 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNOMAD: Generating Embeddings for Massive Distributed Graphs
Apr 10, 2026Successful machine learning on graphs or networks requires embeddings that not only represent nodes and edges as low-dimensional vectors but also preserve the graph structure. Established methods for generating embeddings require flexible exploration of the entire graph through repeated use of random walks that capture graph structure with samples of nodes and edges. These methods create scalability challenges for massive graphs with millions-to-billions of edges because single-node solutions have inadequate memory and processing capabilities. We present NOMAD, a distributed-memory graph embedding framework using the Message Passing Interface (MPI) for distributed graphs. NOMAD implements proximity-based models proposed in the widely popular LINE (Large-scale Information Network Embedding) algorithm. We propose several practical trade-offs to improve the scalability and communication overheads confronted by irregular and distributed graph embedding methods, catering to massive-scale graphs arising in web and science domains. NOMAD demonstrates median speedups of 10/100x on CPU-based NERSC Perlmutter cluster relative to the popular reference implementations of multi-threaded LINE and node2vec, 35-76x over distributed PBG, and competitive embedding quality relative to LINE, node2vec, and GraphVite, while yielding 12-370x end-to-end speedups on real-world graphs.
Communication-free Sampling and 4D Hybrid Parallelism for Scalable Mini-batch GNN Training
Apr 03, 2026Graph neural networks (GNNs) are widely used for learning on graph datasets derived from various real-world scenarios. Learning from extremely large graphs requires distributed training, and mini-batching with sampling is a popular approach for parallelizing GNN training. Existing distributed mini-batch approaches have significant performance bottlenecks due to expensive sampling methods and limited scaling when using data parallelism. In this work, we present ScaleGNN, a 4D parallel framework for scalable mini-batch GNN training that combines communication-free distributed sampling, 3D parallel matrix multiplication (PMM), and data parallelism. ScaleGNN introduces a uniform vertex sampling algorithm, enabling each process (GPU device) to construct its local mini-batch, i.e., subgraph partitions without any inter-process communication. 3D PMM enables scaling mini-batch training to much larger GPU counts than vanilla data parallelism with significantly lower communication overheads. We also present additional optimizations to overlap sampling with training, reduce communication overhead by sending data in lower precision, kernel fusion, and communication-computation overlap. We evaluate ScaleGNN on five graph datasets and demonstrate strong scaling up to 2048 GPUs on Perlmutter, 2048 GCDs on Frontier, and 1024 GPUs on Tuolumne. On Perlmutter, ScaleGNN achieves 3.5x end-to-end training speedup over the SOTA baseline on ogbn-products.
OptiML: An End-to-End Framework for Program Synthesis and CUDA Kernel Optimization
Feb 12, 2026Generating high-performance CUDA kernels remains challenging due to the need to navigate a combinatorial space of low-level transformations under noisy and expensive hardware feedback. Although large language models can synthesize functionally correct CUDA code, achieving competitive performance requires systematic exploration and verification of optimization choices. We present OptiML, an end-to-end framework that maps either natural-language intent or input CUDA code to performance-optimized CUDA kernels by formulating kernel optimization as search under verification. OptiML consists of two decoupled stages. When the input is natural language, a Mixture-of-Thoughts generator (OptiML-G) acts as a proposal policy over kernel implementation strategies, producing an initial executable program. A search-based optimizer (OptiML-X) then refines either synthesized or user-provided kernels using Monte Carlo Tree Search over LLM-driven edits, guided by a hardware-aware reward derived from profiler feedback. Each candidate transformation is compiled, verified, and profiled with Nsight Compute, and evaluated by a composite objective that combines runtime with hardware bottleneck proxies and guardrails against regressions. We evaluate OptiML in both synthesis-and-optimize and optimization-only settings on a diverse suite of CUDA kernels. Results show that OptiML consistently discovers verified performance improvements over strong LLM baselines and produces interpretable optimization trajectories grounded in profiler evidence.
Split-on-Share: Mixture of Sparse Experts for Task-Agnostic Continual Learning
Jan 24, 2026Continual learning in Large Language Models (LLMs) is hindered by the plasticity-stability dilemma, where acquiring new capabilities often leads to catastrophic forgetting of previous knowledge. Existing methods typically treat parameters uniformly, failing to distinguish between specific task knowledge and shared capabilities. We introduce Mixture of Sparse Experts for Task-Agnostic Continual Learning, referred to as SETA, a framework that resolves the plasticity-stability conflict by decomposing the model into modular subspaces. Unlike standard updates, where tasks compete for the same parameters, SETA separates knowledge into unique experts, designed to isolate task-specific patterns, and shared experts, responsible for capturing common features. This structure is maintained through elastic weight anchoring, which protects critical shared knowledge and enables a unified gating network to automatically retrieve the correct expert combination for each task during inference. Extensive experiments across diverse domain-specific and general benchmarks demonstrate that SETA consistently outperforms state-of-the-art parameter-efficient fine-tuning-based continual learning methods.
AgenticPruner: MAC-Constrained Neural Network Compression via LLM-Driven Strategy Search
Jan 18, 2026Neural network pruning remains essential for deploying deep learning models on resource-constrained devices, yet existing approaches primarily target parameter reduction without directly controlling computational cost. This yields unpredictable inference latency in deployment scenarios where strict Multiply-Accumulate (MAC) operation budgets must be met. We propose AgenticPruner, a framework utilizing large language models to achieve MAC-constrained optimization through iterative strategy learning. Our approach coordinates three specialized agents: a Profiling Agent that analyzes model architecture and MAC distributions, a Master Agent that orchestrates the workflow with divergence monitoring, and an Analysis Agent powered by Claude 3.5 Sonnet that learns optimal strategies from historical attempts. Through in-context learning, the Analysis Agent improves convergence success rate from 48% to 71% compared to grid search. Building upon isomorphic pruning's graph-based structural grouping, our method adds context-aware adaptation by analyzing patterns across pruning iterations, enabling automatic convergence to target MAC budgets within user-defined tolerance bands. We validate our framework on ImageNet-1K across ResNet, ConvNeXt, and DeiT architectures. On CNNs, our approach achieves MAC targeting while maintaining or improving accuracy: ResNet-50 reaches 1.77G MACs with 77.04% accuracy (+0.91% vs baseline); ResNet-101 achieves 4.22G MACs with 78.94% accuracy (+1.56% vs baseline). For ConvNeXt-Small, pruning to 8.17G MACs yields 1.41x GPU and 1.07x CPU speedup with 45% parameter reduction. On Vision Transformers, we demonstrate MAC-budget compliance within user-defined tolerance bands (typically +1% to +5% overshoot, -5% to -15% undershoot), establishing feasibility for deployment scenarios requiring strict computational guarantees.
ZeroDVFS: Zero-Shot LLM-Guided Core and Frequency Allocation for Embedded Platforms
Jan 13, 2026Dynamic voltage and frequency scaling (DVFS) and task-to-core allocation are critical for thermal management and balancing energy and performance in embedded systems. Existing approaches either rely on utilization-based heuristics that overlook stall times, or require extensive offline profiling for table generation, preventing runtime adaptation. We propose a model-based hierarchical multi-agent reinforcement learning (MARL) framework for thermal- and energy-aware scheduling on multi-core platforms. Two collaborative agents decompose the exponential action space, achieving 358ms latency for subsequent decisions. First decisions require 3.5 to 8.0s including one-time LLM feature extraction. An accurate environment model leverages regression techniques to predict thermal dynamics and performance states. When combined with LLM-extracted semantic features, the environment model enables zero-shot deployment for new workloads on trained platforms by generating synthetic training data without requiring workload-specific profiling samples. We introduce LLM-based semantic feature extraction that characterizes OpenMP programs through 13 code-level features without execution. The Dyna-Q-inspired framework integrates direct reinforcement learning with model-based planning, achieving 20x faster convergence than model-free methods. Experiments on BOTS and PolybenchC benchmarks across NVIDIA Jetson TX2, Jetson Orin NX, RubikPi, and Intel Core i7 demonstrate 7.09x better energy efficiency and 4.0x better makespan than Linux ondemand governor. First-decision latency is 8,300x faster than table-based profiling, enabling practical deployment in dynamic embedded systems.
HiDVFS: A Hierarchical Multi-Agent DVFS Scheduler for OpenMP DAG Workloads
Jan 10, 2026With advancements in multicore embedded systems, leakage power, exponentially tied to chip temperature, has surpassed dynamic power consumption. Energy-aware solutions use dynamic voltage and frequency scaling (DVFS) to mitigate overheating in performance-intensive scenarios, while software approaches allocate high-utilization tasks across core configurations in parallel systems to reduce power. However, existing heuristics lack per-core frequency monitoring, failing to address overheating from uneven core activity, and task assignments without detailed profiling overlook irregular execution patterns. We target OpenMP DAG workloads. Because makespan, energy, and thermal goals often conflict within a single benchmark, this work prioritizes performance (makespan) while reporting energy and thermal as secondary outcomes. To overcome these issues, we propose HiDVFS (a hierarchical multi-agent, performance-aware DVFS scheduler) for parallel systems that optimizes task allocation based on profiling data, core temperatures, and makespan-first objectives. It employs three agents: one selects cores and frequencies using profiler data, another manages core combinations via temperature sensors, and a third sets task priorities during resource contention. A makespan-focused reward with energy and temperature regularizers estimates future states and enhances sample efficiency. Experiments on the NVIDIA Jetson TX2 using the BOTS suite (9 benchmarks) compare HiDVFS against state-of-the-art approaches. With multi-seed validation (seeds 42, 123, 456), HiDVFS achieves the best finetuned performance with 4.16 plus/minus 0.58s average makespan (L10), representing a 3.44x speedup over GearDVFS (14.32 plus/minus 2.61s) and 50.4% energy reduction (63.7 kJ vs 128.4 kJ). Across all BOTS benchmarks, HiDVFS achieves an average 3.95x speedup and 47.1% energy reduction.
GraphPerf-RT: A Graph-Driven Performance Model for Hardware-Aware Scheduling of OpenMP Codes
Dec 12, 2025


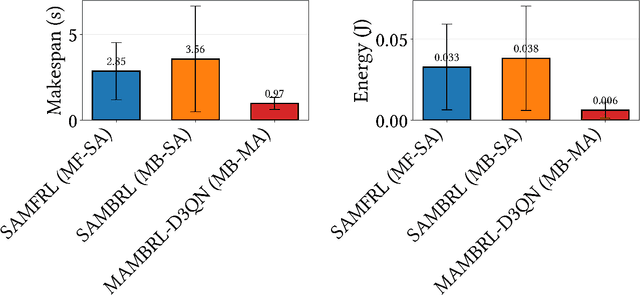
Performance prediction for OpenMP workloads on heterogeneous embedded SoCs is challenging due to complex interactions between task DAG structure, control-flow irregularity, cache and branch behavior, and thermal dynamics; classical heuristics struggle under workload irregularity, tabular regressors discard structural information, and model-free RL risks overheating resource-constrained devices. We introduce GraphPerf-RT, the first surrogate that unifies task DAG topology, CFG-derived code semantics, and runtime context (per-core DVFS, thermal state, utilization) in a heterogeneous graph representation with typed edges encoding precedence, placement, and contention. Multi-task evidential heads predict makespan, energy, cache and branch misses, and utilization with calibrated uncertainty (Normal-Inverse-Gamma), enabling risk-aware scheduling that filters low-confidence rollouts. We validate GraphPerf-RT on three embedded ARM platforms (Jetson TX2, Jetson Orin NX, RUBIK Pi), achieving R^2 > 0.95 with well-calibrated uncertainty (ECE < 0.05). To demonstrate end-to-end scheduling utility, we integrate the surrogate with four RL methods on Jetson TX2: single-agent model-free (SAMFRL), single-agent model-based (SAMBRL), multi-agent model-free (MAMFRL-D3QN), and multi-agent model-based (MAMBRL-D3QN). Experiments across 5 seeds (200 episodes each) show that MAMBRL-D3QN with GraphPerf-RT as the world model achieves 66% makespan reduction (0.97 +/- 0.35s) and 82% energy reduction (0.006 +/- 0.005J) compared to model-free baselines, demonstrating that accurate, uncertainty-aware surrogates enable effective model-based planning on thermally constrained embedded systems.
OMPILOT: Harnessing Transformer Models for Auto Parallelization to Shared Memory Computing Paradigms
Nov 11, 2025Recent advances in large language models (LLMs) have significantly accelerated progress in code translation, enabling more accurate and efficient transformation across programming languages. While originally developed for natural language processing, LLMs have shown strong capabilities in modeling programming language syntax and semantics, outperforming traditional rule-based systems in both accuracy and flexibility. These models have streamlined cross-language conversion, reduced development overhead, and accelerated legacy code migration. In this paper, we introduce OMPILOT, a novel domain-specific encoder-decoder transformer tailored for translating C++ code into OpenMP, enabling effective shared-memory parallelization. OMPILOT leverages custom pre-training objectives that incorporate the semantics of parallel constructs and combines both unsupervised and supervised learning strategies to improve code translation robustness. Unlike previous work that focused primarily on loop-level transformations, OMPILOT operates at the function level to capture a wider semantic context. To evaluate our approach, we propose OMPBLEU, a novel composite metric specifically crafted to assess the correctness and quality of OpenMP parallel constructs, addressing limitations in conventional translation metrics.
VeriMoA: A Mixture-of-Agents Framework for Spec-to-HDL Generation
Oct 31, 2025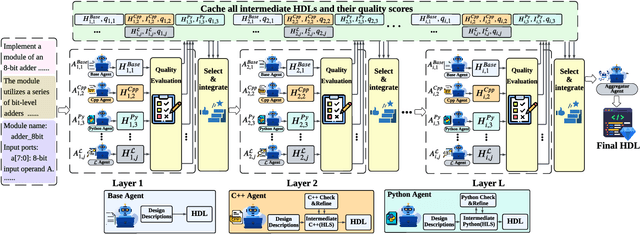
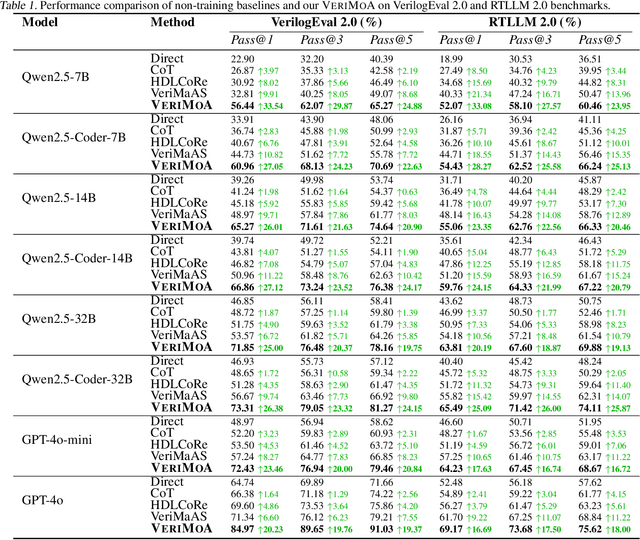
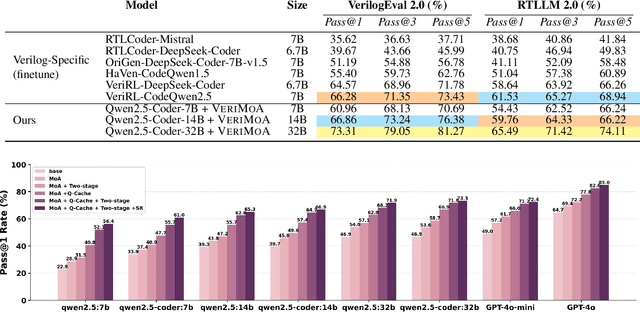
Automation of Register Transfer Level (RTL) design can help developers meet increasing computational demands. Large Language Models (LLMs) show promise for Hardware Description Language (HDL) generation, but face challenges due to limited parametric knowledge and domain-specific constraints. While prompt engineering and fine-tuning have limitations in knowledge coverage and training costs, multi-agent architectures offer a training-free paradigm to enhance reasoning through collaborative generation. However, current multi-agent approaches suffer from two critical deficiencies: susceptibility to noise propagation and constrained reasoning space exploration. We propose VeriMoA, a training-free mixture-of-agents (MoA) framework with two synergistic innovations. First, a quality-guided caching mechanism to maintain all intermediate HDL outputs and enables quality-based ranking and selection across the entire generation process, encouraging knowledge accumulation over layers of reasoning. Second, a multi-path generation strategy that leverages C++ and Python as intermediate representations, decomposing specification-to-HDL translation into two-stage processes that exploit LLM fluency in high-resource languages while promoting solution diversity. Comprehensive experiments on VerilogEval 2.0 and RTLLM 2.0 benchmarks demonstrate that VeriMoA achieves 15--30% improvements in Pass@1 across diverse LLM backbones, especially enabling smaller models to match larger models and fine-tuned alternatives without requiring costly training.