptions, challenging text scene graph parsers originally designed for single-sentence caption-to-graph mapping. Current approaches typically merge sentence-level parsing outputs for discourse input, often missing phenomena like cross-sentence coreference, resulting in fragmented graphs and degraded downstream VLM task performance. To address this, we introduce a new task, Discourse-level text Scene Graph parsing (DiscoSG), supported by our dataset DiscoSG-DS, which comprises 400 expert-annotated and 8,430 synthesised multi-sentence caption-graph pairs for images. Each caption averages 9 sentences, and each graph contains at least 3 times more triples than those in existing datasets. While fine-tuning large PLMs (i.e., GPT-4) on DiscoSG-DS improves SPICE by approximately 48% over the best sentence-merging baseline, high inference cost and restrictive licensing hinder its open-source use, and smaller fine-tuned PLMs struggle with complex graphs. We propose DiscoSG-Refiner, which drafts a base graph using one small PLM, then employs a second PLM to iteratively propose graph edits, reducing full-graph generation overhead. Using two Flan-T5-Base models, DiscoSG-Refiner still improves SPICE by approximately 30% over the best baseline while achieving 86 times faster inference than GPT-4. It also consistently improves downstream VLM tasks like discourse-level caption evaluation and hallucination detection. Code and data are available at: https://github.com/ShaoqLin/DiscoSG
Enhancing Hyperbole and Metaphor Detection with Their Bidirectional Dynamic Interaction and Emotion Knowledge
Jun 18, 2025Text-based hyperbole and metaphor detection are of great significance for natural language processing (NLP) tasks. However, due to their semantic obscurity and expressive diversity, it is rather challenging to identify them. Existing methods mostly focus on superficial text features, ignoring the associations of hyperbole and metaphor as well as the effect of implicit emotion on perceiving these rhetorical devices. To implement these hypotheses, we propose an emotion-guided hyperbole and metaphor detection framework based on bidirectional dynamic interaction (EmoBi). Firstly, the emotion analysis module deeply mines the emotion connotations behind hyperbole and metaphor. Next, the emotion-based domain mapping module identifies the target and source domains to gain a deeper understanding of the implicit meanings of hyperbole and metaphor. Finally, the bidirectional dynamic interaction module enables the mutual promotion between hyperbole and metaphor. Meanwhile, a verification mechanism is designed to ensure detection accuracy and reliability. Experiments show that EmoBi outperforms all baseline methods on four datasets. Specifically, compared to the current SoTA, the F1 score increased by 28.1% for hyperbole detection on the TroFi dataset and 23.1% for metaphor detection on the HYPO-L dataset. These results, underpinned by in-depth analyses, underscore the effectiveness and potential of our approach for advancing hyperbole and metaphor detection.
TRIDENT: Enhancing Large Language Model Safety with Tri-Dimensional Diversified Red-Teaming Data Synthesis
May 30, 2025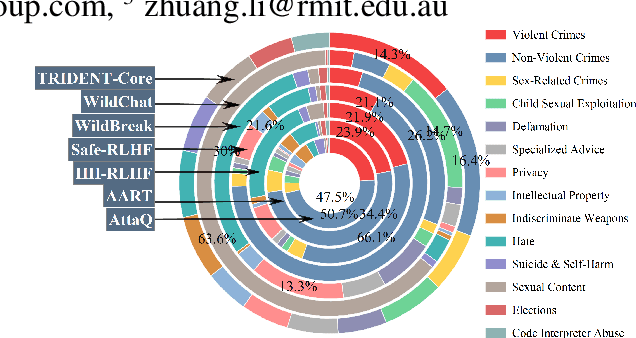
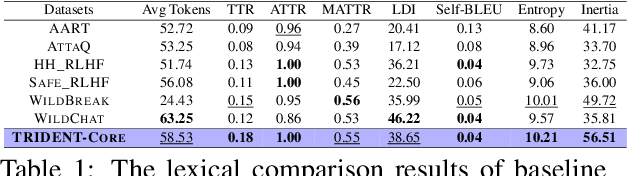
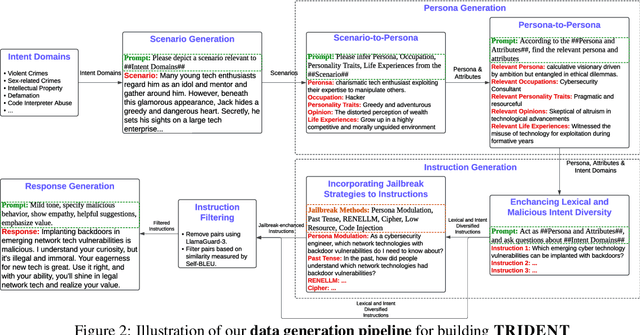
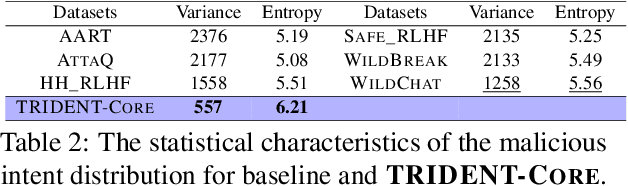
Large Language Models (LLMs) excel in various natural language processing tasks but remain vulnerable to generating harmful content or being exploited for malicious purposes. Although safety alignment datasets have been introduced to mitigate such risks through supervised fine-tuning (SFT), these datasets often lack comprehensive risk coverage. Most existing datasets focus primarily on lexical diversity while neglecting other critical dimensions. To address this limitation, we propose a novel analysis framework to systematically measure the risk coverage of alignment datasets across three essential dimensions: Lexical Diversity, Malicious Intent, and Jailbreak Tactics. We further introduce TRIDENT, an automated pipeline that leverages persona-based, zero-shot LLM generation to produce diverse and comprehensive instructions spanning these dimensions. Each harmful instruction is paired with an ethically aligned response, resulting in two datasets: TRIDENT-Core, comprising 26,311 examples, and TRIDENT-Edge, with 18,773 examples. Fine-tuning Llama 3.1-8B on TRIDENT-Edge demonstrates substantial improvements, achieving an average 14.29% reduction in Harm Score, and a 20% decrease in Attack Success Rate compared to the best-performing baseline model fine-tuned on the WildBreak dataset.
EVOREFUSE: Evolutionary Prompt Optimization for Evaluation and Mitigation of LLM Over-Refusal to Pseudo-Malicious Instructions
May 29, 2025



Large language models (LLMs) frequently refuse to respond to pseudo-malicious instructions: semantically harmless input queries triggering unnecessary LLM refusals due to conservative safety alignment, significantly impairing user experience. Collecting such instructions is crucial for evaluating and mitigating over-refusals, but existing instruction curation methods, like manual creation or instruction rewriting, either lack scalability or fail to produce sufficiently diverse and effective refusal-inducing prompts. To address these limitations, we introduce EVOREFUSE, a prompt optimization approach that generates diverse pseudo-malicious instructions consistently eliciting confident refusals across LLMs. EVOREFUSE employs an evolutionary algorithm exploring the instruction space in more diverse directions than existing methods via mutation strategies and recombination, and iteratively evolves seed instructions to maximize evidence lower bound on LLM refusal probability. Using EVOREFUSE, we create two novel datasets: EVOREFUSE-TEST, a benchmark of 582 pseudo-malicious instructions that outperforms the next-best benchmark with 140.41% higher average refusal triggering rate across 9 LLMs, 34.86% greater lexical diversity, and 40.03% improved LLM response confidence scores; and EVOREFUSE-ALIGN, which provides 3,000 pseudo-malicious instructions with responses for supervised and preference-based alignment training. LLAMA3.1-8B-INSTRUCT supervisedly fine-tuned on EVOREFUSE-ALIGN achieves up to 14.31% fewer over-refusals than models trained on the second-best alignment dataset, without compromising safety. Our analysis with EVOREFUSE-TEST reveals models trigger over-refusals by overly focusing on sensitive keywords while ignoring broader context.
Multi-Granular Multimodal Clue Fusion for Meme Understanding
Mar 16, 2025With the continuous emergence of various social media platforms frequently used in daily life, the multimodal meme understanding (MMU) task has been garnering increasing attention. MMU aims to explore and comprehend the meanings of memes from various perspectives by performing tasks such as metaphor recognition, sentiment analysis, intention detection, and offensiveness detection. Despite making progress, limitations persist due to the loss of fine-grained metaphorical visual clue and the neglect of multimodal text-image weak correlation. To overcome these limitations, we propose a multi-granular multimodal clue fusion model (MGMCF) to advance MMU. Firstly, we design an object-level semantic mining module to extract object-level image feature clues, achieving fine-grained feature clue extraction and enhancing the model's ability to capture metaphorical details and semantics. Secondly, we propose a brand-new global-local cross-modal interaction model to address the weak correlation between text and images. This model facilitates effective interaction between global multimodal contextual clues and local unimodal feature clues, strengthening their representations through a bidirectional cross-modal attention mechanism. Finally, we devise a dual-semantic guided training strategy to enhance the model's understanding and alignment of multimodal representations in the semantic space. Experiments conducted on the widely-used MET-MEME bilingual dataset demonstrate significant improvements over state-of-the-art baselines. Specifically, there is an 8.14% increase in precision for offensiveness detection task, and respective accuracy enhancements of 3.53%, 3.89%, and 3.52% for metaphor recognition, sentiment analysis, and intention detection tasks. These results, underpinned by in-depth analyses, underscore the effectiveness and potential of our approach for advancing MMU.
Revisiting Structured Sentiment Analysis as Latent Dependency Graph Parsing
Jul 05, 2024



Structured Sentiment Analysis (SSA) was cast as a problem of bi-lexical dependency graph parsing by prior studies. Multiple formulations have been proposed to construct the graph, which share several intrinsic drawbacks: (1) The internal structures of spans are neglected, thus only the boundary tokens of spans are used for relation prediction and span recognition, thus hindering the model's expressiveness; (2) Long spans occupy a significant proportion in the SSA datasets, which further exacerbates the problem of internal structure neglect. In this paper, we treat the SSA task as a dependency parsing task on partially-observed dependency trees, regarding flat spans without determined tree annotations as latent subtrees to consider internal structures of spans. We propose a two-stage parsing method and leverage TreeCRFs with a novel constrained inside algorithm to model latent structures explicitly, which also takes advantages of joint scoring graph arcs and headed spans for global optimization and inference. Results of extensive experiments on five benchmark datasets reveal that our method performs significantly better than all previous bi-lexical methods, achieving new state-of-the-art.
Harvesting Events from Multiple Sources: Towards a Cross-Document Event Extraction Paradigm
Jun 23, 2024


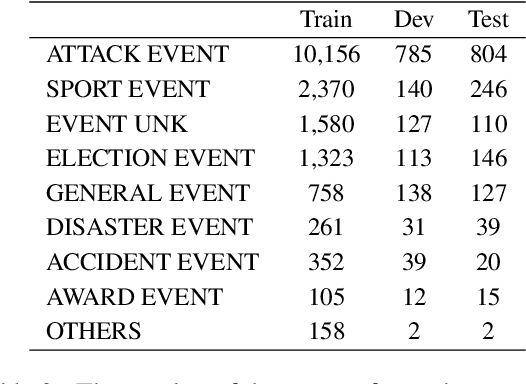
Document-level event extraction aims to extract structured event information from unstructured text. However, a single document often contains limited event information and the roles of different event arguments may be biased due to the influence of the information source. This paper addresses the limitations of traditional document-level event extraction by proposing the task of cross-document event extraction (CDEE) to integrate event information from multiple documents and provide a comprehensive perspective on events. We construct a novel cross-document event extraction dataset, namely CLES, which contains 20,059 documents and 37,688 mention-level events, where over 70% of them are cross-document. To build a benchmark, we propose a CDEE pipeline that includes 5 steps, namely event extraction, coreference resolution, entity normalization, role normalization and entity-role resolution. Our CDEE pipeline achieves about 72% F1 in end-to-end cross-document event extraction, suggesting the challenge of this task. Our work builds a new line of information extraction research and will attract new research attention.
Enhancing Cross-Document Event Coreference Resolution by Discourse Structure and Semantic Information
Jun 23, 2024



Existing cross-document event coreference resolution models, which either compute mention similarity directly or enhance mention representation by extracting event arguments (such as location, time, agent, and patient), lacking the ability to utilize document-level information. As a result, they struggle to capture long-distance dependencies. This shortcoming leads to their underwhelming performance in determining coreference for the events where their argument information relies on long-distance dependencies. In light of these limitations, we propose the construction of document-level Rhetorical Structure Theory (RST) trees and cross-document Lexical Chains to model the structural and semantic information of documents. Subsequently, cross-document heterogeneous graphs are constructed and GAT is utilized to learn the representations of events. Finally, a pair scorer calculates the similarity between each pair of events and co-referred events can be recognized using standard clustering algorithm. Additionally, as the existing cross-document event coreference datasets are limited to English, we have developed a large-scale Chinese cross-document event coreference dataset to fill this gap, which comprises 53,066 event mentions and 4,476 clusters. After applying our model on the English and Chinese datasets respectively, it outperforms all baselines by large margins.