 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSee it to Place it: Evolving Macro Placements with Vision-Language Models
Mar 30, 2026We propose using Vision-Language Models (VLMs) for macro placement in chip floorplanning, a complex optimization task that has recently shown promising advancements through machine learning methods. Because human designers rely heavily on spatial reasoning to arrange components on the chip canvas, we hypothesize that VLMs with strong visual reasoning abilities can effectively complement existing learning-based approaches. We introduce VeoPlace (Visual Evolutionary Optimization Placement), a novel framework that uses a VLM, without any fine-tuning, to guide the actions of a base placer by constraining them to subregions of the chip canvas. The VLM proposals are iteratively optimized through an evolutionary search strategy with respect to resulting placement quality. On open-source benchmarks, VeoPlace outperforms the best prior learning-based approach on 9 of 10 benchmarks with peak wirelength reductions exceeding 32%. We further demonstrate that VeoPlace generalizes to analytical placers, improving DREAMPlace performance on all 8 evaluated benchmarks with gains up to 4.3%. Our approach opens new possibilities for electronic design automation tools that leverage foundation models to solve complex physical design problems.
GenAI for Systems: Recurring Challenges and Design Principles from Software to Silicon
Feb 16, 2026Generative AI is reshaping how computing systems are designed, optimized, and built, yet research remains fragmented across software, architecture, and chip design communities. This paper takes a cross-stack perspective, examining how generative models are being applied from code generation and distributed runtimes through hardware design space exploration to RTL synthesis, physical layout, and verification. Rather than reviewing each layer in isolation, we analyze how the same structural difficulties and effective responses recur across the stack. Our central finding is one of convergence. Despite the diversity of domains and tools, the field keeps encountering five recurring challenges (the feedback loop crisis, the tacit knowledge problem, trust and validation, co-design across boundaries, and the shift from determinism to dynamism) and keeps arriving at five design principles that independently emerge as effective responses (embracing hybrid approaches, designing for continuous feedback, separating concerns by role, matching methods to problem structure, and building on decades of systems knowledge). We organize these into a challenge--principle map that serves as a diagnostic and design aid, showing which principles have proven effective for which challenges across layers. Through concrete cross-stack examples, we show how systems navigate this map as they mature, and argue that the field needs shared engineering methodology, including common vocabularies, cross-layer benchmarks, and systematic design practices, so that progress compounds across communities rather than being rediscovered in each one. Our analysis covers more than 275 papers spanning eleven application areas across three layers of the computing stack, and distills open research questions that become visible only from a cross-layer vantage point.
TinyTorch: Building Machine Learning Systems from First Principles
Jan 27, 2026Machine learning systems engineering requires a deep understanding of framework internals. Yet most current education separates algorithms from systems. Students learn gradient descent without measuring memory usage, and attention mechanisms without profiling computational cost. This split leaves graduates unprepared to debug real production failures and widens the gap between machine learning research and reliable deployment. We present TinyTorch, a 20 module curriculum in which students implement the core components of PyTorch, including tensors, autograd, optimizers, and neural networks, entirely in pure Python. The curriculum is built around three pedagogical principles. Progressive disclosure gradually introduces complexity as students build confidence. Systems first integration embeds memory and performance awareness from the very beginning. Historical milestone validation guides students to recreate key breakthroughs, from the Perceptron in 1958 to modern Transformers, using only code they have written themselves. TinyTorch requires only a laptop with 4GB of RAM and no GPU, making machine learning systems education accessible worldwide. Its goal is to prepare the next generation of AI engineers, practitioners who understand not only what machine learning systems do, but why they work and how to make them scale. The curriculum is available as open source at mlsysbook.ai slash tinytorch.
AI Benchmark Democratization and Carpentry
Dec 12, 2025Benchmarks are a cornerstone of modern machine learning, enabling reproducibility, comparison, and scientific progress. However, AI benchmarks are increasingly complex, requiring dynamic, AI-focused workflows. Rapid evolution in model architectures, scale, datasets, and deployment contexts makes evaluation a moving target. Large language models often memorize static benchmarks, causing a gap between benchmark results and real-world performance. Beyond traditional static benchmarks, continuous adaptive benchmarking frameworks are needed to align scientific assessment with deployment risks. This calls for skills and education in AI Benchmark Carpentry. From our experience with MLCommons, educational initiatives, and programs like the DOE's Trillion Parameter Consortium, key barriers include high resource demands, limited access to specialized hardware, lack of benchmark design expertise, and uncertainty in relating results to application domains. Current benchmarks often emphasize peak performance on top-tier hardware, offering limited guidance for diverse, real-world scenarios. Benchmarking must become dynamic, incorporating evolving models, updated data, and heterogeneous platforms while maintaining transparency, reproducibility, and interpretability. Democratization requires both technical innovation and systematic education across levels, building sustained expertise in benchmark design and use. Benchmarks should support application-relevant comparisons, enabling informed, context-sensitive decisions. Dynamic, inclusive benchmarking will ensure evaluation keeps pace with AI evolution and supports responsible, reproducible, and accessible AI deployment. Community efforts can provide a foundation for AI Benchmark Carpentry.
SWE-fficiency: Can Language Models Optimize Real-World Repositories on Real Workloads?
Nov 11, 2025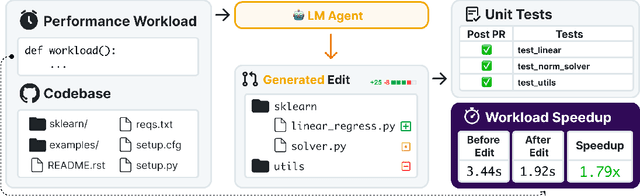



Optimizing the performance of large-scale software repositories demands expertise in code reasoning and software engineering (SWE) to reduce runtime while preserving program correctness. However, most benchmarks emphasize what to fix rather than how to fix code. We introduce SWE-fficiency, a benchmark for evaluating repository-level performance optimization on real workloads. Our suite contains 498 tasks across nine widely used data-science, machine-learning, and HPC repositories (e.g., numpy, pandas, scipy): given a complete codebase and a slow workload, an agent must investigate code semantics, localize bottlenecks and relevant tests, and produce a patch that matches or exceeds expert speedup while passing the same unit tests. To enable this how-to-fix evaluation, our automated pipeline scrapes GitHub pull requests for performance-improving edits, combining keyword filtering, static analysis, coverage tooling, and execution validation to both confirm expert speedup baselines and identify relevant repository unit tests. Empirical evaluation of state-of-the-art agents reveals significant underperformance. On average, agents achieve less than 0.15x the expert speedup: agents struggle in localizing optimization opportunities, reasoning about execution across functions, and maintaining correctness in proposed edits. We release the benchmark and accompanying data pipeline to facilitate research on automated performance engineering and long-horizon software reasoning.
Slm-mux: Orchestrating small language models for reasoning
Oct 06, 2025With the rapid development of language models, the number of small language models (SLMs) has grown significantly. Although they do not achieve state-of-the-art accuracy, they are more efficient and often excel at specific tasks. This raises a natural question: can multiple SLMs be orchestrated into a system where each contributes effectively, achieving higher accuracy than any individual model? Existing orchestration methods have primarily targeted frontier models (e.g., GPT-4) and perform suboptimally when applied to SLMs. To address this gap, we propose a three-stage approach for orchestrating SLMs. First, we introduce SLM-MUX, a multi-model architecture that effectively coordinates multiple SLMs. Building on this, we develop two optimization strategies: (i) a model selection search that identifies the most complementary SLMs from a given pool, and (ii) test-time scaling tailored to SLM-MUX. Our approach delivers strong results: Compared to existing orchestration methods, our approach achieves up to 13.4% improvement on MATH, 8.8% on GPQA, and 7.0% on GSM8K. With just two SLMS, SLM-MUX outperforms Qwen 2.5 72B on GPQA and GSM8K, and matches its performance on MATH. We further provide theoretical analyses to substantiate the advantages of our method. In summary, we demonstrate that SLMs can be effectively orchestrated into more accurate and efficient systems through the proposed approach.
Lifetime-Aware Design of Item-Level Intelligence
Sep 09, 2025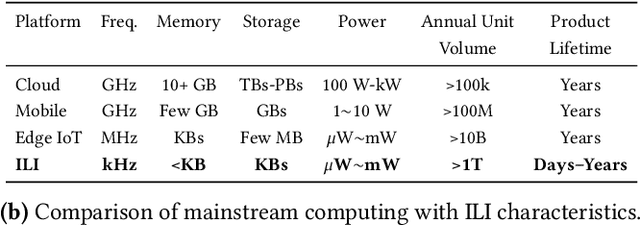


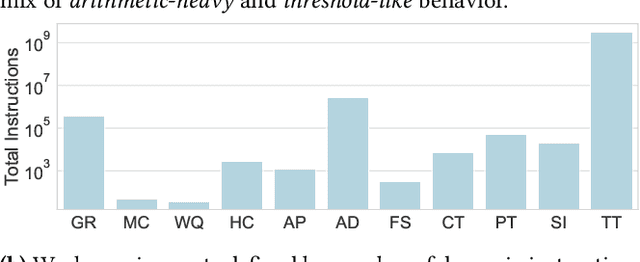
We present FlexiFlow, a lifetime-aware design framework for item-level intelligence (ILI) where computation is integrated directly into disposable products like food packaging and medical patches. Our framework leverages natively flexible electronics which offer significantly lower costs than silicon but are limited to kHz speeds and several thousands of gates. Our insight is that unlike traditional computing with more uniform deployment patterns, ILI applications exhibit 1000X variation in operational lifetime, fundamentally changing optimal architectural design decisions when considering trillion-item deployment scales. To enable holistic design and optimization, we model the trade-offs between embodied carbon footprint and operational carbon footprint based on application-specific lifetimes. The framework includes: (1) FlexiBench, a workload suite targeting sustainability applications from spoilage detection to health monitoring; (2) FlexiBits, area-optimized RISC-V cores with 1/4/8-bit datapaths achieving 2.65X to 3.50X better energy efficiency per workload execution; and (3) a carbon-aware model that selects optimal architectures based on deployment characteristics. We show that lifetime-aware microarchitectural design can reduce carbon footprint by 1.62X, while algorithmic decisions can reduce carbon footprint by 14.5X. We validate our approach through the first tape-out using a PDK for flexible electronics with fully open-source tools, achieving 30.9kHz operation. FlexiFlow enables exploration of computing at the Extreme Edge where conventional design methodologies must be reevaluated to account for new constraints and considerations.
From Seed to Harvest: Augmenting Human Creativity with AI for Red-teaming Text-to-Image Models
Jul 23, 2025Text-to-image (T2I) models have become prevalent across numerous applications, making their robust evaluation against adversarial attacks a critical priority. Continuous access to new and challenging adversarial prompts across diverse domains is essential for stress-testing these models for resilience against novel attacks from multiple vectors. Current techniques for generating such prompts are either entirely authored by humans or synthetically generated. On the one hand, datasets of human-crafted adversarial prompts are often too small in size and imbalanced in their cultural and contextual representation. On the other hand, datasets of synthetically-generated prompts achieve scale, but typically lack the realistic nuances and creative adversarial strategies found in human-crafted prompts. To combine the strengths of both human and machine approaches, we propose Seed2Harvest, a hybrid red-teaming method for guided expansion of culturally diverse, human-crafted adversarial prompt seeds. The resulting prompts preserve the characteristics and attack patterns of human prompts while maintaining comparable average attack success rates (0.31 NudeNet, 0.36 SD NSFW, 0.12 Q16). Our expanded dataset achieves substantially higher diversity with 535 unique geographic locations and a Shannon entropy of 7.48, compared to 58 locations and 5.28 entropy in the original dataset. Our work demonstrates the importance of human-machine collaboration in leveraging human creativity and machine computational capacity to achieve comprehensive, scalable red-teaming for continuous T2I model safety evaluation.
Generative AI in Embodied Systems: System-Level Analysis of Performance, Efficiency and Scalability
Apr 26, 2025Embodied systems, where generative autonomous agents engage with the physical world through integrated perception, cognition, action, and advanced reasoning powered by large language models (LLMs), hold immense potential for addressing complex, long-horizon, multi-objective tasks in real-world environments. However, deploying these systems remains challenging due to prolonged runtime latency, limited scalability, and heightened sensitivity, leading to significant system inefficiencies. In this paper, we aim to understand the workload characteristics of embodied agent systems and explore optimization solutions. We systematically categorize these systems into four paradigms and conduct benchmarking studies to evaluate their task performance and system efficiency across various modules, agent scales, and embodied tasks. Our benchmarking studies uncover critical challenges, such as prolonged planning and communication latency, redundant agent interactions, complex low-level control mechanisms, memory inconsistencies, exploding prompt lengths, sensitivity to self-correction and execution, sharp declines in success rates, and reduced collaboration efficiency as agent numbers increase. Leveraging these profiling insights, we suggest system optimization strategies to improve the performance, efficiency, and scalability of embodied agents across different paradigms. This paper presents the first system-level analysis of embodied AI agents, and explores opportunities for advancing future embodied system design.
A2Perf: Real-World Autonomous Agents Benchmark
Mar 04, 2025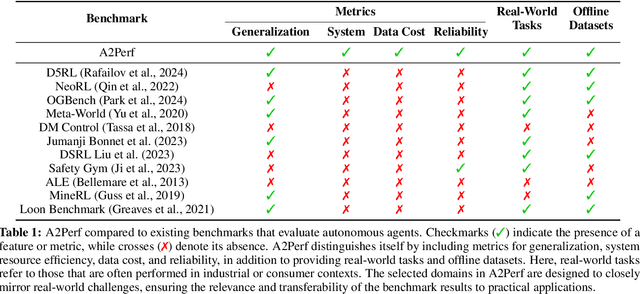

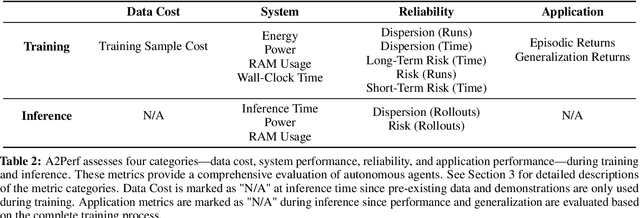

Autonomous agents and systems cover a number of application areas, from robotics and digital assistants to combinatorial optimization, all sharing common, unresolved research challenges. It is not sufficient for agents to merely solve a given task; they must generalize to out-of-distribution tasks, perform reliably, and use hardware resources efficiently during training and inference, among other requirements. Several methods, such as reinforcement learning and imitation learning, are commonly used to tackle these problems, each with different trade-offs. However, there is a lack of benchmarking suites that define the environments, datasets, and metrics which can be used to provide a meaningful way for the community to compare progress on applying these methods to real-world problems. We introduce A2Perf--a benchmark with three environments that closely resemble real-world domains: computer chip floorplanning, web navigation, and quadruped locomotion. A2Perf provides metrics that track task performance, generalization, system resource efficiency, and reliability, which are all critical to real-world applications. Using A2Perf, we demonstrate that web navigation agents can achieve latencies comparable to human reaction times on consumer hardware, reveal reliability trade-offs between algorithms for quadruped locomotion, and quantify the energy costs of different learning approaches for computer chip-design. In addition, we propose a data cost metric to account for the cost incurred acquiring offline data for imitation learning and hybrid algorithms, which allows us to better compare these approaches. A2Perf also contains several standard baselines, enabling apples-to-apples comparisons across methods and facilitating progress in real-world autonomy. As an open-source benchmark, A2Perf is designed to remain accessible, up-to-date, and useful to the research community over the long term.