 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePost-Hoc Domain Adaptation via Guided Data Homogenization
Paper and Code
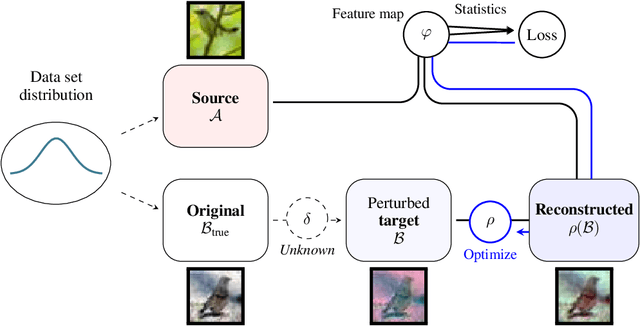
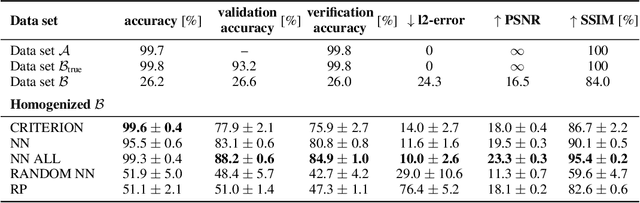

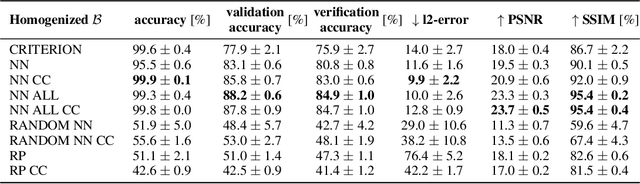
Addressing shifts in data distributions is an important prerequisite for the deployment of deep learning models to real-world settings. A general approach to this problem involves the adjustment of models to a new domain through transfer learning. However, in many cases, this is not applicable in a post-hoc manner to deployed models and further parameter adjustments jeopardize safety certifications that were established beforehand. In such a context, we propose to deal with changes in the data distribution via guided data homogenization which shifts the burden of adaptation from the model to the data. This approach makes use of information about the training data contained implicitly in the deep learning model to learn a domain transfer function. This allows for a targeted deployment of models to unknown scenarios without changing the model itself. We demonstrate the potential of data homogenization through experiments on the CIFAR-10 and MNIST data sets.