 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOrdering-based Causal Discovery via Generalized Score Matching
Jan 26, 2026Learning DAG structures from purely observational data remains a long-standing challenge across scientific domains. An emerging line of research leverages the score of the data distribution to initially identify a topological order of the underlying DAG via leaf node detection and subsequently performs edge pruning for graph recovery. This paper extends the score matching framework for causal discovery, which is originally designated for continuous data, and introduces a novel leaf discriminant criterion based on the discrete score function. Through simulated and real-world experiments, we demonstrate that our theory enables accurate inference of true causal orders from observed discrete data and the identified ordering can significantly boost the accuracy of existing causal discovery baselines on nearly all of the settings.
Preserving Clusters in Prompt Learning for Unsupervised Domain Adaptation
Jun 13, 2025Recent approaches leveraging multi-modal pre-trained models like CLIP for Unsupervised Domain Adaptation (UDA) have shown significant promise in bridging domain gaps and improving generalization by utilizing rich semantic knowledge and robust visual representations learned through extensive pre-training on diverse image-text datasets. While these methods achieve state-of-the-art performance across benchmarks, much of the improvement stems from base pseudo-labels (CLIP zero-shot predictions) and self-training mechanisms. Thus, the training mechanism exhibits a key limitation wherein the visual embedding distribution in target domains can deviate from the visual embedding distribution in the pre-trained model, leading to misguided signals from class descriptions. This work introduces a fresh solution to reinforce these pseudo-labels and facilitate target-prompt learning, by exploiting the geometry of visual and text embeddings - an aspect that is overlooked by existing methods. We first propose to directly leverage the reference predictions (from source prompts) based on the relationship between source and target visual embeddings. We later show that there is a strong clustering behavior observed between visual and text embeddings in pre-trained multi-modal models. Building on optimal transport theory, we transform this insight into a novel strategy to enforce the clustering property in text embeddings, further enhancing the alignment in the target domain. Our experiments and ablation studies validate the effectiveness of the proposed approach, demonstrating superior performance and improved quality of target prompts in terms of representation.
ACCESS : A Benchmark for Abstract Causal Event Discovery and Reasoning
Feb 12, 2025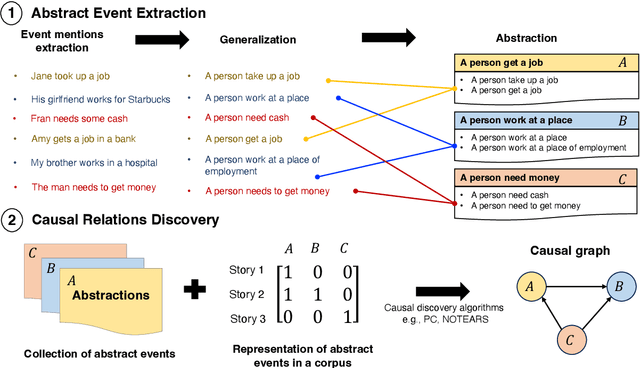

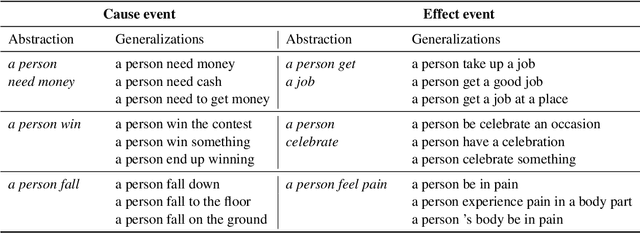
Identifying cause-and-effect relationships is critical to understanding real-world dynamics and ultimately causal reasoning. Existing methods for identifying event causality in NLP, including those based on Large Language Models (LLMs), exhibit difficulties in out-of-distribution settings due to the limited scale and heavy reliance on lexical cues within available benchmarks. Modern benchmarks, inspired by probabilistic causal inference, have attempted to construct causal graphs of events as a robust representation of causal knowledge, where \texttt{CRAB} \citep{romanou2023crab} is one such recent benchmark along this line. In this paper, we introduce \texttt{ACCESS}, a benchmark designed for discovery and reasoning over abstract causal events. Unlike existing resources, \texttt{ACCESS} focuses on causality of everyday life events on the abstraction level. We propose a pipeline for identifying abstractions for event generalizations from \texttt{GLUCOSE} \citep{mostafazadeh-etal-2020-glucose}, a large-scale dataset of implicit commonsense causal knowledge, from which we subsequently extract $1,4$K causal pairs. Our experiments highlight the ongoing challenges of using statistical methods and/or LLMs for automatic abstraction identification and causal discovery in NLP. Nonetheless, we demonstrate that the abstract causal knowledge provided in \texttt{ACCESS} can be leveraged for enhancing QA reasoning performance in LLMs.
Diversity-Aware Agnostic Ensemble of Sharpness Minimizers
Mar 19, 2024



There has long been plenty of theoretical and empirical evidence supporting the success of ensemble learning. Deep ensembles in particular take advantage of training randomness and expressivity of individual neural networks to gain prediction diversity, ultimately leading to better generalization, robustness and uncertainty estimation. In respect of generalization, it is found that pursuing wider local minima result in models being more robust to shifts between training and testing sets. A natural research question arises out of these two approaches as to whether a boost in generalization ability can be achieved if ensemble learning and loss sharpness minimization are integrated. Our work investigates this connection and proposes DASH - a learning algorithm that promotes diversity and flatness within deep ensembles. More concretely, DASH encourages base learners to move divergently towards low-loss regions of minimal sharpness. We provide a theoretical backbone for our method along with extensive empirical evidence demonstrating an improvement in ensemble generalizability.
Optimal Transport for Structure Learning Under Missing Data
Feb 23, 2024



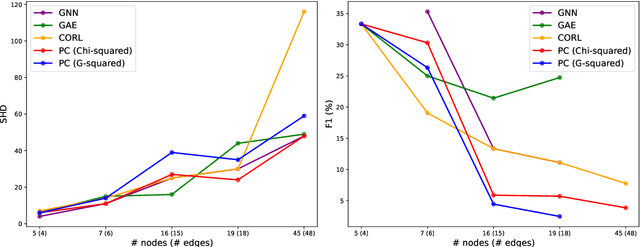
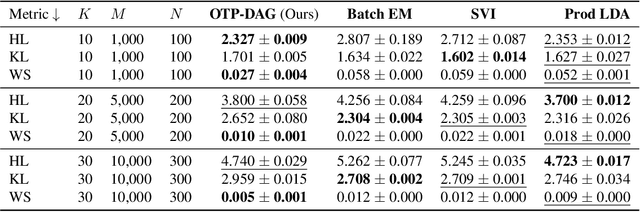
Causal discovery in the presence of missing data introduces a chicken-and-egg dilemma. While the goal is to recover the true causal structure, robust imputation requires considering the dependencies or preferably causal relations among variables. Merely filling in missing values with existing imputation methods and subsequently applying structure learning on the complete data is empirical shown to be sub-optimal. To this end, we propose in this paper a score-based algorithm, based on optimal transport, for learning causal structure from missing data. This optimal transport viewpoint diverges from existing score-based approaches that are dominantly based on EM. We project structure learning as a density fitting problem, where the goal is to find the causal model that induces a distribution of minimum Wasserstein distance with the distribution over the observed data. Through extensive simulations and real-data experiments, our framework is shown to recover the true causal graphs more effectively than the baselines in various simulations and real-data experiments. Empirical evidences also demonstrate the superior scalability of our approach, along with the flexibility to incorporate any off-the-shelf causal discovery methods for complete data.
OMPGPT: A Generative Pre-trained Transformer Model for OpenMP
Jan 28, 2024Large language models (LLMs), as epitomized by models like ChatGPT, have revolutionized the field of natural language processing (NLP). Along with this trend, code-based large language models such as StarCoder, WizardCoder, and CodeLlama have emerged, trained extensively on vast repositories of code data. Yet, inherent in their design, these models primarily focus on generative tasks like code generation, code completion, and comment generation, and general support for multiple programming languages. While the generic abilities of code LLMs are useful for many programmers, the area of high-performance computing (HPC) has a narrower set of requirements that make a smaller and more domain-specific LM a smarter choice. This paper introduces OMPGPT, a novel model meticulously designed to harness the inherent strengths of language models for OpenMP pragma generation. Furthermore, we adopt and adapt prompt engineering techniques from the NLP domain to create chain-of-OMP, an innovative strategy designed to enhance OMPGPT's effectiveness. Our extensive evaluations demonstrate that OMPGPT outperforms existing large language models specialized in OpenMP tasks and maintains a notably smaller size, aligning it more closely with the typical hardware constraints of HPC environments. We consider our contribution as a pivotal bridge, connecting the advantage of language models with the specific demands of HPC tasks. The success of OMPGPT lays a solid foundation, suggesting its potential applicability and adaptability to a wider range of HPC tasks, thereby opening new avenues in the field of computational efficiency and effectiveness.
Learning Directed Graphical Models with Optimal Transport
May 25, 2023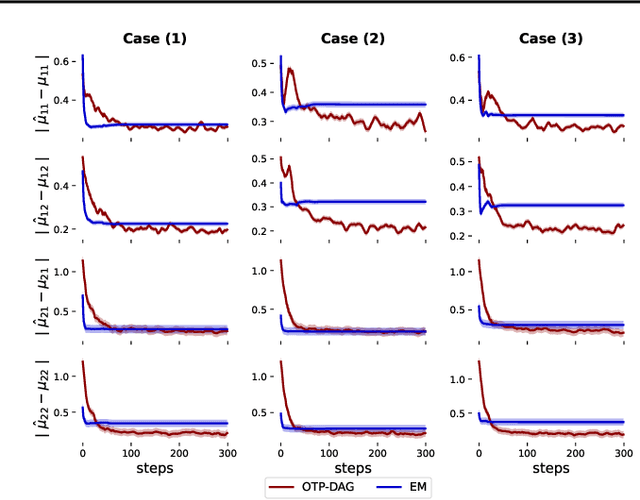
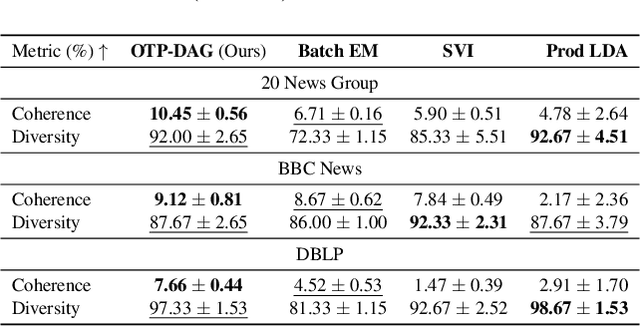
Estimating the parameters of a probabilistic directed graphical model from incomplete data remains a long-standing challenge. This is because, in the presence of latent variables, both the likelihood function and posterior distribution are intractable without further assumptions about structural dependencies or model classes. While existing learning methods are fundamentally based on likelihood maximization, here we offer a new view of the parameter learning problem through the lens of optimal transport. This perspective licenses a framework that operates on many directed graphs without making unrealistic assumptions on the posterior over the latent variables or resorting to black-box variational approximations. We develop a theoretical framework and support it with extensive empirical evidence demonstrating the flexibility and versatility of our approach. Across experiments, we show that not only can our method recover the ground-truth parameters but it also performs competitively on downstream applications, notably the non-trivial task of discrete representation learning.
Learning to Counter: Stochastic Feature-based Learning for Diverse Counterfactual Explanations
Sep 27, 2022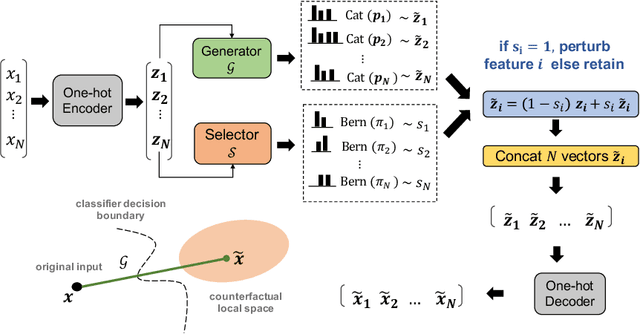

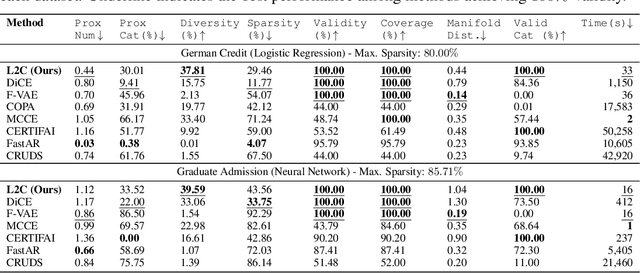
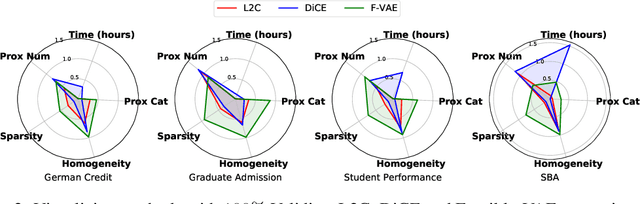
Interpretable machine learning seeks to understand the reasoning process of complex black-box systems that are long notorious for lack of explainability. One growing interpreting approach is through counterfactual explanations, which go beyond why a system arrives at a certain decision to further provide suggestions on what a user can do to alter the outcome. A counterfactual example must be able to counter the original prediction from the black-box classifier, while also satisfying various constraints for practical applications. These constraints exist at trade-offs between one and another presenting radical challenges to existing works. To this end, we propose a stochastic learning-based framework that effectively balances the counterfactual trade-offs. The framework consists of a generation and a feature selection module with complementary roles: the former aims to model the distribution of valid counterfactuals whereas the latter serves to enforce additional constraints in a way that allows for differentiable training and amortized optimization. We demonstrate the effectiveness of our method in generating actionable and plausible counterfactuals that are more diverse than the existing methods and particularly in a more efficient manner than counterparts of the same capacity.
Memory-Augmented Graph Neural Networks: A Neuroscience Perspective
Sep 22, 2022

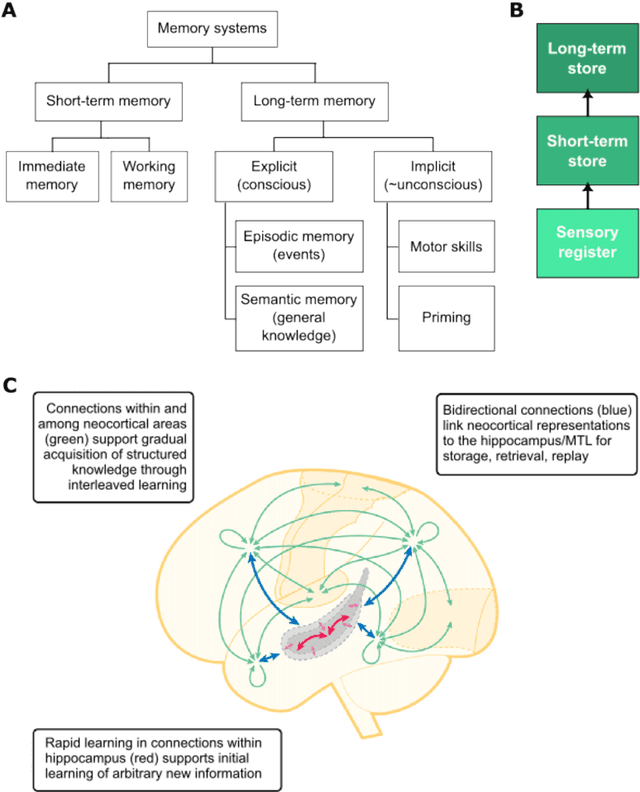
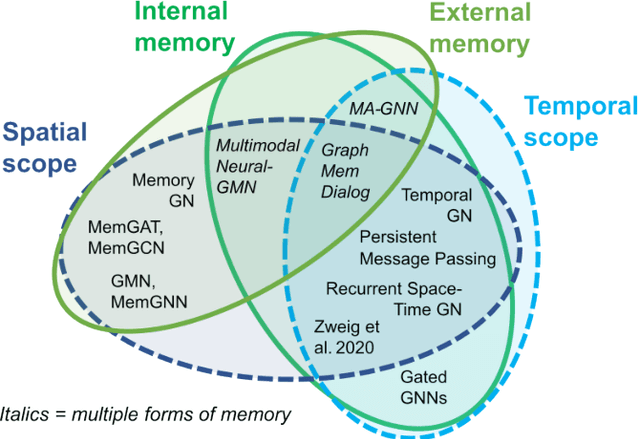
Graph neural networks (GNNs) have been extensively used for many domains where data are represented as graphs, including social networks, recommender systems, biology, chemistry, etc. Recently, the expressive power of GNNs has drawn much interest. It has been shown that, despite the promising empirical results achieved by GNNs for many applications, there are some limitations in GNNs that hinder their performance for some tasks. For example, since GNNs update node features mainly based on local information, they have limited expressive power in capturing long-range dependencies among nodes in graphs. To address some of the limitations of GNNs, several recent works started to explore augmenting GNNs with memory for improving their expressive power in the relevant tasks. In this paper, we provide a comprehensive review of the existing literature of memory-augmented GNNs. We review these works through the lens of psychology and neuroscience, which has established multiple memory systems and mechanisms in biological brains. We propose a taxonomy of the memory GNN works, as well as a set of criteria for comparing the memory mechanisms. We also provide critical discussions on the limitations of these works. Finally, we discuss the challenges and future directions for this area.
An Additive Instance-Wise Approach to Multi-class Model Interpretation
Jul 07, 2022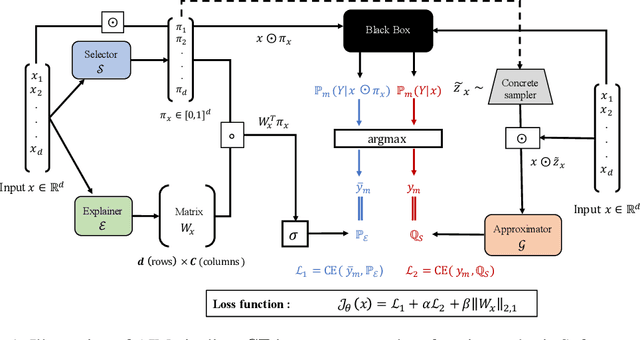
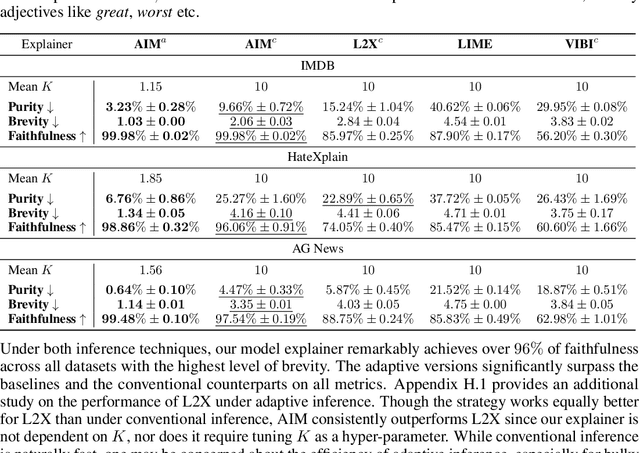
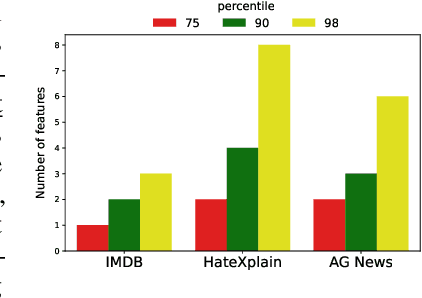

Interpretable machine learning offers insights into what factors drive a certain prediction of a black-box system and whether to trust it for high-stakes decisions or large-scale deployment. Existing methods mainly focus on selecting explanatory input features, which follow either locally additive or instance-wise approaches. Additive models use heuristically sampled perturbations to learn instance-specific explainers sequentially. The process is thus inefficient and susceptible to poorly-conditioned samples. Meanwhile, instance-wise techniques directly learn local sampling distributions and can leverage global information from other inputs. However, they can only interpret single-class predictions and suffer from inconsistency across different settings, due to a strict reliance on a pre-defined number of features selected. This work exploits the strengths of both methods and proposes a global framework for learning local explanations simultaneously for multiple target classes. We also propose an adaptive inference strategy to determine the optimal number of features for a specific instance. Our model explainer significantly outperforms additive and instance-wise counterparts on faithfulness while achieves high level of brevity on various data sets and black-box model architectures.