 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAI-PROPELLER: Warehouse-Scale Interprocedural Code Layout Optimization with AlphaEvolve
May 28, 2026Post-link optimizers (PLOs) such as Propeller and BOLT have demonstrated that precise, profile-guided code layout can extract significant performance gains from heavily optimized binaries. However, these systems are currently restricted to intraprocedural techniques, leaving the global potential of interprocedural layout largely untapped. Interprocedural code layout is historically difficult due to a combinatorially intractable search space and complex call-return semantics that are challenging to model. Consequently, the performance potential of fine-grained interprocedural layout remains unproven in practice. AI-PROPELLER uses Magellan, an agentic workflow that evolves the compiler heuristic in Propeller into a fine-grained interprocedural optimizer and fine-tunes the resulting policy hyperparameters. To ensure high-fidelity, we move away from approximate static cost models and the agentic workflow generates multiple layout variants that are executed on actual hardware to measure real performance counters, providing a precise reward signal for the evolutionary loop. AI-PROPELLER has been evaluated on several benchmarks including large warehouse-scale applications and experiments show performance improvements of 0.23% to 1.6% optimized with state-of-the-art FDO and PLO which is significant for real-world binaries. This is the first time ever that large warehouse-scale applications in industrial settings have been optimized with fine-grained interprocedural code layout.
How Far Can Disaggregation Go? A Design-Space Exploration of Attention-FFN Disaggregation for Efficient MoE LLM Serving
May 27, 2026Modern large language model (LLM) inference has progressively disaggregated to keep pace with growing model sizes and tight TTFT and TPOT service-level objectives: from chunked-prefill aggregation, to prefill-decode (P/D) disaggregation, and most recently to operator-level Attention-FFN Disaggregation (AFD). This trend is especially important for mixture-of-experts (MoE) models, where memory-bound attention, compute-intensive expert FFNs, and MoE dispatch/combine communication create distinct resource demands. AFD further exposes this heterogeneity by placing attention and MoE-FFN execution on separate GPU groups. Each level of disaggregation deepens the scheduling design space across workload characteristics, resource allocation, and interconnect topology, raising the central question: when does each level actually pay off? We systematically characterize this trade-off for MoE inference across realistic workloads spanning input/output sequence lengths, prefix-KV reuse, and per-user latency constraints. Using chunked-prefill and P/D disaggregation as baselines, we study the benefits and limits of AFD at scale through a framework that fuses on-device kernel measurements with high-fidelity network simulation. Under strict TTFT/TPOT SLOs, AFD sustains around 4k tokens/s of system throughput on DeepSeek-V3.2 across chat, coding, and agentic-coding workloads, where non-AFD deployments are infeasible. We distill concrete takeaways for jointly optimizing throughput and interactivity, including how to partition attention and FFN across GPUs as a function of workload and model architecture, providing design principles for current rack- and cluster-scale deployments as well as future disaggregated AI infrastructure.
ParEVO: Synthesizing Code for Irregular Data: High-Performance Parallelism through Agentic Evolution
Mar 03, 2026The transition from sequential to parallel computing is essential for modern high-performance applications but is hindered by the steep learning curve of concurrent programming. This challenge is magnified for irregular data structures (such as sparse graphs, unbalanced trees, and non-uniform meshes) where static scheduling fails and data dependencies are unpredictable. Current Large Language Models (LLMs) often fail catastrophically on these tasks, generating code plagued by subtle race conditions, deadlocks, and sub-optimal scaling. We bridge this gap with ParEVO, a framework designed to synthesize high-performance parallel algorithms for irregular data. Our contributions include: (1) The Parlay-Instruct Corpus, a curated dataset of 13,820 tasks synthesized via a "Critic-Refine" pipeline that explicitly filters for empirically performant algorithms that effectively utilize Work-Span parallel primitives; (2) specialized DeepSeek, Qwen, and Gemini models fine-tuned to align probabilistic generation with the rigorous semantics of the ParlayLib library; and (3) an Evolutionary Coding Agent (ECA) that improves the "last mile" of correctness by iteratively repairing code using feedback from compilers, dynamic race detectors, and performance profilers. On the ParEval benchmark, ParEVO achieves an average 106x speedup (with a maximum of 1103x) across the suite, and a robust 13.6x speedup specifically on complex irregular graph problems, outperforming state-of-the-art commercial models. Furthermore, our evolutionary approach matches state-of-the-art expert human baselines, achieving up to a 4.1x speedup on specific highly-irregular kernels. Source code and datasets are available at https://github.com/WildAlg/ParEVO.
Magellan: Autonomous Discovery of Novel Compiler Optimization Heuristics with AlphaEvolve
Jan 28, 2026Modern compilers rely on hand-crafted heuristics to guide optimization passes. These human-designed rules often struggle to adapt to the complexity of modern software and hardware and lead to high maintenance burden. To address this challenge, we present Magellan, an agentic framework that evolves the compiler pass itself by synthesizing executable C++ decision logic. Magellan couples an LLM coding agent with evolutionary search and autotuning in a closed loop of generation, evaluation on user-provided macro-benchmarks, and refinement, producing compact heuristics that integrate directly into existing compilers. Across several production optimization tasks, Magellan discovers policies that match or surpass expert baselines. In LLVM function inlining, Magellan synthesizes new heuristics that outperform decades of manual engineering for both binary-size reduction and end-to-end performance. In register allocation, it learns a concise priority rule for live-range processing that matches intricate human-designed policies on a large-scale workload. We also report preliminary results on XLA problems, demonstrating portability beyond LLVM with reduced engineering effort.
OPTIMA: Optimal One-shot Pruning for LLMs via Quadratic Programming Reconstruction
Dec 15, 2025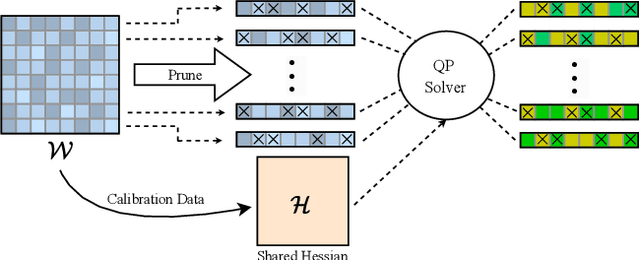
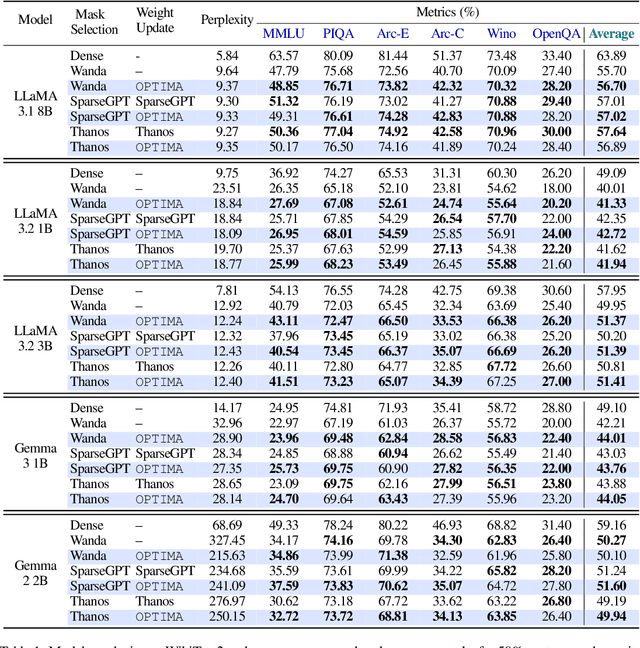
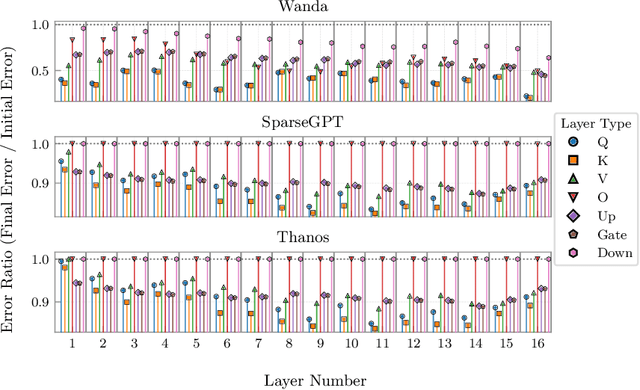
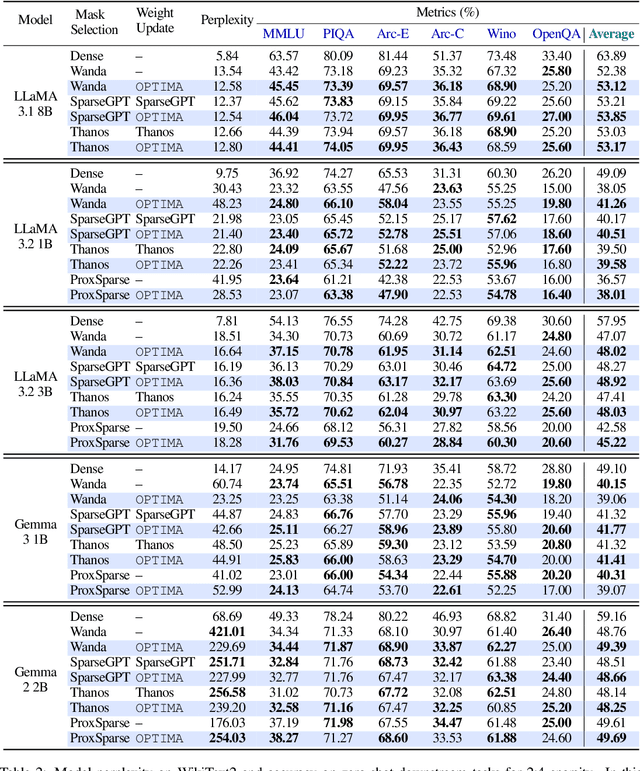
Post-training model pruning is a promising solution, yet it faces a trade-off: simple heuristics that zero weights are fast but degrade accuracy, while principled joint optimization methods recover accuracy but are computationally infeasible at modern scale. One-shot methods such as SparseGPT offer a practical trade-off in optimality by applying efficient, approximate heuristic weight updates. To close this gap, we introduce OPTIMA, a practical one-shot post-training pruning method that balances accuracy and scalability. OPTIMA casts layer-wise weight reconstruction after mask selection as independent, row-wise Quadratic Programs (QPs) that share a common layer Hessian. Solving these QPs yields the per-row globally optimal update with respect to the reconstruction objective given the estimated Hessian. The shared-Hessian structure makes the problem highly amenable to batching on accelerators. We implement an accelerator-friendly QP solver that accumulates one Hessian per layer and solves many small QPs in parallel, enabling one-shot post-training pruning at scale on a single accelerator without fine-tuning. OPTIMA integrates with existing mask selectors and consistently improves zero-shot performance across multiple LLM families and sparsity regimes, yielding up to 3.97% absolute accuracy improvement. On an NVIDIA H100, OPTIMA prunes a 8B-parameter transformer end-to-end in 40 hours with 60GB peak memory. Together, these results set a new state-of-the-art accuracy-efficiency trade-offs for one-shot post-training pruning.
SWE-fficiency: Can Language Models Optimize Real-World Repositories on Real Workloads?
Nov 11, 2025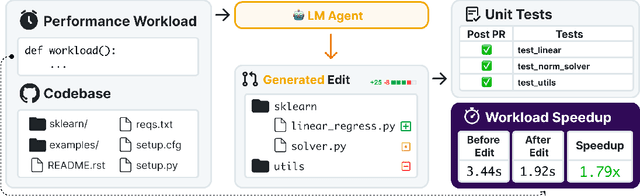



Optimizing the performance of large-scale software repositories demands expertise in code reasoning and software engineering (SWE) to reduce runtime while preserving program correctness. However, most benchmarks emphasize what to fix rather than how to fix code. We introduce SWE-fficiency, a benchmark for evaluating repository-level performance optimization on real workloads. Our suite contains 498 tasks across nine widely used data-science, machine-learning, and HPC repositories (e.g., numpy, pandas, scipy): given a complete codebase and a slow workload, an agent must investigate code semantics, localize bottlenecks and relevant tests, and produce a patch that matches or exceeds expert speedup while passing the same unit tests. To enable this how-to-fix evaluation, our automated pipeline scrapes GitHub pull requests for performance-improving edits, combining keyword filtering, static analysis, coverage tooling, and execution validation to both confirm expert speedup baselines and identify relevant repository unit tests. Empirical evaluation of state-of-the-art agents reveals significant underperformance. On average, agents achieve less than 0.15x the expert speedup: agents struggle in localizing optimization opportunities, reasoning about execution across functions, and maintaining correctness in proposed edits. We release the benchmark and accompanying data pipeline to facilitate research on automated performance engineering and long-horizon software reasoning.
Understanding and Optimizing Multi-Stage AI Inference Pipelines
Apr 16, 2025The rapid evolution of Large Language Models (LLMs) has driven the need for increasingly sophisticated inference pipelines and hardware platforms. Modern LLM serving extends beyond traditional prefill-decode workflows, incorporating multi-stage processes such as Retrieval Augmented Generation (RAG), key-value (KV) cache retrieval, dynamic model routing, and multi step reasoning. These stages exhibit diverse computational demands, requiring distributed systems that integrate GPUs, ASICs, CPUs, and memory-centric architectures. However, existing simulators lack the fidelity to model these heterogeneous, multi-engine workflows, limiting their ability to inform architectural decisions. To address this gap, we introduce HERMES, a Heterogeneous Multi-stage LLM inference Execution Simulator. HERMES models diverse request stages; including RAG, KV retrieval, reasoning, prefill, and decode across complex hardware hierarchies. HERMES supports heterogeneous clients executing multiple models concurrently unlike prior frameworks while incorporating advanced batching strategies and multi-level memory hierarchies. By integrating real hardware traces with analytical modeling, HERMES captures critical trade-offs such as memory bandwidth contention, inter-cluster communication latency, and batching efficiency in hybrid CPU-accelerator deployments. Through case studies, we explore the impact of reasoning stages on end-to-end latency, optimal batching strategies for hybrid pipelines, and the architectural implications of remote KV cache retrieval. HERMES empowers system designers to navigate the evolving landscape of LLM inference, providing actionable insights into optimizing hardware-software co-design for next-generation AI workloads.
Beyond Moore's Law: Harnessing the Redshift of Generative AI with Effective Hardware-Software Co-Design
Apr 09, 2025For decades, Moore's Law has served as a steadfast pillar in computer architecture and system design, promoting a clear abstraction between hardware and software. This traditional Moore's computing paradigm has deepened the rift between the two, enabling software developers to achieve near-exponential performance gains often without needing to delve deeply into hardware-specific optimizations. Yet today, Moore's Law -- with its once relentless performance gains now diminished to incremental improvements -- faces inevitable physical barriers. This stagnation necessitates a reevaluation of the conventional system design philosophy. The traditional decoupled system design philosophy, which maintains strict abstractions between hardware and software, is increasingly obsolete. The once-clear boundary between software and hardware is rapidly dissolving, replaced by co-design. It is imperative for the computing community to intensify its commitment to hardware-software co-design, elevating system abstractions to first-class citizens and reimagining design principles to satisfy the insatiable appetite of modern computing. Hardware-software co-design is not a recent innovation. To illustrate its historical evolution, I classify its development into five relatively distinct ``epochs''. This post also highlights the growing influence of the architecture community in interdisciplinary teams -- particularly alongside ML researchers -- and explores why current co-design paradigms are struggling in today's computing landscape. Additionally, I will examine the concept of the ``hardware lottery'' and explore directions to mitigate its constraining influence on the next era of computing innovation.
Concorde: Fast and Accurate CPU Performance Modeling with Compositional Analytical-ML Fusion
Mar 29, 2025Cycle-level simulators such as gem5 are widely used in microarchitecture design, but they are prohibitively slow for large-scale design space explorations. We present Concorde, a new methodology for learning fast and accurate performance models of microarchitectures. Unlike existing simulators and learning approaches that emulate each instruction, Concorde predicts the behavior of a program based on compact performance distributions that capture the impact of different microarchitectural components. It derives these performance distributions using simple analytical models that estimate bounds on performance induced by each microarchitectural component, providing a simple yet rich representation of a program's performance characteristics across a large space of microarchitectural parameters. Experiments show that Concorde is more than five orders of magnitude faster than a reference cycle-level simulator, with about 2% average Cycles-Per-Instruction (CPI) prediction error across a range of SPEC, open-source, and proprietary benchmarks. This enables rapid design-space exploration and performance sensitivity analyses that are currently infeasible, e.g., in about an hour, we conducted a first-of-its-kind fine-grained performance attribution to different microarchitectural components across a diverse set of programs, requiring nearly 150 million CPI evaluations.
RAGO: Systematic Performance Optimization for Retrieval-Augmented Generation Serving
Mar 21, 2025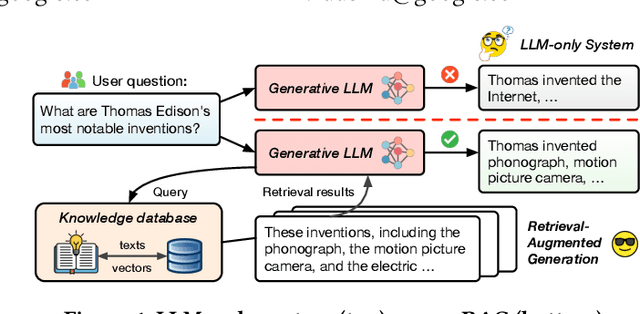



Retrieval-augmented generation (RAG), which combines large language models (LLMs) with retrievals from external knowledge databases, is emerging as a popular approach for reliable LLM serving. However, efficient RAG serving remains an open challenge due to the rapid emergence of many RAG variants and the substantial differences in workload characteristics across them. In this paper, we make three fundamental contributions to advancing RAG serving. First, we introduce RAGSchema, a structured abstraction that captures the wide range of RAG algorithms, serving as a foundation for performance optimization. Second, we analyze several representative RAG workloads with distinct RAGSchema, revealing significant performance variability across these workloads. Third, to address this variability and meet diverse performance requirements, we propose RAGO (Retrieval-Augmented Generation Optimizer), a system optimization framework for efficient RAG serving. Our evaluation shows that RAGO achieves up to a 2x increase in QPS per chip and a 55% reduction in time-to-first-token latency compared to RAG systems built on LLM-system extensions.