 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvolutionary Mapping of Neural Networks to Spatial Accelerators
Feb 04, 2026Spatial accelerators, composed of arrays of compute-memory integrated units, offer an attractive platform for deploying inference workloads with low latency and low energy consumption. However, fully exploiting their architectural advantages typically requires careful, expert-driven mapping of computational graphs to distributed processing elements. In this work, we automate this process by framing the mapping challenge as a black-box optimization problem. We introduce the first evolutionary, hardware-in-the-loop mapping framework for neuromorphic accelerators, enabling users without deep hardware knowledge to deploy workloads more efficiently. We evaluate our approach on Intel Loihi 2, a representative spatial accelerator featuring 152 cores per chip in a 2D mesh. Our method achieves up to 35% reduction in total latency compared to default heuristics on two sparse multi-layer perceptron networks. Furthermore, we demonstrate the scalability of our approach to multi-chip systems and observe an up to 40% improvement in energy efficiency, without explicitly optimizing for it.
QuArch: A Question-Answering Dataset for AI Agents in Computer Architecture
Jan 06, 2025



We introduce QuArch, a dataset of 1500 human-validated question-answer pairs designed to evaluate and enhance language models' understanding of computer architecture. The dataset covers areas including processor design, memory systems, and performance optimization. Our analysis highlights a significant performance gap: the best closed-source model achieves 84% accuracy, while the top small open-source model reaches 72%. We observe notable struggles in memory systems, interconnection networks, and benchmarking. Fine-tuning with QuArch improves small model accuracy by up to 8%, establishing a foundation for advancing AI-driven computer architecture research. The dataset and leaderboard are at https://harvard-edge.github.io/QuArch/.
VaPr: Variable-Precision Tensors to Accelerate Robot Motion Planning
Oct 11, 2023



High-dimensional motion generation requires numerical precision for smooth, collision-free solutions. Typically, double-precision or single-precision floating-point (FP) formats are utilized. Using these for big tensors imposes a strain on the memory bandwidth provided by the devices and alters the memory footprint, hence limiting their applicability to low-power edge devices needed for mobile robots. The uniform application of reduced precision can be advantageous but severely degrades solutions. Using decreased precision data types for important tensors, we propose to accelerate motion generation by removing memory bottlenecks. We propose variable-precision (VaPr) search optimization to determine the appropriate precision for large tensors from a vast search space of approximately 4 million unique combinations for FP data types across the tensors. To obtain the efficiency gains, we exploit existing platform support for an out-of-the-box GPU speedup and evaluate prospective precision converter units for GPU types that are not currently supported. Our experimental results on 800 planning problems for the Franka Panda robot on the MotionBenchmaker dataset across 8 environments show that a 4-bit FP format is sufficient for the largest set of tensors in the motion generation stack. With the software-only solution, VaPr achieves 6.3% and 6.3% speedups on average for a significant portion of motion generation over the SOTA solution (CuRobo) on Jetson Orin and RTX2080 Ti GPU, respectively, and 9.9%, 17.7% speedups with the FP converter.
NeuroBench: Advancing Neuromorphic Computing through Collaborative, Fair and Representative Benchmarking
Apr 15, 2023



The field of neuromorphic computing holds great promise in terms of advancing computing efficiency and capabilities by following brain-inspired principles. However, the rich diversity of techniques employed in neuromorphic research has resulted in a lack of clear standards for benchmarking, hindering effective evaluation of the advantages and strengths of neuromorphic methods compared to traditional deep-learning-based methods. This paper presents a collaborative effort, bringing together members from academia and the industry, to define benchmarks for neuromorphic computing: NeuroBench. The goals of NeuroBench are to be a collaborative, fair, and representative benchmark suite developed by the community, for the community. In this paper, we discuss the challenges associated with benchmarking neuromorphic solutions, and outline the key features of NeuroBench. We believe that NeuroBench will be a significant step towards defining standards that can unify the goals of neuromorphic computing and drive its technological progress. Please visit neurobench.ai for the latest updates on the benchmark tasks and metrics.
XRBench: An Extended Reality (XR) Machine Learning Benchmark Suite for the Metaverse
Nov 16, 2022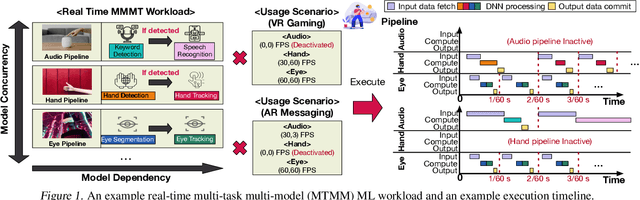
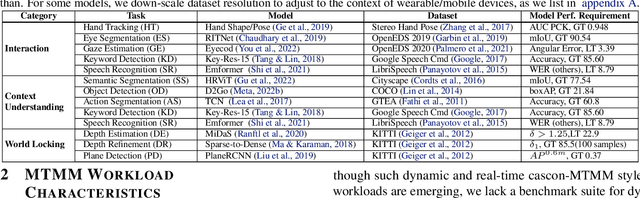

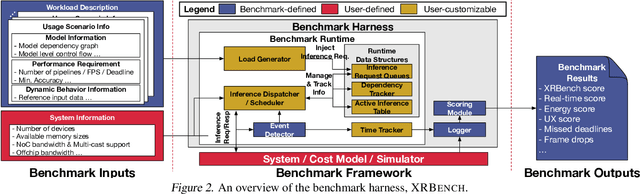
Real-time multi-model multi-task (MMMT) workloads, a new form of deep learning inference workloads, are emerging for applications areas like extended reality (XR) to support metaverse use cases. These workloads combine user interactivity with computationally complex machine learning (ML) activities. Compared to standard ML applications, these ML workloads present unique difficulties and constraints. Real-time MMMT workloads impose heterogeneity and concurrency requirements on future ML systems and devices, necessitating the development of new capabilities. This paper begins with a discussion of the various characteristics of these real-time MMMT ML workloads and presents an ontology for evaluating the performance of future ML hardware for XR systems. Next, we present XRBench, a collection of MMMT ML tasks, models, and usage scenarios that execute these models in three representative ways: cascaded, concurrent, and cascaded-concurrency for XR use cases. Finally, we emphasize the need for new metrics that capture the requirements properly. We hope that our work will stimulate research and lead to the development of a new generation of ML systems for XR use cases.