 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeData Models for Dataset Drift Controls in Machine Learning With Images
Nov 04, 2022



Camera images are ubiquitous in machine learning research. They also play a central role in the delivery of important services spanning medicine and environmental surveying. However, the application of machine learning models in these domains has been limited because of robustness concerns. A primary failure mode are performance drops due to differences between the training and deployment data. While there are methods to prospectively validate the robustness of machine learning models to such dataset drifts, existing approaches do not account for explicit models of the primary object of interest: the data. This makes it difficult to create physically faithful drift test cases or to provide specifications of data models that should be avoided when deploying a machine learning model. In this study, we demonstrate how these shortcomings can be overcome by pairing machine learning robustness validation with physical optics. We examine the role raw sensor data and differentiable data models can play in controlling performance risks related to image dataset drift. The findings are distilled into three applications. First, drift synthesis enables the controlled generation of physically faithful drift test cases. The experiments presented here show that the average decrease in model performance is ten to four times less severe than under post-hoc augmentation testing. Second, the gradient connection between task and data models allows for drift forensics that can be used to specify performance-sensitive data models which should be avoided during deployment of a machine learning model. Third, drift adjustment opens up the possibility for processing adjustments in the face of drift. This can lead to speed up and stabilization of classifier training at a margin of up to 20% in validation accuracy. A guide to access the open code and datasets is available at https://github.com/aiaudit-org/raw2logit.
Post-Hoc Domain Adaptation via Guided Data Homogenization
Apr 08, 2021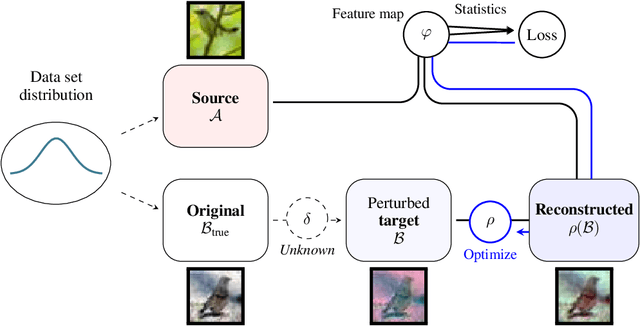
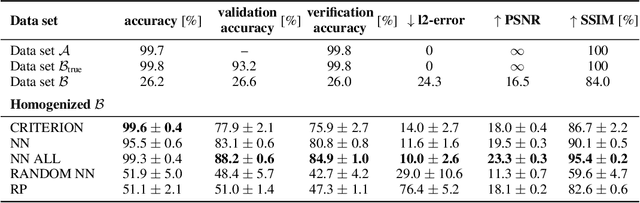

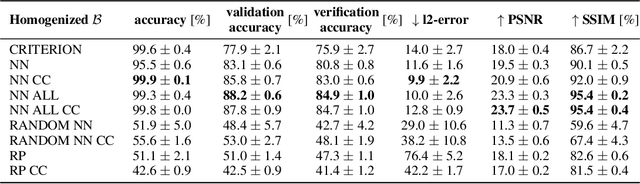
Addressing shifts in data distributions is an important prerequisite for the deployment of deep learning models to real-world settings. A general approach to this problem involves the adjustment of models to a new domain through transfer learning. However, in many cases, this is not applicable in a post-hoc manner to deployed models and further parameter adjustments jeopardize safety certifications that were established beforehand. In such a context, we propose to deal with changes in the data distribution via guided data homogenization which shifts the burden of adaptation from the model to the data. This approach makes use of information about the training data contained implicitly in the deep learning model to learn a domain transfer function. This allows for a targeted deployment of models to unknown scenarios without changing the model itself. We demonstrate the potential of data homogenization through experiments on the CIFAR-10 and MNIST data sets.