 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMLPerf Power: Benchmarking the Energy Efficiency of Machine Learning Systems from μWatts to MWatts for Sustainable AI
Oct 15, 2024



Rapid adoption of machine learning (ML) technologies has led to a surge in power consumption across diverse systems, from tiny IoT devices to massive datacenter clusters. Benchmarking the energy efficiency of these systems is crucial for optimization, but presents novel challenges due to the variety of hardware platforms, workload characteristics, and system-level interactions. This paper introduces MLPerf Power, a comprehensive benchmarking methodology with capabilities to evaluate the energy efficiency of ML systems at power levels ranging from microwatts to megawatts. Developed by a consortium of industry professionals from more than 20 organizations, MLPerf Power establishes rules and best practices to ensure comparability across diverse architectures. We use representative workloads from the MLPerf benchmark suite to collect 1,841 reproducible measurements from 60 systems across the entire range of ML deployment scales. Our analysis reveals trade-offs between performance, complexity, and energy efficiency across this wide range of systems, providing actionable insights for designing optimized ML solutions from the smallest edge devices to the largest cloud infrastructures. This work emphasizes the importance of energy efficiency as a key metric in the evaluation and comparison of the ML system, laying the foundation for future research in this critical area. We discuss the implications for developing sustainable AI solutions and standardizing energy efficiency benchmarking for ML systems.
Deep Learning Models on CPUs: A Methodology for Efficient Training
Jun 20, 2022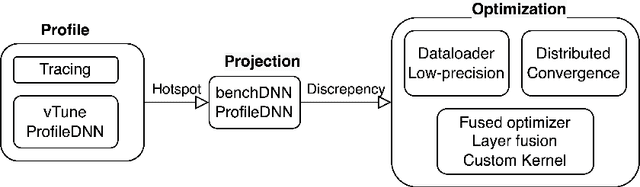

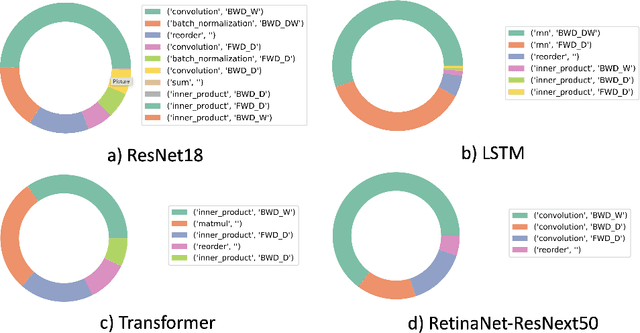
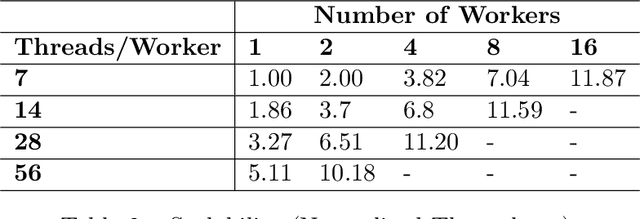
GPUs have been favored for training deep learning models due to their highly parallelized architecture. As a result, most studies on training optimization focus on GPUs. There is often a trade-off, however, between cost and efficiency when deciding on how to choose the proper hardware for training. In particular, CPU servers can be beneficial if training on CPUs was more efficient, as they incur fewer hardware update costs and better utilizing existing infrastructure. This paper makes several contributions to research on training deep learning models using CPUs. First, it presents a method for optimizing the training of deep learning models on Intel CPUs and a toolkit called ProfileDNN, which we developed to improve performance profiling. Second, we describe a generic training optimization method that guides our workflow and explores several case studies where we identified performance issues and then optimized the Intel Extension for PyTorch, resulting in an overall 2x training performance increase for the RetinaNet-ResNext50 model. Third, we show how to leverage the visualization capabilities of ProfileDNN, which enabled us to pinpoint bottlenecks and create a custom focal loss kernel that was two times faster than the official reference PyTorch implementation.
MLPerf Mobile Inference Benchmark: Why Mobile AI Benchmarking Is Hard and What to Do About It
Dec 03, 2020

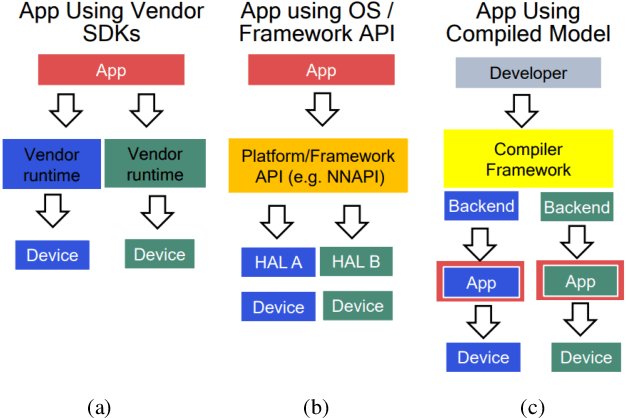
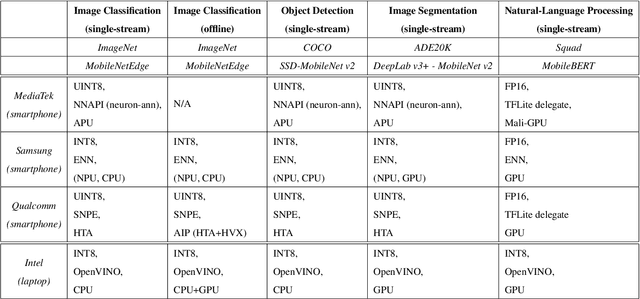
MLPerf Mobile is the first industry-standard open-source mobile benchmark developed by industry members and academic researchers to allow performance/accuracy evaluation of mobile devices with different AI chips and software stacks. The benchmark draws from the expertise of leading mobile-SoC vendors, ML-framework providers, and model producers. In this paper, we motivate the drive to demystify mobile-AI performance and present MLPerf Mobile's design considerations, architecture, and implementation. The benchmark comprises a suite of models that operate under standard models, data sets, quality metrics, and run rules. For the first iteration, we developed an app to provide an "out-of-the-box" inference-performance benchmark for computer vision and natural-language processing on mobile devices. MLPerf Mobile can serve as a framework for integrating future models, for customizing quality-target thresholds to evaluate system performance, for comparing software frameworks, and for assessing heterogeneous-hardware capabilities for machine learning, all fairly and faithfully with fully reproducible results.
MLPerf Inference Benchmark
Nov 06, 2019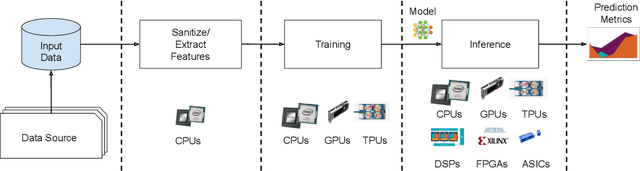
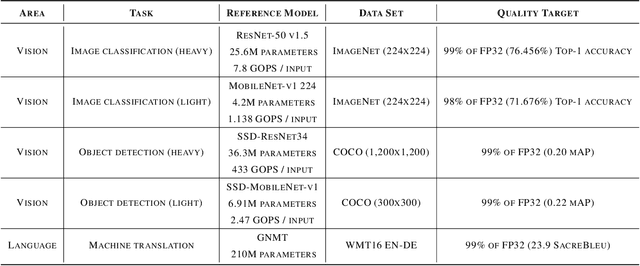
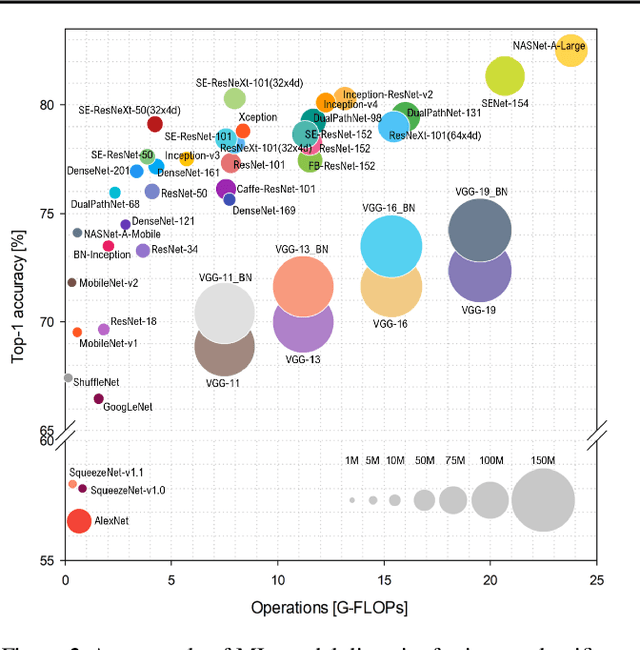
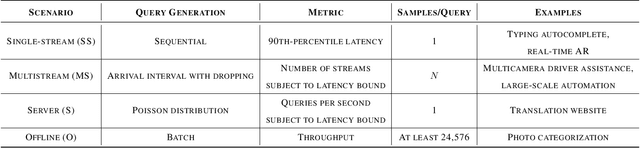
Machine-learning (ML) hardware and software system demand is burgeoning. Driven by ML applications, the number of different ML inference systems has exploded. Over 100 organizations are building ML inference chips, and the systems that incorporate existing models span at least three orders of magnitude in power consumption and four orders of magnitude in performance; they range from embedded devices to data-center solutions. Fueling the hardware are a dozen or more software frameworks and libraries. The myriad combinations of ML hardware and ML software make assessing ML-system performance in an architecture-neutral, representative, and reproducible manner challenging. There is a clear need for industry-wide standard ML benchmarking and evaluation criteria. MLPerf Inference answers that call. Driven by more than 30 organizations as well as more than 200 ML engineers and practitioners, MLPerf implements a set of rules and practices to ensure comparability across systems with wildly differing architectures. In this paper, we present the method and design principles of the initial MLPerf Inference release. The first call for submissions garnered more than 600 inference-performance measurements from 14 organizations, representing over 30 systems that show a range of capabilities.