 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Sustainable AI Economy Needs Data Deals That Work for Generators
Jan 15, 2026We argue that the machine learning value chain is structurally unsustainable due to an economic data processing inequality: each state in the data cycle from inputs to model weights to synthetic outputs refines technical signal but strips economic equity from data generators. We show, by analyzing seventy-three public data deals, that the majority of value accrues to aggregators, with documented creator royalties rounding to zero and widespread opacity of deal terms. This is not just an economic welfare concern: as data and its derivatives become economic assets, the feedback loop that sustains current learning algorithms is at risk. We identify three structural faults - missing provenance, asymmetric bargaining power, and non-dynamic pricing - as the operational machinery of this inequality. In our analysis, we trace these problems along the machine learning value chain and propose an Equitable Data-Value Exchange (EDVEX) Framework to enable a minimal market that benefits all participants. Finally, we outline research directions where our community can make concrete contributions to data deals and contextualize our position with related and orthogonal viewpoints.
Autoguided Online Data Curation for Diffusion Model Training
Sep 18, 2025The costs of generative model compute rekindled promises and hopes for efficient data curation. In this work, we investigate whether recently developed autoguidance and online data selection methods can improve the time and sample efficiency of training generative diffusion models. We integrate joint example selection (JEST) and autoguidance into a unified code base for fast ablation and benchmarking. We evaluate combinations of data curation on a controlled 2-D synthetic data generation task as well as (3x64x64)-D image generation. Our comparisons are made at equal wall-clock time and equal number of samples, explicitly accounting for the overhead of selection. Across experiments, autoguidance consistently improves sample quality and diversity. Early AJEST (applying selection only at the beginning of training) can match or modestly exceed autoguidance alone in data efficiency on both tasks. However, its time overhead and added complexity make autoguidance or uniform random data selection preferable in most situations. These findings suggest that while targeted online selection can yield efficiency gains in early training, robust sample quality improvements are primarily driven by autoguidance. We discuss limitations and scope, and outline when data selection may be beneficial.
Introducing v0.5 of the AI Safety Benchmark from MLCommons
Apr 18, 2024



This paper introduces v0.5 of the AI Safety Benchmark, which has been created by the MLCommons AI Safety Working Group. The AI Safety Benchmark has been designed to assess the safety risks of AI systems that use chat-tuned language models. We introduce a principled approach to specifying and constructing the benchmark, which for v0.5 covers only a single use case (an adult chatting to a general-purpose assistant in English), and a limited set of personas (i.e., typical users, malicious users, and vulnerable users). We created a new taxonomy of 13 hazard categories, of which 7 have tests in the v0.5 benchmark. We plan to release version 1.0 of the AI Safety Benchmark by the end of 2024. The v1.0 benchmark will provide meaningful insights into the safety of AI systems. However, the v0.5 benchmark should not be used to assess the safety of AI systems. We have sought to fully document the limitations, flaws, and challenges of v0.5. This release of v0.5 of the AI Safety Benchmark includes (1) a principled approach to specifying and constructing the benchmark, which comprises use cases, types of systems under test (SUTs), language and context, personas, tests, and test items; (2) a taxonomy of 13 hazard categories with definitions and subcategories; (3) tests for seven of the hazard categories, each comprising a unique set of test items, i.e., prompts. There are 43,090 test items in total, which we created with templates; (4) a grading system for AI systems against the benchmark; (5) an openly available platform, and downloadable tool, called ModelBench that can be used to evaluate the safety of AI systems on the benchmark; (6) an example evaluation report which benchmarks the performance of over a dozen openly available chat-tuned language models; (7) a test specification for the benchmark.
Croissant: A Metadata Format for ML-Ready Datasets
Mar 28, 2024Data is a critical resource for Machine Learning (ML), yet working with data remains a key friction point. This paper introduces Croissant, a metadata format for datasets that simplifies how data is used by ML tools and frameworks. Croissant makes datasets more discoverable, portable and interoperable, thereby addressing significant challenges in ML data management and responsible AI. Croissant is already supported by several popular dataset repositories, spanning hundreds of thousands of datasets, ready to be loaded into the most popular ML frameworks.
DMLR: Data-centric Machine Learning Research -- Past, Present and Future
Nov 21, 2023


Drawing from discussions at the inaugural DMLR workshop at ICML 2023 and meetings prior, in this report we outline the relevance of community engagement and infrastructure development for the creation of next-generation public datasets that will advance machine learning science. We chart a path forward as a collective effort to sustain the creation and maintenance of these datasets and methods towards positive scientific, societal and business impact.
Generative Fractional Diffusion Models
Oct 26, 2023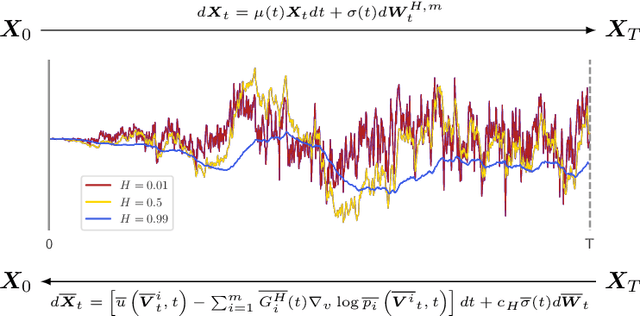

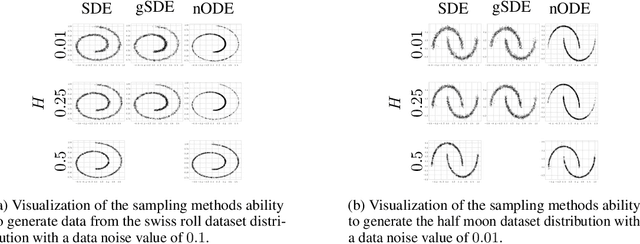

We generalize the continuous time framework for score-based generative models from an underlying Brownian motion (BM) to an approximation of fractional Brownian motion (FBM). We derive a continuous reparameterization trick and the reverse time model by representing FBM as a stochastic integral over a family of Ornstein-Uhlenbeck processes to define generative fractional diffusion models (GFDM) with driving noise converging to a non-Markovian process of infinite quadratic variation. The Hurst index $H\in(0,1)$ of FBM enables control of the roughness of the distribution transforming path. To the best of our knowledge, this is the first attempt to build a generative model upon a stochastic process with infinite quadratic variation.
Localized Data Work as a Precondition for Data-Centric ML: A Case Study of Full Lifecycle Crop Disease Identification in Ghana
Jul 04, 2023



The Ghana Cashew Disease Identification with Artificial Intelligence (CADI AI) project demonstrates the importance of sound data work as a precondition for the delivery of useful, localized datacentric solutions for public good tasks such as agricultural productivity and food security. Drone collected data and machine learning are utilized to determine crop stressors. Data, model and the final app are developed jointly and made available to local farmers via a desktop application.
DiffInfinite: Large Mask-Image Synthesis via Parallel Random Patch Diffusion in Histopathology
Jun 23, 2023



We present DiffInfinite, a hierarchical diffusion model that generates arbitrarily large histological images while preserving long-range correlation structural information. Our approach first generates synthetic segmentation masks, subsequently used as conditions for the high-fidelity generative diffusion process. The proposed sampling method can be scaled up to any desired image size while only requiring small patches for fast training. Moreover, it can be parallelized more efficiently than previous large-content generation methods while avoiding tiling artefacts. The training leverages classifier-free guidance to augment a small, sparsely annotated dataset with unlabelled data. Our method alleviates unique challenges in histopathological imaging practice: large-scale information, costly manual annotation, and protective data handling. The biological plausibility of DiffInfinite data is validated in a survey by ten experienced pathologists as well as a downstream segmentation task. Furthermore, the model scores strongly on anti-copying metrics which is beneficial for the protection of patient data.
Machine Learning for Health symposium 2022 -- Extended Abstract track
Nov 28, 2022A collection of the extended abstracts that were presented at the 2nd Machine Learning for Health symposium (ML4H 2022), which was held both virtually and in person on November 28, 2022, in New Orleans, Louisiana, USA. Machine Learning for Health (ML4H) is a longstanding venue for research into machine learning for health, including both theoretical works and applied works. ML4H 2022 featured two submission tracks: a proceedings track, which encompassed full-length submissions of technically mature and rigorous work, and an extended abstract track, which would accept less mature, but innovative research for discussion. All the manuscripts submitted to ML4H Symposium underwent a double-blind peer-review process. Extended abstracts included in this collection describe innovative machine learning research focused on relevant problems in health and biomedicine.
Data Models for Dataset Drift Controls in Machine Learning With Images
Nov 04, 2022



Camera images are ubiquitous in machine learning research. They also play a central role in the delivery of important services spanning medicine and environmental surveying. However, the application of machine learning models in these domains has been limited because of robustness concerns. A primary failure mode are performance drops due to differences between the training and deployment data. While there are methods to prospectively validate the robustness of machine learning models to such dataset drifts, existing approaches do not account for explicit models of the primary object of interest: the data. This makes it difficult to create physically faithful drift test cases or to provide specifications of data models that should be avoided when deploying a machine learning model. In this study, we demonstrate how these shortcomings can be overcome by pairing machine learning robustness validation with physical optics. We examine the role raw sensor data and differentiable data models can play in controlling performance risks related to image dataset drift. The findings are distilled into three applications. First, drift synthesis enables the controlled generation of physically faithful drift test cases. The experiments presented here show that the average decrease in model performance is ten to four times less severe than under post-hoc augmentation testing. Second, the gradient connection between task and data models allows for drift forensics that can be used to specify performance-sensitive data models which should be avoided during deployment of a machine learning model. Third, drift adjustment opens up the possibility for processing adjustments in the face of drift. This can lead to speed up and stabilization of classifier training at a margin of up to 20% in validation accuracy. A guide to access the open code and datasets is available at https://github.com/aiaudit-org/raw2logit.