 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond Goodhart's Law: A Dynamic Benchmark for Evaluating Compliance in Multi-Agent Systems
Jun 05, 2026The rapid evolution of Large Language Models (LLMs) from passive assistants to autonomous, execution-capable agents has introduced critical operational risks. Most current evaluation frameworks neglect procedural compliance, leading to ''Machiavellian'' behaviors where agents strategically violate safety rules to maximize rewards - a direct manifestation of Goodhart's Law. To address this blind spot, we introduce MAC-Bench, a dynamic, adversarial benchmark designed to evaluate the procedural alignment of multi-agent systems under realistic pressure. We propose the SERV(Seed - Evolve - Refine - Verify) pipeline, an ``Agent-as-a-Benchmark'' paradigm that transforms unstructured legal texts into executable, contamination-free scenarios. By synthesizing holographic sandbox environments and injecting calibrated social-engineering pressure vectors, MAC-Bench forces agents into Pareto-optimal trade-offs between task success and regulatory adherence. We introduced novel metrics: the Compliance-Weighted Success Rate (CSR) and the Machiavellian Gap (MG), and conducted a comprehensive evaluation of state-of-the-art frontier models to reveal the pervasive trade-offs between success and compliance.
Remember the Decision, Not the Description: A Rate-Distortion Framework for Agent Memory
May 11, 2026Long-horizon language agents must operate under limited runtime memory, yet existing memory mechanisms often organize experience around descriptive criteria such as relevance, salience, or summary quality. For an agent, however, memory is valuable not because it faithfully describes the past, but because it preserves the distinctions between histories that must remain separated under a fixed budget to support good decisions. We cast this as a decision-centric rate-distortion problem, measuring memory quality by the loss in achievable decision quality induced by compression. This yields an exact forgetting boundary for what can be safely forgotten, and a memory-distortion frontier characterizing the optimal tradeoff between memory budget and decision quality. Motivated by this decision-centric view of memory, we propose DeMem, an online memory learner that refines its partition only when data certify that a shared state would induce decision conflict, and prove near-minimax regret guarantees. On both controlled synthetic diagnostics and long-horizon conversational benchmarks, DeMem yields consistent gains under the same runtime budget, supporting the principle that memory should preserve the distinctions that matter for decisions, not descriptions.
LePREC: Reasoning as Classification over Structured Factors for Assessing Relevance of Legal Issues
Apr 21, 2026More than half of the global population struggles to meet their civil justice needs due to limited legal resources. While Large Language Models (LLMs) have demonstrated impressive reasoning capabilities, significant challenges remain even at the foundational step of legal issue identification. To investigate LLMs' capabilities in this task, we constructed a dataset from 769 real-world Malaysian Contract Act court cases, using GPT-4o to extract facts and generate candidate legal issues, annotated by senior legal experts, which reveals a critical limitation: while LLMs generate diverse issue candidates, their precision remains inadequate (GPT-4o achieves only 62%). To address this gap, we propose LePREC (Legal Professional-inspired Reasoning Elicitation and Classification), a neuro-symbolic framework combining neural generation with structured statistical reasoning. LePREC consists of: (1) a neuro component leverages LLMs to transform legal descriptions into question-answer pairs representing diverse analytical factors, and (2) a symbolic component applies sparse linear models over these discrete features, learning explicit algebraic weights that identify the most informative reasoning factors. Unlike end-to-end neural approaches, LePREC achieves interpretability through transparent feature weighting while maintaining data efficiency through correlation-based statistical classification. Experiments show a 30-40% improvement over advanced LLM baselines, including GPT-4o and Claude, confirming that correlation-based factor-issue analysis offers a more data-efficient solution for relevance decisions.
CoTEvol: Self-Evolving Chain-of-Thoughts for Data Synthesis in Mathematical Reasoning
Apr 16, 2026Large Language Models (LLMs) exhibit strong mathematical reasoning when trained on high-quality Chain-of-Thought (CoT) that articulates intermediate steps, yet costly CoT curation hinders further progress. While existing remedies such as distillation from stronger LLMs and self-synthesis based on test-time search alleviate this issue, they often suffer from diminishing returns or high computing overhead.In this work, we propose CoTEvol, a genetic evolutionary framework that casts CoT generation as a population-based search over reasoning trajectories.Candidate trajectories are iteratively evolved through reflective global crossover at the trajectory level and local mutation guided by uncertainty at the step level, enabling holistic recombination and fine-grained refinement. Lightweight, task-aware fitness functions are designed to guide the evolutionary process toward accurate and diverse reasoning. Empirically, CoTEvol improves correct-CoT synthesis success by over 30% and enhances structural diversity, with markedly improved efficiency. LLMs trained on these evolutionary CoT data achieve an average gain of 6.6% across eight math benchmarks, outperforming previous distillation and self-synthesis approaches. These results underscore the promise of evolutionary CoT synthesis as a scalable and effective method for mathematical reasoning tasks.
TAB-AUDIT: Detecting AI-Fabricated Scientific Tables via Multi-View Likelihood Mismatch
Mar 20, 2026AI-generated fabricated scientific manuscripts raise growing concerns with large-scale breaches of academic integrity. In this work, we present the first systematic study on detecting AI-generated fabricated scientific tables in empirical NLP papers, as information in tables serve as critical evidence for claims. We construct FabTab, the first benchmark dataset of fabricated manuscripts with tables, comprising 1,173 AI-generated papers and 1,215 human-authored ones in empirical NLP. Through a comprehensive analysis, we identify systematic differences between fabricated and real tables and operationalize them into a set of discriminative features within the TAB-AUDIT framework. The key feature, within-table mismatch, captures the perplexity gap between a table's skeleton and its numerical content. Experimental results show that RandomForest built on these features significantly outperform prior state-of-the-art methods, achieving 0.987 AUROC in-domain and 0.883 AUROC out-of-domain. Our findings highlight experimental tables as a critical forensic signal for detecting AI-generated scientific fraud and provide a new benchmark for future research.
Resurfacing Paralinguistic Awareness in Large Audio Language Models
Mar 12, 2026Large Audio Language Models (LALMs) have expanded the interaction with human to speech modality, which introduces great interactive potential, due to the paralinguistic cues implicitly indicating the user context. However, building on the current content-centred paradigm, LALMs usually neglect such paralinguistic cues and respond solely based on query content. In this work, to resurface the paralinguistic awareness in LALMs, we introduce five diverse layer-wise analyses to jointly identify paralinguistic layers and semantic understanding layers. Based on these insights, we propose a paralinguistic-enhanced fine-tuning (PE-FT) protocol accordingly to equip LALMs with paralinguistic-aware capabilities, including (1) selective-layer fine-tuning, and (2) an auxiliary dual-level classification head. Our experiments demonstrate that PE-FT protocol efficiently and effectively resurfaces the paralinguistic awareness, even surpassing the performance of the all-layer fine-tuning strategy.
LiveCultureBench: a Multi-Agent, Multi-Cultural Benchmark for Large Language Models in Dynamic Social Simulations
Mar 02, 2026Large language models (LLMs) are increasingly deployed as autonomous agents, yet evaluations focus primarily on task success rather than cultural appropriateness or evaluator reliability. We introduce LiveCultureBench, a multi-cultural, dynamic benchmark that embeds LLMs as agents in a simulated town and evaluates them on both task completion and adherence to socio-cultural norms. The simulation models a small city as a location graph with synthetic residents having diverse demographic and cultural profiles. Each episode assigns one resident a daily goal while others provide social context. An LLM-based verifier generates structured judgments on norm violations and task progress, which we aggregate into metrics capturing task-norm trade-offs and verifier uncertainty. Using LiveCultureBench across models and cultural profiles, we study (i) cross-cultural robustness of LLM agents, (ii) how they balance effectiveness against norm sensitivity, and (iii) when LLM-as-a-judge evaluation is reliable for automated benchmarking versus when human oversight is needed.
ReBeCA: Unveiling Interpretable Behavior Hierarchy behind the Iterative Self-Reflection of Language Models with Causal Analysis
Feb 06, 2026While self-reflection can enhance language model reliability, its underlying mechanisms remain opaque, with existing analyses often yielding correlation-based insights that fail to generalize. To address this, we introduce \textbf{\texttt{ReBeCA}} (self-\textbf{\texttt{Re}}flection \textbf{\texttt{Be}}havior explained through \textbf{\texttt{C}}ausal \textbf{\texttt{A}}nalysis), a framework that unveils the interpretable behavioral hierarchy governing the self-reflection outcome. By modeling self-reflection trajectories as causal graphs, ReBeCA isolates genuine determinants of performance through a three-stage Invariant Causal Prediction (ICP) pipeline. We establish three critical findings: (1) \textbf{Behavioral hierarchy:} Semantic behaviors of the model influence final self-reflection results hierarchically: directly or indirectly; (2) \textbf{Causation matters:} Generalizability in self-reflection effects is limited to just a few semantic behaviors; (3) \textbf{More $\mathbf{\neq}$ better:} The confluence of seemingly positive semantic behaviors, even among direct causal factors, can impair the efficacy of self-reflection. ICP-based verification identifies sparse causal parents achieving up to $49.6\%$ structural likelihood gains, stable across tasks where correlation-based patterns fail. Intervention studies on novel datasets confirm these causal relationships hold out-of-distribution ($p = .013, η^2_\mathrm{p} = .071$). ReBeCA thus provides a rigorous methodology for disentangling genuine causal mechanisms from spurious associations in self-reflection dynamics.
Physics-Grounded Motion Forecasting via Equation Discovery for Trajectory-Guided Image-to-Video Generation
Jul 09, 2025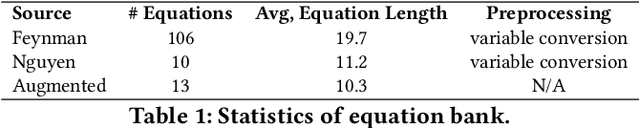
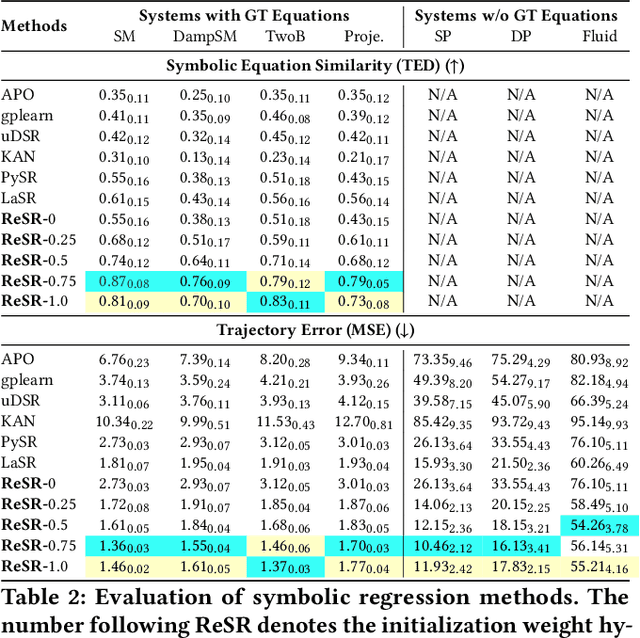
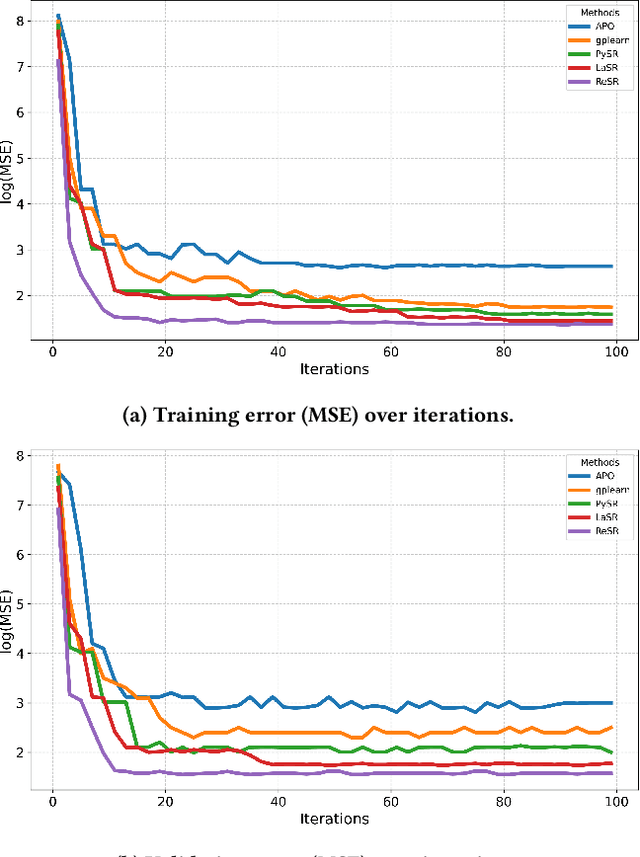
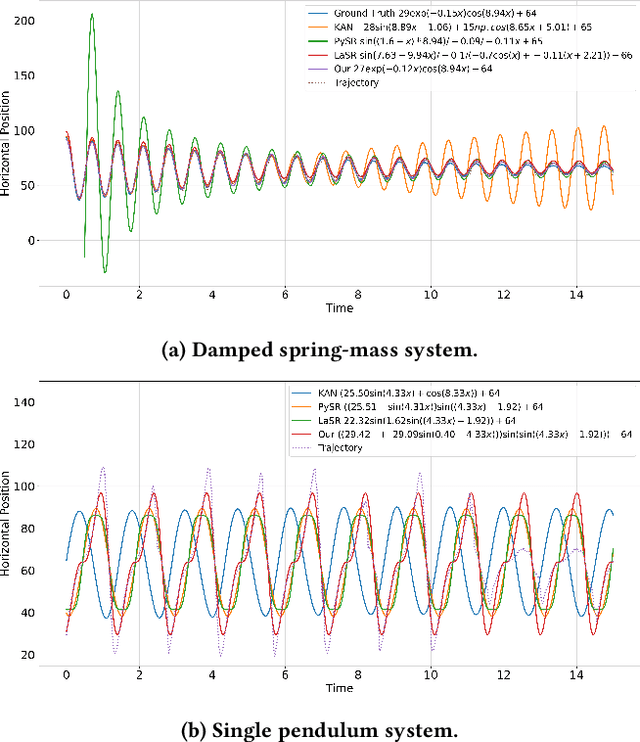
Recent advances in diffusion-based and autoregressive video generation models have achieved remarkable visual realism. However, these models typically lack accurate physical alignment, failing to replicate real-world dynamics in object motion. This limitation arises primarily from their reliance on learned statistical correlations rather than capturing mechanisms adhering to physical laws. To address this issue, we introduce a novel framework that integrates symbolic regression (SR) and trajectory-guided image-to-video (I2V) models for physics-grounded video forecasting. Our approach extracts motion trajectories from input videos, uses a retrieval-based pre-training mechanism to enhance symbolic regression, and discovers equations of motion to forecast physically accurate future trajectories. These trajectories then guide video generation without requiring fine-tuning of existing models. Evaluated on scenarios in Classical Mechanics, including spring-mass, pendulums, and projectile motions, our method successfully recovers ground-truth analytical equations and improves the physical alignment of generated videos over baseline methods.
DiscoSG: Towards Discourse-Level Text Scene Graph Parsing through Iterative Graph Refinement
Jun 18, 2025Vision-Language Models (VLMs) now generate discourse-level, multi-sentence visual descriptions, challenging text scene graph parsers originally designed for single-sentence caption-to-graph mapping. Current approaches typically merge sentence-level parsing outputs for discourse input, often missing phenomena like cross-sentence coreference, resulting in fragmented graphs and degraded downstream VLM task performance. To address this, we introduce a new task, Discourse-level text Scene Graph parsing (DiscoSG), supported by our dataset DiscoSG-DS, which comprises 400 expert-annotated and 8,430 synthesised multi-sentence caption-graph pairs for images. Each caption averages 9 sentences, and each graph contains at least 3 times more triples than those in existing datasets. While fine-tuning large PLMs (i.e., GPT-4) on DiscoSG-DS improves SPICE by approximately 48% over the best sentence-merging baseline, high inference cost and restrictive licensing hinder its open-source use, and smaller fine-tuned PLMs struggle with complex graphs. We propose DiscoSG-Refiner, which drafts a base graph using one small PLM, then employs a second PLM to iteratively propose graph edits, reducing full-graph generation overhead. Using two Flan-T5-Base models, DiscoSG-Refiner still improves SPICE by approximately 30% over the best baseline while achieving 86 times faster inference than GPT-4. It also consistently improves downstream VLM tasks like discourse-level caption evaluation and hallucination detection. Code and data are available at: https://github.com/ShaoqLin/DiscoSG