 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIntroducing v0.5 of the AI Safety Benchmark from MLCommons
Apr 18, 2024



This paper introduces v0.5 of the AI Safety Benchmark, which has been created by the MLCommons AI Safety Working Group. The AI Safety Benchmark has been designed to assess the safety risks of AI systems that use chat-tuned language models. We introduce a principled approach to specifying and constructing the benchmark, which for v0.5 covers only a single use case (an adult chatting to a general-purpose assistant in English), and a limited set of personas (i.e., typical users, malicious users, and vulnerable users). We created a new taxonomy of 13 hazard categories, of which 7 have tests in the v0.5 benchmark. We plan to release version 1.0 of the AI Safety Benchmark by the end of 2024. The v1.0 benchmark will provide meaningful insights into the safety of AI systems. However, the v0.5 benchmark should not be used to assess the safety of AI systems. We have sought to fully document the limitations, flaws, and challenges of v0.5. This release of v0.5 of the AI Safety Benchmark includes (1) a principled approach to specifying and constructing the benchmark, which comprises use cases, types of systems under test (SUTs), language and context, personas, tests, and test items; (2) a taxonomy of 13 hazard categories with definitions and subcategories; (3) tests for seven of the hazard categories, each comprising a unique set of test items, i.e., prompts. There are 43,090 test items in total, which we created with templates; (4) a grading system for AI systems against the benchmark; (5) an openly available platform, and downloadable tool, called ModelBench that can be used to evaluate the safety of AI systems on the benchmark; (6) an example evaluation report which benchmarks the performance of over a dozen openly available chat-tuned language models; (7) a test specification for the benchmark.
Croissant: A Metadata Format for ML-Ready Datasets
Mar 28, 2024Data is a critical resource for Machine Learning (ML), yet working with data remains a key friction point. This paper introduces Croissant, a metadata format for datasets that simplifies how data is used by ML tools and frameworks. Croissant makes datasets more discoverable, portable and interoperable, thereby addressing significant challenges in ML data management and responsible AI. Croissant is already supported by several popular dataset repositories, spanning hundreds of thousands of datasets, ready to be loaded into the most popular ML frameworks.
DMLR: Data-centric Machine Learning Research -- Past, Present and Future
Nov 21, 2023


Drawing from discussions at the inaugural DMLR workshop at ICML 2023 and meetings prior, in this report we outline the relevance of community engagement and infrastructure development for the creation of next-generation public datasets that will advance machine learning science. We chart a path forward as a collective effort to sustain the creation and maintenance of these datasets and methods towards positive scientific, societal and business impact.
Benchmarking Neural Network Training Algorithms
Jun 12, 2023



Training algorithms, broadly construed, are an essential part of every deep learning pipeline. Training algorithm improvements that speed up training across a wide variety of workloads (e.g., better update rules, tuning protocols, learning rate schedules, or data selection schemes) could save time, save computational resources, and lead to better, more accurate, models. Unfortunately, as a community, we are currently unable to reliably identify training algorithm improvements, or even determine the state-of-the-art training algorithm. In this work, using concrete experiments, we argue that real progress in speeding up training requires new benchmarks that resolve three basic challenges faced by empirical comparisons of training algorithms: (1) how to decide when training is complete and precisely measure training time, (2) how to handle the sensitivity of measurements to exact workload details, and (3) how to fairly compare algorithms that require hyperparameter tuning. In order to address these challenges, we introduce a new, competitive, time-to-result benchmark using multiple workloads running on fixed hardware, the AlgoPerf: Training Algorithms benchmark. Our benchmark includes a set of workload variants that make it possible to detect benchmark submissions that are more robust to workload changes than current widely-used methods. Finally, we evaluate baseline submissions constructed using various optimizers that represent current practice, as well as other optimizers that have recently received attention in the literature. These baseline results collectively demonstrate the feasibility of our benchmark, show that non-trivial gaps between methods exist, and set a provisional state-of-the-art for future benchmark submissions to try and surpass.
Understanding metric-related pitfalls in image analysis validation
Feb 09, 2023Validation metrics are key for the reliable tracking of scientific progress and for bridging the current chasm between artificial intelligence (AI) research and its translation into practice. However, increasing evidence shows that particularly in image analysis, metrics are often chosen inadequately in relation to the underlying research problem. This could be attributed to a lack of accessibility of metric-related knowledge: While taking into account the individual strengths, weaknesses, and limitations of validation metrics is a critical prerequisite to making educated choices, the relevant knowledge is currently scattered and poorly accessible to individual researchers. Based on a multi-stage Delphi process conducted by a multidisciplinary expert consortium as well as extensive community feedback, the present work provides the first reliable and comprehensive common point of access to information on pitfalls related to validation metrics in image analysis. Focusing on biomedical image analysis but with the potential of transfer to other fields, the addressed pitfalls generalize across application domains and are categorized according to a newly created, domain-agnostic taxonomy. To facilitate comprehension, illustrations and specific examples accompany each pitfall. As a structured body of information accessible to researchers of all levels of expertise, this work enhances global comprehension of a key topic in image analysis validation.
DataPerf: Benchmarks for Data-Centric AI Development
Jul 20, 2022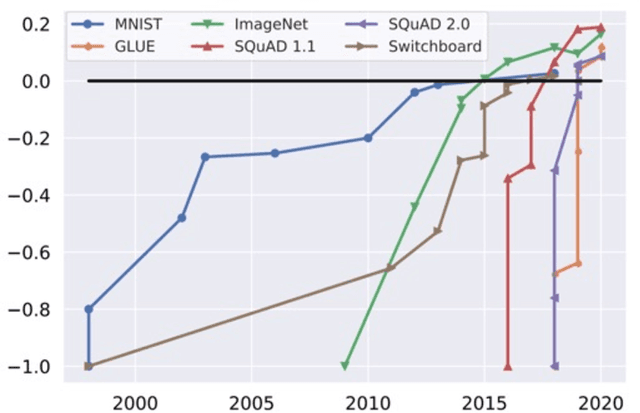
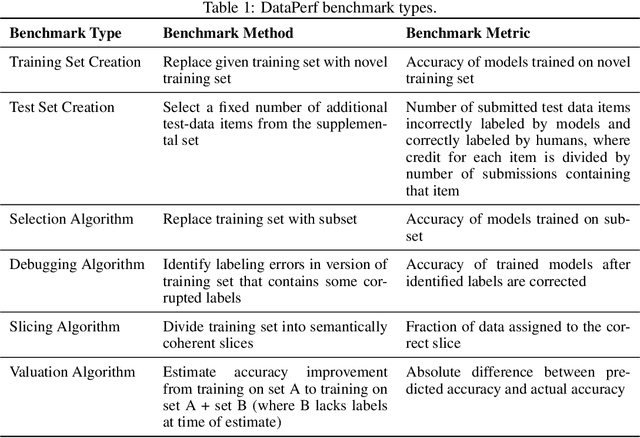
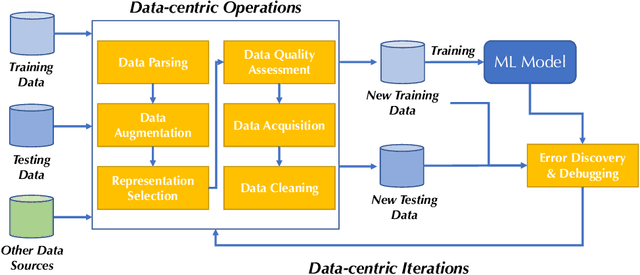
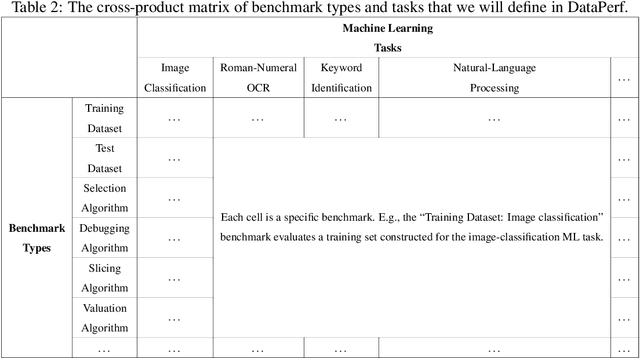
Machine learning (ML) research has generally focused on models, while the most prominent datasets have been employed for everyday ML tasks without regard for the breadth, difficulty, and faithfulness of these datasets to the underlying problem. Neglecting the fundamental importance of datasets has caused major problems involving data cascades in real-world applications and saturation of dataset-driven criteria for model quality, hindering research growth. To solve this problem, we present DataPerf, a benchmark package for evaluating ML datasets and dataset-working algorithms. We intend it to enable the "data ratchet," in which training sets will aid in evaluating test sets on the same problems, and vice versa. Such a feedback-driven strategy will generate a virtuous loop that will accelerate development of data-centric AI. The MLCommons Association will maintain DataPerf.
Metrics reloaded: Pitfalls and recommendations for image analysis validation
Jun 03, 2022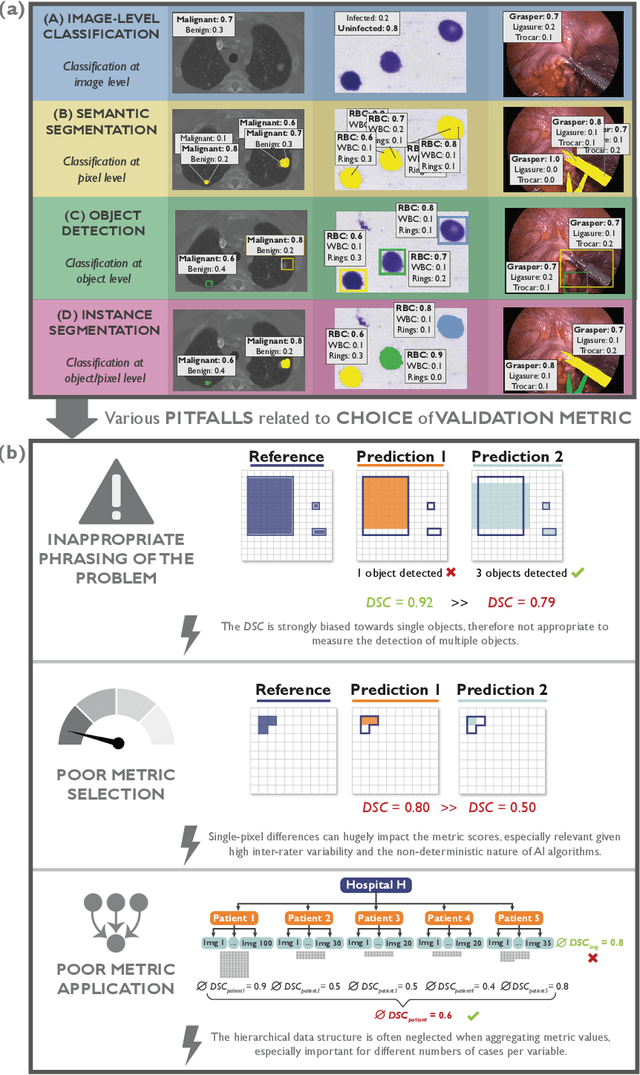
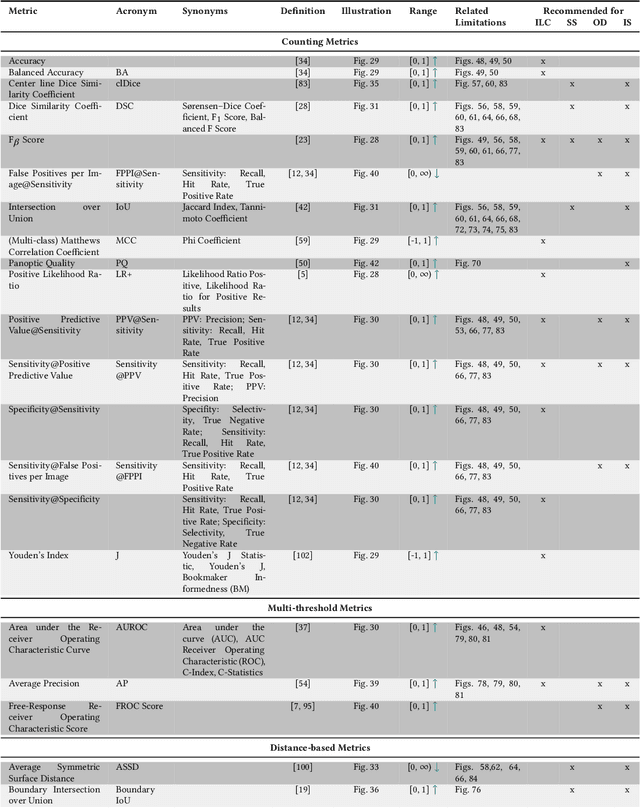
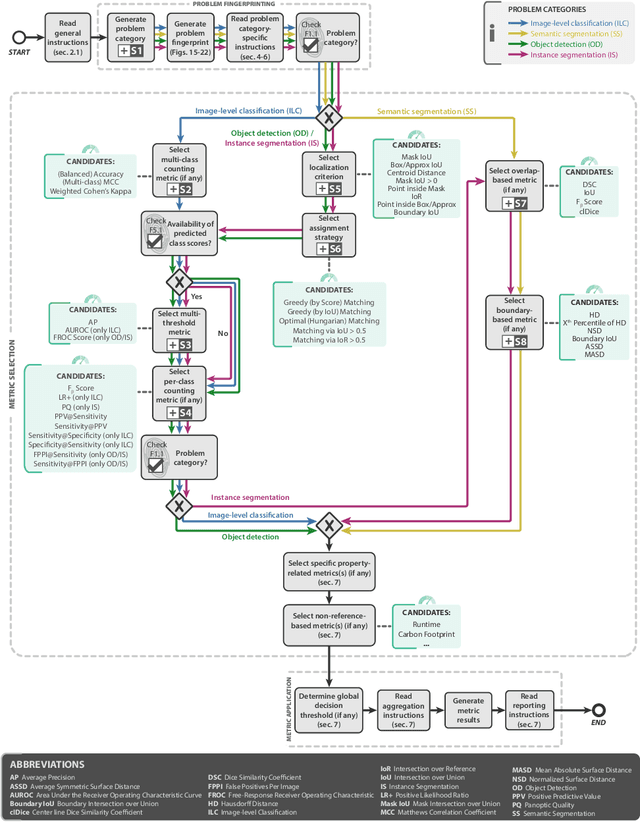
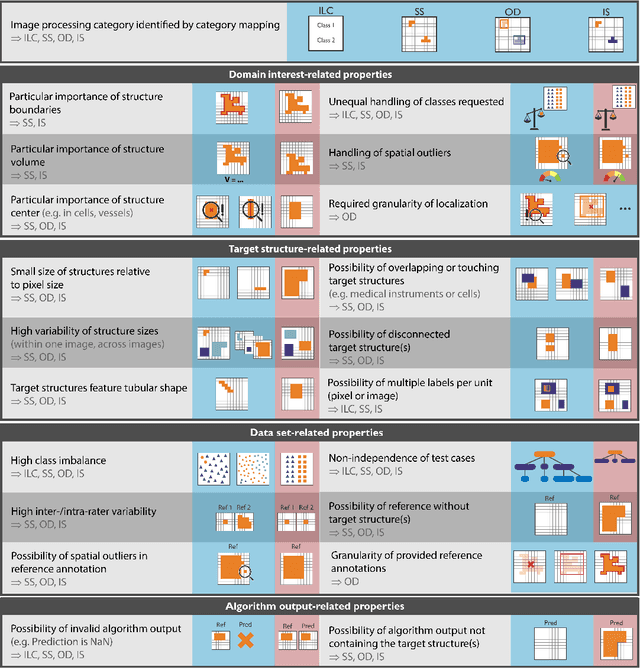
The field of automatic biomedical image analysis crucially depends on robust and meaningful performance metrics for algorithm validation. Current metric usage, however, is often ill-informed and does not reflect the underlying domain interest. Here, we present a comprehensive framework that guides researchers towards choosing performance metrics in a problem-aware manner. Specifically, we focus on biomedical image analysis problems that can be interpreted as a classification task at image, object or pixel level. The framework first compiles domain interest-, target structure-, data set- and algorithm output-related properties of a given problem into a problem fingerprint, while also mapping it to the appropriate problem category, namely image-level classification, semantic segmentation, instance segmentation, or object detection. It then guides users through the process of selecting and applying a set of appropriate validation metrics while making them aware of potential pitfalls related to individual choices. In this paper, we describe the current status of the Metrics Reloaded recommendation framework, with the goal of obtaining constructive feedback from the image analysis community. The current version has been developed within an international consortium of more than 60 image analysis experts and will be made openly available as a user-friendly toolkit after community-driven optimization.
Dynatask: A Framework for Creating Dynamic AI Benchmark Tasks
Apr 05, 2022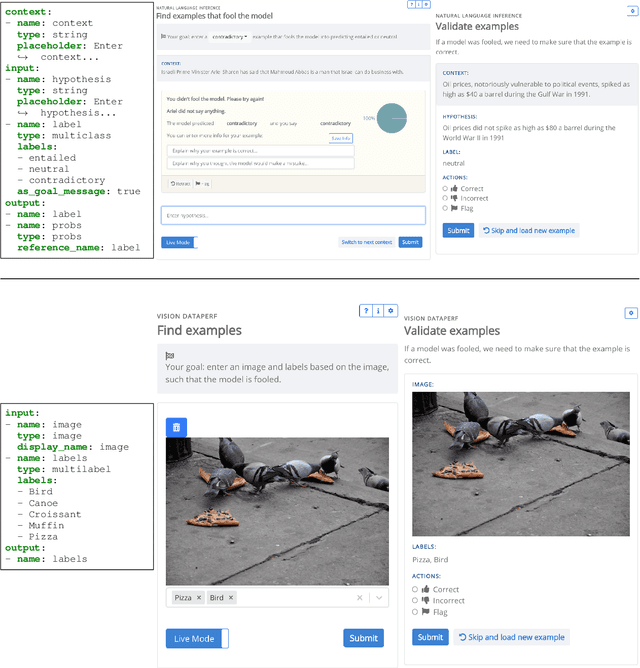
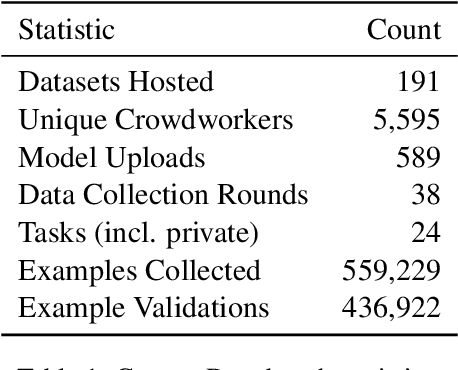
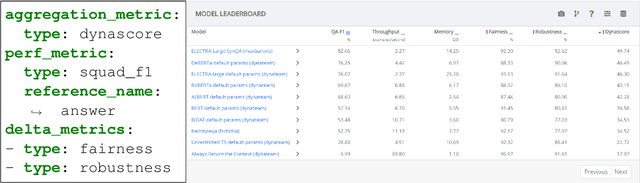
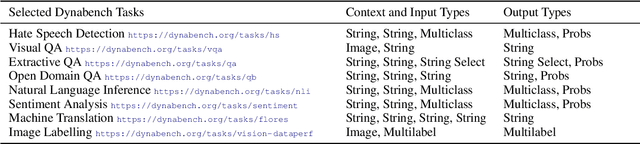
We introduce Dynatask: an open source system for setting up custom NLP tasks that aims to greatly lower the technical knowledge and effort required for hosting and evaluating state-of-the-art NLP models, as well as for conducting model in the loop data collection with crowdworkers. Dynatask is integrated with Dynabench, a research platform for rethinking benchmarking in AI that facilitates human and model in the loop data collection and evaluation. To create a task, users only need to write a short task configuration file from which the relevant web interfaces and model hosting infrastructure are automatically generated. The system is available at https://dynabench.org/ and the full library can be found at https://github.com/facebookresearch/dynabench.
MLPerf HPC: A Holistic Benchmark Suite for Scientific Machine Learning on HPC Systems
Oct 26, 2021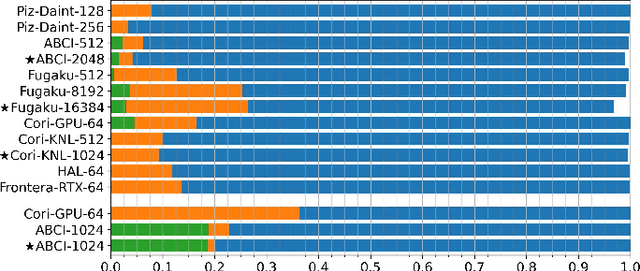
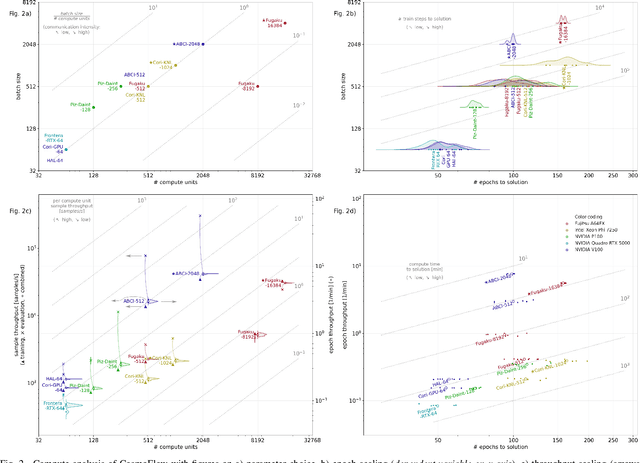
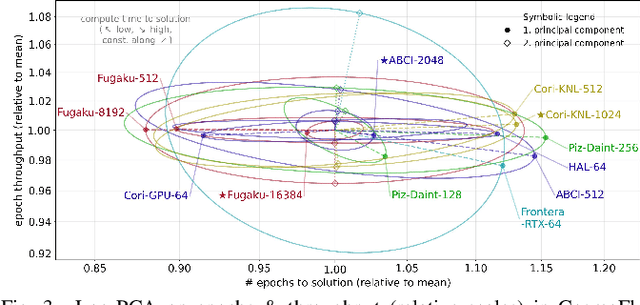
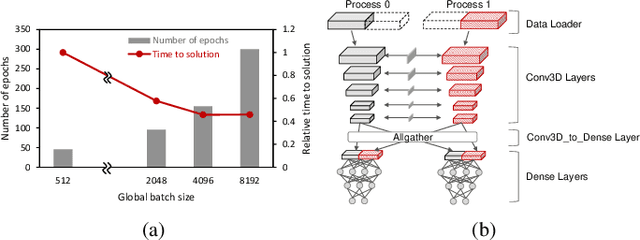
Scientific communities are increasingly adopting machine learning and deep learning models in their applications to accelerate scientific insights. High performance computing systems are pushing the frontiers of performance with a rich diversity of hardware resources and massive scale-out capabilities. There is a critical need to understand fair and effective benchmarking of machine learning applications that are representative of real-world scientific use cases. MLPerf is a community-driven standard to benchmark machine learning workloads, focusing on end-to-end performance metrics. In this paper, we introduce MLPerf HPC, a benchmark suite of large-scale scientific machine learning training applications driven by the MLCommons Association. We present the results from the first submission round, including a diverse set of some of the world's largest HPC systems. We develop a systematic framework for their joint analysis and compare them in terms of data staging, algorithmic convergence, and compute performance. As a result, we gain a quantitative understanding of optimizations on different subsystems such as staging and on-node loading of data, compute-unit utilization, and communication scheduling, enabling overall $>10 \times$ (end-to-end) performance improvements through system scaling. Notably, our analysis shows a scale-dependent interplay between the dataset size, a system's memory hierarchy, and training convergence that underlines the importance of near-compute storage. To overcome the data-parallel scalability challenge at large batch sizes, we discuss specific learning techniques and hybrid data-and-model parallelism that are effective on large systems. We conclude by characterizing each benchmark with respect to low-level memory, I/O, and network behavior to parameterize extended roofline performance models in future rounds.
MedPerf: Open Benchmarking Platform for Medical Artificial Intelligence using Federated Evaluation
Oct 08, 2021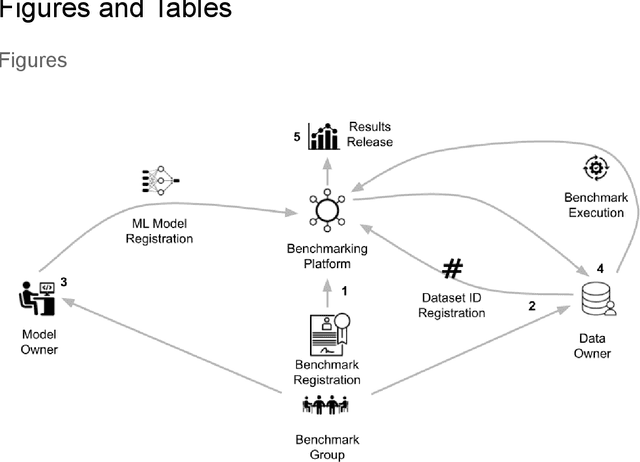
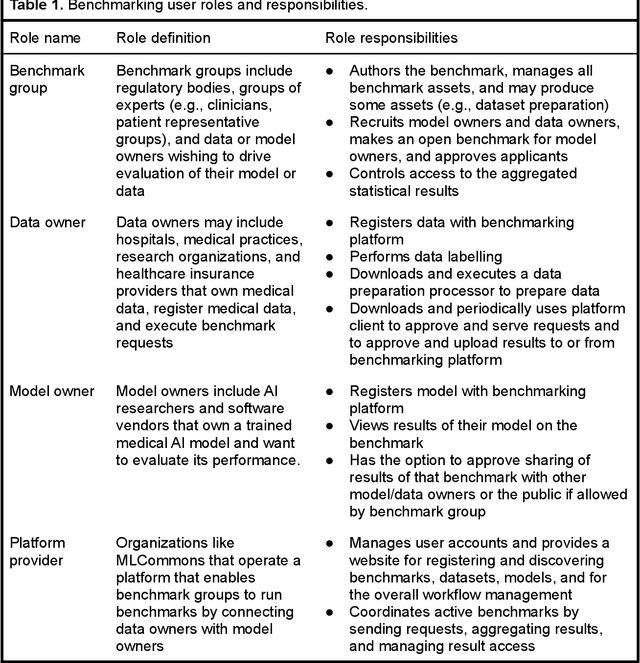
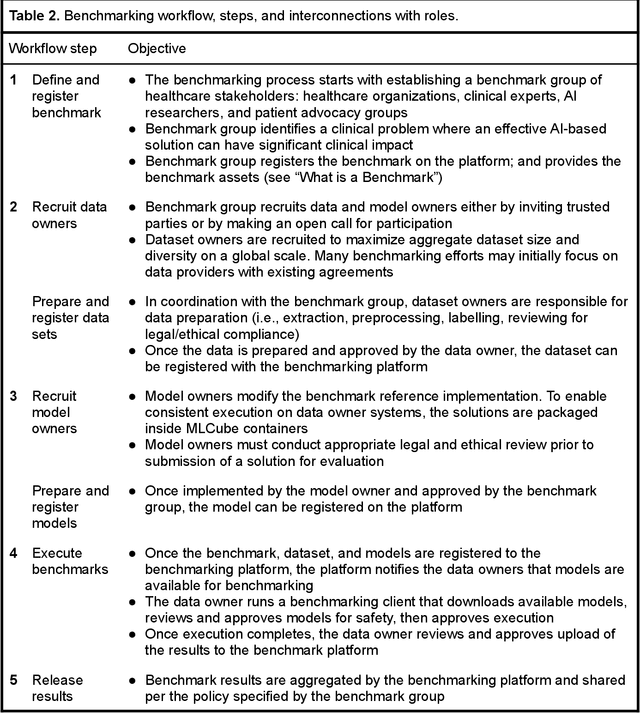
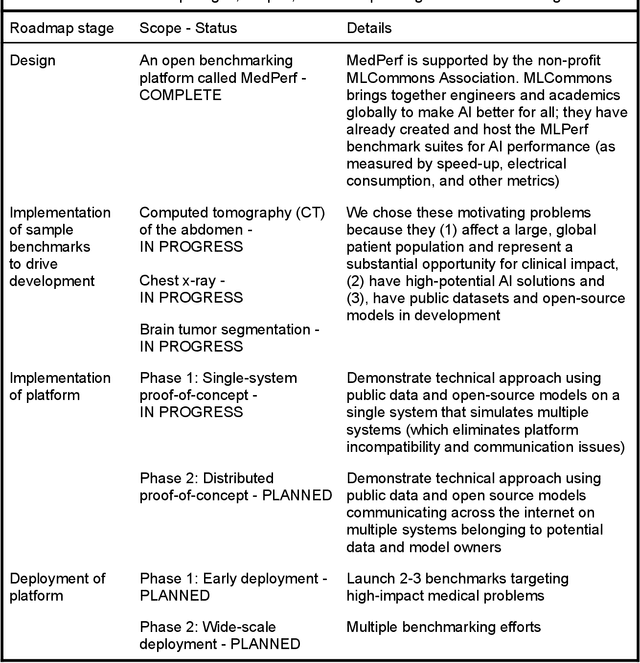
Medical AI has tremendous potential to advance healthcare by supporting the evidence-based practice of medicine, personalizing patient treatment, reducing costs, and improving provider and patient experience. We argue that unlocking this potential requires a systematic way to measure the performance of medical AI models on large-scale heterogeneous data. To meet this need, we are building MedPerf, an open framework for benchmarking machine learning in the medical domain. MedPerf will enable federated evaluation in which models are securely distributed to different facilities for evaluation, thereby empowering healthcare organizations to assess and verify the performance of AI models in an efficient and human-supervised process, while prioritizing privacy. We describe the current challenges healthcare and AI communities face, the need for an open platform, the design philosophy of MedPerf, its current implementation status, and our roadmap. We call for researchers and organizations to join us in creating the MedPerf open benchmarking platform.